Roger Dunham
Travis Montgomery
Senior Solutions Engineer
Published October 31, 2025
Updated June 15, 2026
8 min
Automatic Redaction of PII When Dealing with Freedom of Information Requests
Roger Dunham
Travis Montgomery
Senior Solutions Engineer
Summary: This blog explores how to use the Apryse SDK to automate redaction in response to FOIA requests. You'll learn how to detect and remove sensitive information like PII from PDFs using AI, sample code, and UI-based redaction tools—ensuring compliance while preserving transparency.
Introduction
Freedom of Information Act (FOIA) requests are designed to make government records accessible, but not every piece of information inside those records can, or should, be released. Sensitive details such as personal identifiers, national security information, or privileged communications are often embedded directly within PDFs that agencies provide. That’s where redaction becomes essential.
Redaction isn’t just about hiding text; it’s about permanently removing protected data while still delivering the rest of the document intact. Without it, agencies risk exposing private information, violating compliance requirements, or undermining public trust. For organizations responding to FOIA requests, effective redaction ensures the balance between transparency and privacy: citizens gain access to the information they’re entitled to, while sensitive content stays securely out of sight.
In this article, we will see how we can use the Apryse SDK to search through PDFs for content that needs to be removed, then automatically redact it.
We are going to cover:
- What is the Apryse SDK?
- The initial sample code
- The Importance of manually reviewing redactions
- Dealing with PII in images
- Using AI to find PII
- Can Redactions be applied directly from a UI?
What is the Apryse SDK?
The Apryse Software Development Kit provides a powerful set of APIs to handle PDFs, DOCX files, Spreadsheets, CAD drawings, DICOM images, and more.
It allows you to develop complex document workflows, for example creating a document using a template and data, then converting it to a PDF, then collaboratively editing that PDF before adding digital signatures, and finally making an accessible, archivable document. And that is just one of the potential workflows.
It's available for use with a wide range of programming languages and ships with a wide range of sample code and test files to allow you to quickly get started using the SDK.
In this article, we will start with one of the samples that is shipped with the SDK, then extend it to apply redactions to a PDF.
For this article, we will be using C#, but the Apryse SDK can be used with many other languages as well, including C++, Java, and Node.JS. I will also be using version 11.7 of the SDK and Windows 11. You should get similar results on macOS and Linux.
I’m assuming that you have already downloaded the Apryse SDK and have the samples running. If you haven’t, then check out the getting started guide.
The initial sample code
The Apryse SDK ships with the HighlightsTest that uses search functionality to find the location of words and creates a highlight annotation each time that the word “Federal” is found.

Figure 1: The result of running the Highlights Test sample - the word 'Federal' has been found and highlighted.
That’s clever in itself. But in this article, we will significantly extend the code, to find multiple search terms, and redact them, rather than highlight them.
I won’t go through all of the code here. You can download the sample code to see for yourself. The function doing most of the work is SearchAndRedact (There are also two overloads that allow you to use default options, but they then pass those arguments to this function).
The essential parts of the code are
- A PDFDoc is created from the original PDF.
- A TextSearch is created for each item in the collection of Search Items. These can be a word, a group of words or a Regex. In this case, we are including TextSearch.SearchMode.e_highlight, which means that we will get location information when a match is found as a “highlight”.
- TextSearch.Run is called iteratively until no more matches are found. If a match is found, then the return code will be TextSearch.ResultCode.e_found.
- If a match is found, then the location of the highlight is extracted. Typically, there will be 8 “quads” which, between them, mark the various corners of the highlight. However, if the result was split over a line break, then there may be multiple sets of quads for a single highlight.
- If we wanted, we could use these coordinates to add highlight annotations to the PDF (and the “Highlights Test” sample, mentioned earlier, does exactly that). In this case though, we will use that information to create a redaction object for each set of quads, the page on which it was found, and potentially any overlayText (for example “FOIA”).
- Finally, once all of the Search Items have been processed, the redactions are “applied”. The search item isn’t just obscured, it is completely, and permanently, removed from the PDF.
Phew that’s a lot of work! Thank goodness that the code does it for you.
Let’s run that code with one of the sample files that ships with the SDK (which I have included in the GitHub sample).

Figure 2: Page 2 of the sample document.
The document contains information relating to a conference on Robin Hood. It also has various phone numbers, email addresses and URLs.
While this is a publicly available PDF, let’s use it as a way to demonstrate redaction. You could of course run the sample with your own documents.
Let’s find and redact the phone numbers, email addresses, URLs and the words "Robin Hood”.

Figure 3: A zoomed in area of part of the sample PDF. There are phone numbers, email addresses, and the words 'Robin Hood" including where the name is split over two lines.
We need to set up the code to know what to search for (you could create an app that allows you to do that interactively, but for now we will hard code it).
We’ll use a mixture of Text and Regex.
Now we just need to pass the list of search items to the function that we saw earlier and run the program. We are also going to specify that we want the redactions to be black and to have “FOIA” in red written on them.

