Adam Pez
Published June 14, 2019
Updated May 18, 2026
6 min
How to Open 1GB+ PDFs in a Mobile or Browser App
Adam Pez

Having the option to render documents client-side has many pluses: it’s simpler and more secure than relying on server-side rendering, it scales better, and it opens the door to superior local and offline access.
Unfortunately, many mobile document and web-compiled PDF libraries just aren’t up to the task of reliably rendering your 1GB+ documents client side. Common issues include long load times lasting minutes and even hours, uneven scrolling and zooming, and browser page crashes.
In this blog post, we’ll show you how you can get the big PDFs to render in a browser or mobile app as quickly and reliably as on native desktop.
With Apryse, it’s possible to achieve near instant viewing and smooth interaction with 1GB+ documents. In fact, here’s a sample 2GB document download link you can use to compare the performance of different web & mobile viewers, such as your own, or the Apryse WebViewer client-side demo.
Apryse SDK filmed opening 2GB PDF Files on browsers (via broadband) and on Android (via 4G).
TL;DR — You can embed the same powerful document viewing and annotation into your software today by downloading your free Apryse trial. Afterward, just click the instructions on how to implement fast remote, online viewing of large documents.
The Cause of Inferior Browser/Mobile Performance
On mobile and browser — and especially on a mobile browser — you are simply working with less resources: namely, less memory. And your client-side document viewing software may not be set up to manage the memory requirements of your larger documents. (These documents don’t necessarily have to be long with lots of pages; they may simply be complex: e.g., an intricate engineering blueprint or a map with many layers.)
Memory Issues Explained
On a native mobile app, dealing with the memory issue is more straightforward. You can at least cache the PDF document on disk. This doesn’t necessarily solve performance issues like uneven scrolling and zooming; but it helps ensure the solution can work without crashing as you’ve got a large, stable repository.
Browsers, however, have even less to work with, and can’t cache PDF data to disk.
First, browser-based PDF libraries are converted from a low-level language, usually C/C++, into WebAssembly or JavaScript. But due to the design of WebAssembly and JavaScript (which both work asynchronously) browser viewers can’t cache binary PDF content to disk (as such information is read serially off disk by the system toolkit). Instead, the web viewer must load PDF data into a JavaScript object like an ArrayBuffer, stored purely in RAM.
Another issue is that as Mozilla writes, browser “quota clients” including the array buffer are capped in order to protect the client system. These local memory limits vary with the browser in question, but for each second-level domain group, there is a hard limit of between 10MB to 2GB.
Lastly, most PDF libraries have difficulty splitting up PDF content into bite-sized increments — unlike audio and video streamed online. This is due to the way many PDFs and PDF libraries are structured. With “non-linearized” documents, resources for a given page are often scattered across the file, thereby forcing a PDF viewer to download the complete document before it will open.
The end result? A viewer tool may try to load your entire large PDF document into the buffer array. And after a potentially aggravating download delay, the document exceeds its allowed memory, crashing or freezing the browser page, and exiting the user.
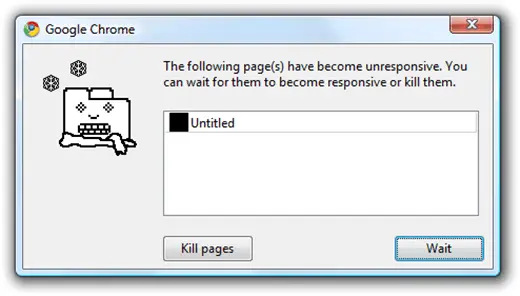
How Solutions Commonly Solve Client-side Memory Problems
Many PDF SDK vendors “solve” client-side memory issues by recommending that customers break up or otherwise shrink large and complex documents. This can be achieved with our SDK’s page and document manipulation features, and through a technique known as “flattening,” which involves tradeoffs between performance and appearance.
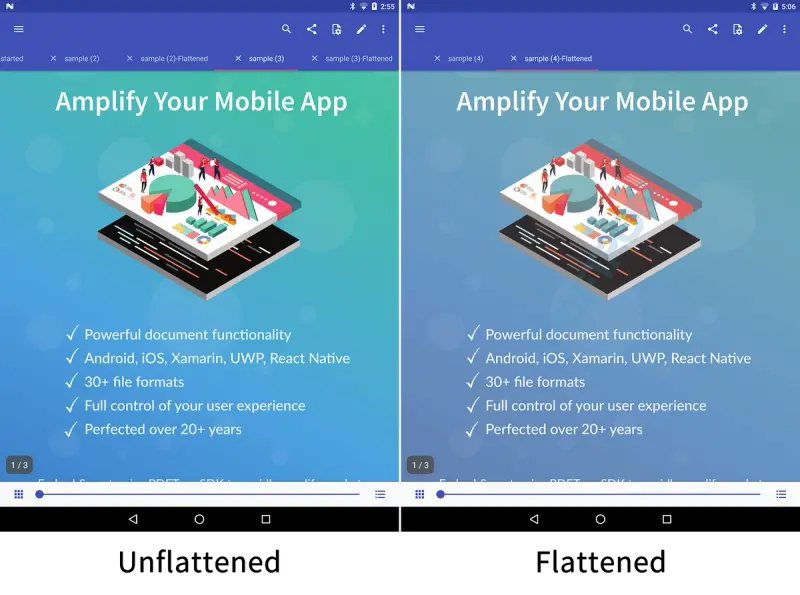
How flattening a PDF document impacts image quality
A parallel approach is to introduce a server to control the entire workflow. This is often used to spoon-feed pre-rendered pages down to the client as a web format like PNG, with an HTML text overlay.
