
Smart Data Extraction at a Glance
It’s surprising that an estimated 80% of data is trapped in unstructured documents. Smart Data Extraction is the key to accessing this wealth of knowledge that has the power to shape businesses.
This guide includes topics for developers, such as the challenges of data extraction and ways to overcome them, how smart data extraction works, key components to look for in a smart data extraction solution, and how to get started with smart data extraction. Decision makers will find topics such as the benefits of smart data extraction, real-world examples, vendor considerations, and an evaluation checklist.
Here, you’ll find an in-depth look at what you need to know about accessing the data trapped in your documents and how to get started with smart data extraction.

Introduction: Why Smart Data Extraction Matters
Smart Data Extraction is the core component of Intelligent Document Processing (IDP)—turning messy, unstructured documents into clean, labeled data that AI and automation can use.
The simple matter of fact is that even though data is a critical resource that drives businesses, an estimated 80% of global data is trapped in unstructured formats like PDFs, contracts, and invoices.
By the numbers:
- 2.5+ trillion PDFs are in circulation, much of their information inaccessible.
- $3 trillion annually is the estimated cost of incorrect or incomplete data to U.S. businesses.
- 10% is the average error rate for standard invoice processing, with error correction consuming 61% of the total processing cost.
As technologies like machine learning and large language models (LLMs) become mainstream, the demand for high-quality, structured data is at an all-time high. This is where smart data extraction shines.
This guide will explore what smart data extraction is, why it matters, and how to choose the right solution.
What is Smart Data Extraction? How Did It Evolve from OCR?
Intelligent Document Processing (IDP) represents the next evolution of OCR, advancing the field with AI to transform how enterprises turn unstructured documents into structured, usable data. For a deeper look at how modern extraction goes beyond traditional OCR, see Smart Data Extraction beyond OCR.
At its basic level, OCR focuses primarily on using pattern recognition to convert images of text into machine-readable text. While OCR is a crucial pre-processing step for data extraction, it's only the first part of the process.
As a core component of IDP, Smart Data Extraction turns messy, unstructured documents into clean, labeled data that AI and automation can use, building on this foundation by:
Interpreting Context and Meaning
It doesn't just recognize text; it understands the relationships between different pieces of information, such as identifying a value that corresponds to a specific label (a "key-value pair").
Integrating Machine Learning
It uses advanced ML algorithms to continuously learn from diverse document layouts, improving accuracy over time and handling exceptions that would confuse a rules-based system.
Processing Expanded Data Types
It can handle more than just text. Smart data extraction can identify and process tables, checkboxes, graphs, and other non-textual data from within a document.
Enabling Workflow Automation
It automates the categorization and output of structured data, typically in formats like JSON, which can be seamlessly integrated into business systems, databases, and AI models.
How to Overcome Data Extraction Challenges
PDFs are notoriously difficult to extract data from due to several factors:
BUILT FOR LAYOUT, NOT STRUCTURE
PDFs are designed to display information visually to humans, not to be easily parsed by computers. The underlying objects are often complex and lack a clear, logical structure.
VARIED LAYOUTS AND FORMATS
Even documents of the same type such as invoices from different vendors can have wildly different layouts, making a single, rigid template unusable. Format variability such as structured, semi-structured, and unstructured can present its own challenges when trying to extract data efficiently.
DIVERSE CREATION METHODS
Documents can be pristine digital PDFs, scanned images of paper documents, or hybrid formats.
MANUAL EFFORT IN TEMPLATE-BASED SYSTEMS
Manually processing forms is inefficient and error prone.
FRAGMENTED TOOLSETS AND MULTIPLE VENDORS
This can lead to data silos, inconsistencies, and the need for more complex integration.
PRIVACY AND SECURITY
Keeping data safe is crucial, especially when dealing with regulations such as GDPR and HIPAA. Sensitive data must be protected during all stages of data extraction to prevent unauthorized access, use, or disclosure.

Overcoming these hurdles can be a serious challenge for organizations.
A solution must be able to:
- Extract data in usable formats.
- Meet data privacy and security requirements.
- Minimize the need for manual configuration.
- Handle diverse styles and multi-page documents.
Benefits of Smart Data Extraction
Implementing smart data extraction is more than a technical upgrade; it's a strategic move that delivers significant, measurable benefits across the organization, including:
DRIVING DATA-DRIVEN DECISIONS
By unlocking data from documents, businesses gain access to real-time insights for faster reporting and analytics. This allows for seamless data integration across business systems, empowering smarter, more connected operations.
