Server SDK:
PDF Sanitization: Share PDFs with Confidence
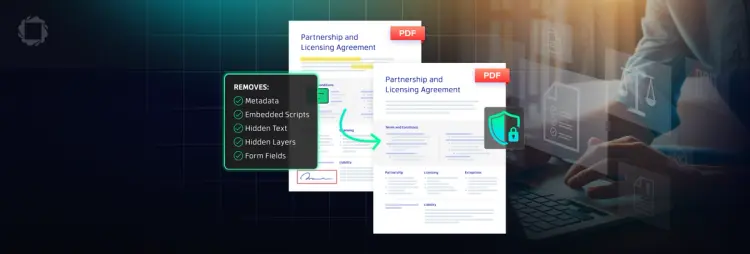
PDFs carry more than their visible content. The Apryse Sanitization API removes hidden metadata, embedded scripts, and sensitive data before documents leave your environment, giving compliance-driven teams a clean, auditable path to secure sharing.

Secure Sharing Starts with Certainty
Add an automated security layer to document workflows by programmatically scrubbing a PDF’s internal structure, including hidden, malicious and sensitive metadata and layers. Meet compliance requirements without manual review.






Auto-tagging Use Cases

Regulatory Documents
Strip metadata, hidden layers, and scripts before submitting documents through official channels. Sanitization is often a hard compliance requirement, not a best practice.

Secure Legal Sharing
Documents that pass through multiple hands including doctors, insurers, and regulators can surface privileged information or PHI. Sanitize before every handoff.

Inbound Document Hygiene
PDFs arriving from external sources are an active attack vector. Sanitize on ingestion to neutralize embedded scripts before files touch internal systems.
PDF SANITIZATION FAQS
The API covers metadata and document properties, embedded JavaScript, hidden text and layers, markup annotations and comments, overlapping content, embedded files and attachments, and form field data.
You have full control. GetSanitizableContent() returns a report of everything found, and you specify which categories to remove before calling SanitizeDocument(). You can sanitize everything or target specific element types.
Redaction removes or obscures visible content, including specific text, images, or regions a reader can see. Sanitization targets hidden content that doesn't appear in the normal document view but is still present in the file structure. Both are often required; they solve different problems.
No. Sanitization targets hidden and non-visible elements only. Page content, text, images, and layout remain intact.