Server Rendering: Pros and Cons
There are advantages to server-side as opposed to client-side rendering. The vendor has more control. They can add new features without slowing down the user experience as you needn’t get an entire PDF toolkit running in the browser. It also leads to what may seem like better performance with smaller documents.
Some amount of server rendering may be necessary for the best experience. For example, we use server acceleration with some of our customers.
Apryse’s WebViewer may use a server when the document first loads to deliver an instant preview of pages via compact thumbnail images while the toolkit downloads. After this initial burst of activity, however, the client-side viewer simply downloads static PDF bytes from the server and renders them client-side. The result is that WebViewer scales naturally as you add users and documents.
But solutions that rely on a server to render entire PDFs don’t scale nearly as well with large documents, as this requires constant re-rendering and transfer of high-resolution images. Lots of users concurrently interacting with the same very large document accelerates the consumption of server CPU and RAM, as well as network bandwidth.
When to Use Server Rendering
And then there are situations where a server may not work or may work poorly. For example: where there are data jurisdiction and compliance considerations, where users otherwise work with a lot of locally generated and accessed files, where they require offline rendering, or where they routinely access documents via external website links. In the latter situation, server rendering would add further delays (uploading, converting and re-downloading) which you’ll want to minimize with a document that takes many minutes to load.
How Apryse Delivers Improved Client-side Rendering
At Apryse, we deliver fast, reliable client-side performance primarily via two strategies:
- PDF Linearization and On-demand Streaming
- Local Cache Management
This is on top of other techniques, such as PDF tiling and multi-scale image processing.
By “streaming” linearized PDF content into a client, we’ve shown to reduce large document open times to 7 seconds on average when using a 4G network, leading to a faster online experience overall even with the largest document file-sizes. The same methods also allow for much more efficient methods of client-side memory management.
Linearized vs. non-linearized PDFs opening on an Android Device using a 4G network
Byte-serving Linearized PDF Content
PDF “Fast Web View” or Linearization can be performed upon file generation, including with the cross-platform Apryse SDK.
For this article, it’s sufficient to say that linearization reorganizes a PDF’s internal structure so it can be broken up and served in pieces on demand in a similar fashion to audio and video streamed online by web services. Streaming is achieved via another technique known as “byte-serving”.
(You can read more on PDF linearization, and learn how to stream PDFs with Apryse SDK.)
Local Cache Management
Once document content for the first page and “hint tables” are downloaded by the client, the document will open, usually within seconds, assuming the first page is not too large or complex.
On mobile, partial information is then cached in temporary, pre-allocated disk memory. Remaining pages then download and render based on how the user navigates. When the user advances, obsolete pages can be flushed from working memory to maintain smooth performance. (These pages can always be quickly loaded up again from disk.)
Apryse WebViewer deploys a similar method: the PDF is downloaded into the browser buffer array piece by piece, with requested pages downloaded and rendered first. The buffer gradually fills up as pages load. But because linearized content is served as small fragments, WebViewer can intelligently clear old content to ensure it always stays within quota, even when file-sizes are huge and the browser is limited to the 10MB lower bound.
Lastly, with Apryse SDK, it is also easy to configure the viewer to only download those pages that the user wants to view. This is critical when serving 1GB+ files to mobile devices with limited or costly data plans, and beneficial even when serving 20MB+ files.
Wrapping up — Supported Platforms
The client-side solution delineated above will work great with our cross-platform SDK across modern browsers (especially Firefox, Edge and Chrome) and on each major mobile platform.
In many cases, however, users will generate PDFs on their local machine using third party software (e.g., Adobe) or use PDFs downloaded from external websites. These arbitrary PDFs produced “in the wild” may not be linearized and thus may not open as quickly. In some cases, users will also want to work in older browsers (e.g., IE 9) where performance will not be as good.
In these situations, you may want to consider a hybrid solution, such as our hybrid WebViewer, which includes client-side rendering and server-side conversion.
If you have any questions or comments about our PDF SDK or this article, don’t hesitate to get in touch.