ACCELERATING DIGITAL TRANSFORMATION
Automating workflows reduces manual data entry, making for more efficient processes while enabling businesses to scale their efforts. Effectively gathering and organizing document data digitally reveals new capabilities for continuous process improvement and automation, laying the groundwork for a truly data-driven organization.
IMPROVING ACCURACY AND PERFORMANCE
Consistent, structured data from a variety of sources enhances the accuracy of downstream systems like analytics tools and AI models. This also strengthens compliance by ensuring all captured information is clean, structured, and traceable.
ENHANCING PRODUCTIVITY
Automating the tedious task of manual data entry allows employees to focus on strategic, high-value work while streamlined workflows handle higher volumes of documents faster. The benefits of this automation grow exponentially as more document workflows are integrated into the system.
How Smart Data Extraction Works
While the technology may seem complex, the process is streamlined and logical. Here is a typical workflow based on advanced extraction technology:


Step 1: Pre-Processing
The first step is to prepare the document for extraction. This may involve applying OCR and ICR to scanned documents, normalizing file types for consistency, and redacting any sensitive data to ensure privacy. This crucial stage lays the groundwork for accurate results.
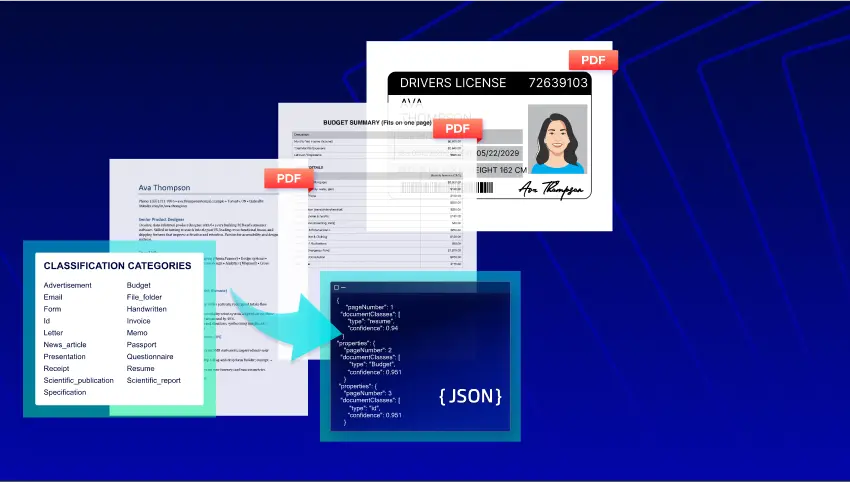






Key Capabilities to Look for in a Smart Data Extraction Solution
FULL-FIDELITY EXTRACTION
This capability ensures the solution extracts all data and metadata from a document, preserving the original structure of tables, paragraphs, and key-value pairs.
Developers: This means a reliable and complete output (like JSON) that's easy to work with.
Decision Makers: It guarantees data integrity and higher quality information for business analytics and automation.
SUPPORT FOR ALL DOCUMENT TYPES
A robust solution handles structured (forms), semi-structured (invoices), and unstructured (contracts, emails) documents.
Developers: This versatility allows developers to use a single tool for multiple use cases.
Decision Makers: Automation can be applied across the entire organization, reducing the need for multiple specialized systems.
TEMPLATE SUPPORT & ADAPTABILITY
The best solutions use a hybrid approach, offering templates for high-volume, standardized documents while using advanced AI to adapt to new or changing layouts.
Developers: This provides a fast, reliable starting point for developers.
Decision Makers: This ensures business continuity by reducing the need for constant maintenance and re-engineering when document formats change.
ADVANCED ML/AI
As the core of smart data extraction, advanced ML/AI enables context-aware extraction, allowing the system to understand the meaning of data, not just its location.
Developers: This enables the building of more accurate systems that handle "noisy" data.
Decision Makers: Get higher accuracy and a significant reduction in the manual effort needed to validate the data.
COLLABORATION, AUDIT TRAILS, AND COMPLIANCE
These features are crucial for enterprise adoption. Collaboration tools enable team-based workflows. Audit trails create a detailed record of every action, and provide the traceability needed for compliance with regulations like GDPR and HIPAA.