Figure 4: The result of automated search and redaction.
That’s a great result. It found all the text I had marked that needed to be redacted, including search items that were split over a line break. In fact, it did better than I did manually, it found a piece of PII that I had missed – an extension telephone number.
The Importance of Manually Reviewing Redactions
So far, we have entirely automated the process, but you could just use the Apryse SDK to identify potential text for redaction, then allow the user to manually verify them before applying them.
In order to do that, we need to create Redaction Annotations, rather than creating Redaction objects directly.
In this case, there is no need to call Redactor.Redact(doc, redactions, appearance), which is responsible for applying the redactions.
We can then save the Document and open it in Apryse WebViewer (You will need to set full API and enableRedactions to true in the constructor). Now it’s possible to see what has been marked for redaction, and either apply all of the redactions, remove potential redactions before the rest are applied, or even just apply individual ones.
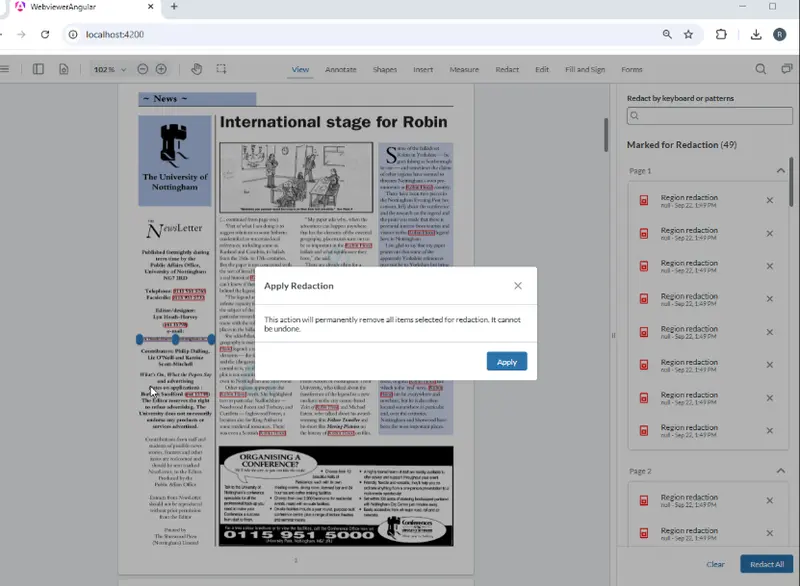
Figure 5: Our PDF within Apryse WebViewer - the user can now review what should be removed before applying the redactions.
Dealing with PII in images
Sometimes of course, there can be an issue with information that needs to be redacted being present in an image. An extreme case would be a password that is on a Post-it note in an image.
In our example document though, there are a number of images that contain adverts. And some of these contain phone numbers, which is one of the things that we want to redact.

Figure 6: A possible gotcha is if there is PII within an image. Apryse has an OCR option that can be used to extract the text.
Apryse has a solution which is a natural extension of what we have been doing, the optional Apryse OCR/ICR module.
Once that module is in place, you can use the OCR sample code to add a searchable text layer to the PDF. I won’t include the code for that, but you can find sample OCR code in the Apryse SDK Samples.
Now we can redact the modified document including things that are detected within the image.
To make it more fun, we will also redact the word “conference”. That’s easy to do, we just need to change our code slightly so that it includes that word in the list of things to search for.
Now the telephone number and most of the occurrences of the word “conference” have been redacted as well.

Figure 7: Having created a text layer in the PDF, it is now possible to search for PII and redact it, even if it is an image.
Note though, that there is the unredacted word “Conferences” at the bottom right of the page. This is an example of OCR being imperfect – the font is unusual enough to have not been correctly identified. This is of course, a contrived example with a very unusual font, but if you need to, though, then it is easy to manually redact that word using either Apryse WebViewer or Xodo PDF Studio.
Using AI to find PII
With the rapid development of AI, you may wish to use that to identify the location of PII or other text that needs to be redacted from a document. As long as the AI returns the location of the text that needs to be removed, the code sample can be easily modified to work with that, rather than using the built in Search capabilities to identify problem text.
That’s awesome. As technology changes over time, you can continue to rely on the Apryse SDK to do the server-side processing of PDFs and other documents, while not being locked into a specific search mechanism.
Can Redactions be applied directly from a UI?
Absolutely! Apryse WebViewer provides a mechanism where you can search and redact the contents of PDFs directly within the browser. Depending on your business requirements, that might be a good solution for you. It also has the benefit that the redaction occurs entirely within your browser with no need for the documents to be sent to a server for processing or even downloaded onto your local machine. You can check that out for yourself, right now, with the redaction demo in the WebViewer Showcase.
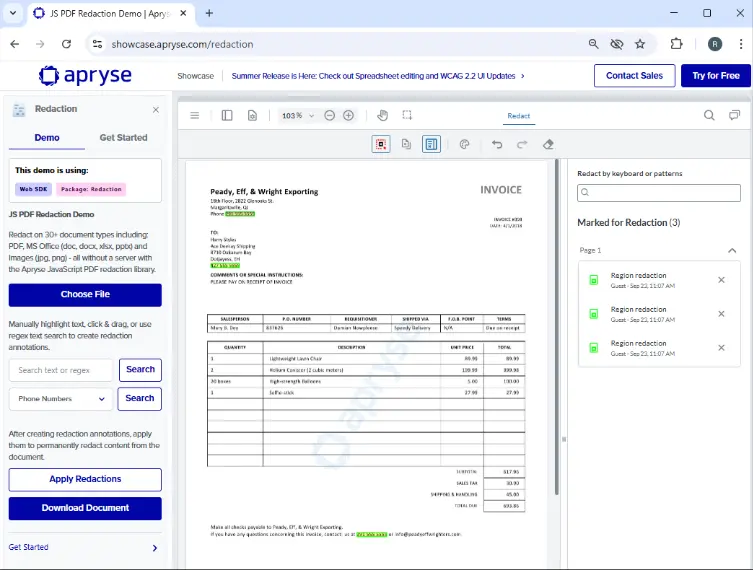
Figure 8: The redaction demo in the Apryse Showcase, showing how you can interactively search for text in a PDF.
Where next?
There is nothing like trying things out for yourself, so when you are ready to get started, get a trial license key and try downloading the code from the GitHub sample. There’s much more that you can do with the Apryse SDK, so check that out too, and lots of documentation to help you get started quickly.
There’s also a support channel if you have any questions.