Developers: These features make it easier to build better workflows, perform debugging, and meet regulatory requirements.
Decision Makers: This means lower business risk and better accountability.
INTEGRATION FLEXIBILITY
The solution should offer comprehensive APIs and SDKs that allow the technology to be easily integrated into existing applications and workflows.
Developers: This means fewer potential issues implementing new solutions into existing systems.
Decision Makers: This allows for a faster time-to-market and a lower total cost of ownership by avoiding the need for extensive, custom development.
ENTERPRISE-GRADE PERFORMANCE & SCALABILITY
An enterprise-grade solution can handle high volumes of documents without performance degradation.
Developers: Constant overhauls are not required because the system can grow as the needs of the business grow.
Decision Makers: Better system reliability and availability ensures that mission-critical business processes are not interrupted.

Document Types
Selecting the right extraction technology requires an understanding of the documents you need to process. Solutions are often best suited for specific document types:
Structured Documents
Characteristics: Consistent layout and fixed format (for example, forms, surveys, payment slips).
Solution: Template-based extraction, where users define zones or coordinates for data fields.
Challenges: Creating a new template for every document type can be labor-intensive and difficult to manage as layouts change.
Semi-Structured Documents
Characteristics: Consistent data fields but variable layouts between senders (for example, invoices, purchase orders).
Solution: Requires a layout-aware tool that understands context, not just coordinates. Intelligent algorithms can identify key fields and tables across varied formats without relying on rigid templates.
Challenges: Template-based systems frequently fail with inconsistent formats, shifting fields, or non-standard terminology, leading to constant rule updates.
Unstructured Documents
Characteristics: Free-flowing, verbose content with information presented anywhere (for example, contracts, articles, memos).
Solution: The most challenging to process, requiring context-aware extraction that identifies and labels key elements such as headings, paragraphs, and entities. This relies on an understanding of context and semantics.
Challenges: Unlike forms or tables, these documents don’t follow predictable patterns, and simple keyword matching is insufficient.
Choosing a Vendor: What to Consider Before You Buy
When choosing an extraction solution, you're not just buying a product—you're entering a partnership. Consider the following vendor attributes for long-term success:
Reputation and Experience
Look for a vendor with a proven track record, experience, and a strong history of innovation.
Support and Responsiveness
Ensure the vendor provides comprehensive help resources, documentation, and live customer support.
Security and Compliance
A solution should prioritize data privacy and offer robust security measures, especially for regulated industries. Self-hosted, on-premises SDKs are ideal for maintaining full control over your data.
Scalability
The solution must be built to handle enterprise-scale workloads and deliver consistent performance, regardless of the volume of documents.
Flexibility and Integration
The solution should offer a robust suite of extraction methods such as forms, barcodes, OCR, tables, and more. It should also be easily integrated into your existing systems and workflows and be available in your programming language of choice.
Long-Term Roadmap
A good vendor is committed to continuous development and innovation, ensuring the solution remains relevant and future-proof.
The Apryse Advantage with Smart Data Extraction
PRIVACY-FIRST

Privacy-First
It’s a self-hosted SDK, so sensitive data never leaves your environment, which is crucial for regulated industries.
INTELLIGENT & FLEXIBLE
ALL-IN-ONE SOLUTION
DEVELOPER-FRIENDLY
SCALABLE & INTEGRATED
Real-World Examples
Smart data extraction is being used to revolutionize workflows across industries.
Healthcare
App developers can automatically extract data from patient intake forms and consent documents, speeding up EHR management, streamlining insurance claims, and enhancing clinical research while prioritizing patient privacy.
Finance
Companies can automate the extraction of data from bank statements and financial reports, accelerating fraud detection and ensuring compliance.
Customer Service
Aggregating and analyzing unstructured data from support tickets and customer emails can empower contact centers to quickly solve customer problems and improve satisfaction.
Business Intelligence & Analytics
Platforms can extract data from sources like social media and customer reviews to provide insights into market trends and customer sentiment.
Evaluation Checklist
Supports all document types
Can process PDFs, images, and various document formats with a single pipeline, reducing dev effort.
Enables automation across all business units (Finance, Legal, HR) regardless of document format, increasing efficiency.
Provides structured outputs like JSON
The API returns a predictable, machine-readable format with clear data fields and relationships, simplifying downstream automation.
Ensures data integrity and quality, providing a clean data feed for business intelligence tools and other systems.
Meets compliance standards
The SDK includes built-in security features, encryption, and audit trail APIs that help build compliant applications from the ground up.
Protects the company from legal and financial risks by ensuring data handling practices align with regulations like GDPR, HIPAA, or CCPA.
Scales to enterprise workloads
The solution offers reliable performance and can handle high-volume processing with auto-scaling, preventing system bottlenecks during peak demand.
Guarantees business continuity and reliability, allowing the company to grow operations without worrying about system limitations.
Developer-friendly integration
Offers comprehensive REST APIs and well-documented SDKs in multiple languages, accelerating development and reducing time-to-market.
Lowers the total cost of ownership by reducing development time and the need for specialized IT support.
Vendor reliability & roadmap
The provider has a clear, well-supported API, responsive support channels, and a public roadmap to help with long-term planning and implementation.
Assures a long-term, stable partnership and ensures the solution will continue to evolve with emerging technology and future business needs.
How Can Developers Get Started with Smart Data Extraction in Their Apps?
The Apryse Smart Data Extraction module is an add-on to Apryse SDK, which supports Windows and Linux on desktop and server platforms.
Step 1: Get to know the Smart Data Extraction module
Apryse’s Smart Data Extraction module transforms unstructured documents such as PDFs, scans, and DOCX files into structured, labeled JSON.
Learn more about smart data extraction in our documentation.
Step 2: Explore the demo
See our demo to try smart data extraction out for yourself.
Step 3: Integrate smart data extraction into your application
Follow the directions in our documentation to integrate smart data extraction into your application and start extracting your important data.
- Sign up for our developer portal and get your trial license key.
- Install and configure Apryse SDK.
- Download the Smart Data Extraction add-on module.
- Install the Smart Data Extraction add-on module.
- Contact our Sales Team or Discord with any questions.
FAQ
Smart data extraction is an advanced technology that goes beyond traditional OCR. While OCR converts images of text into machine-readable text, smart data extraction uses AI and machine learning to understand the context, meaning, and relationships between different pieces of information within a document. It can identify key-value pairs, tables, and other non-textual data, turning unstructured information into a structured, usable format like JSON.
Smart Data Extraction is the classification-and-extraction layer of an intelligent document processing (IDP) workflow—the stage that transforms unstructured documents into labeled, structured JSON. IDP refers to the broader end-to-end process of document ingestion,
classification, extraction, validation, and integration with downstream systems. Apryse Smart Data Extraction focuses on document understanding, classification, and structured data extraction rather than providing a complete end-to-end IDP platform. It was previously called Apryse IDP but was renamed to better reflect its role within the broader IDP ecosystem.
Yes. Use Smart Data Extraction for the classification and extraction stages, then compose the surrounding IDP workflow around it. For example, OCR/ICR during document preprocessing, optional redaction for privacy and compliance, and validation and integration with your downstream systems. Because Smart Data Extraction is a self-hosted SDK, document classification and extraction can run entirely within your own infrastructure, giving you full control over data residency while integrating with the tools and workflows you choose.
A robust smart data extraction solution can handle a wide variety of document types, including structured documents (forms), semi-structured documents (invoices, purchase orders), and unstructured documents (contracts, articles). Apryse Smart Data Extraction supports PDF (native and scanned), DOCX, TIFF, JPEG, and PNG as inputs. Outputs include JSON, XML, CSV/Excel.
Yes. The Apryse solution is a self-hosted SDK designed for developers. This means it can be integrated into existing applications and workflows and allows for a great deal of customization. Developers can use the comprehensive APIs and SDKs to build solutions tailored to their specific document types and data extraction requirements.
Yes. It includes a full suite of tools that can extract data from various elements within a document. This includes using OCR for text in images and specialized features for reading and extracting information from barcodes.
AI models, including large language models (LLMs), require high-quality, structured data for effective training. Smart data extraction automates the process of converting unstructured data from documents into a clean, organized format. This provides AI models with the high-quality input they need to learn more accurately and perform better, eliminating the need for manual, time-consuming data preparation. For more details on leveraging smart data extraction for AI development, read the full article here.
Data security is a critical consideration. The Apryse SDK is a self-hosted SDK. This means that sensitive data never has to leave your local environment, giving you complete control and ensuring compliance with regulations like GDPR and HIPAA. This minimizes the risk of unauthorized access and data breaches.
