Isaac Maw
Technical Content Creator
John Chow
Product Manager
Published November 19, 2025
Updated May 18, 2026
5 min
Putting Apryse Smart Data Extraction to Work with JSON
Isaac Maw
Technical Content Creator
John Chow
Product Manager
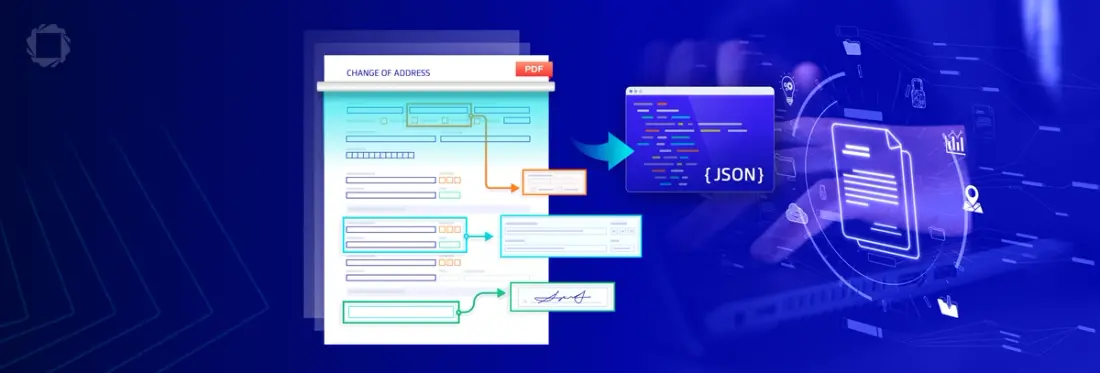
Summary: our Smart Data Extraction SDK offers a set of capabilities to intelligently detect and extract valuable data from unstructured documents, from receipts to contracts. This article overviews two popular use cases, and all that Smart Data Extraction has to offer.
This article was originally published February 2023. It has been updated to include new information as of November 2025.
Apryse’s Smart Data Extraction module transforms unstructured PDFs, scans, and DOCX files into structured, labeled JSON, built for downstream AI, analytics, or automation. Designed for developers, it offers SDK-first deployment across Windows and Linux, ensuring maximum privacy, flexibility, and control.
In this article, we’ll take a tour of two popular use cases for Smart Data Extraction:
- Automated Data Labelling
- Automated Data Intake
In automated data labeling, Smart Data Extraction identifies and tags relevant sections of PDF documents, such as body text of news articles, and store the tagged and organized data in JSON format, ready and readable for LLM training.
In automated data intake, Smart Data Extraction handles intake of a large and diverse set of documents, and intelligently identifies important information for extraction, such as key-value pairs. This eliminates time-consuming manual data entry, and error-prone templating.
Read on to find out more about these valuable applications of our Smart Data Extraction technology.
Are you ready to try new features in your environment? Visit the documentation — no trial key required to get started. Learn more about Smart Data Extraction.
Why Convert PDF to JSON?
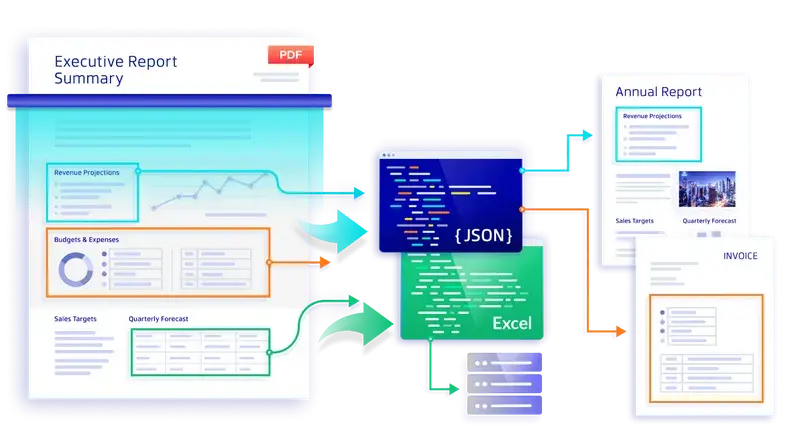
Apryse Smart Data Extraction identifies the logical order of a specified PDF and outputs a JSON file that mirrors this order. Critically, the JSON copy captures the context of the data. Rather than just a raw data export, it captures the relationship and structure of content elements. Under the hood, a PDF isn’t designed to do that.
The JSON file identifies text blocks and their dimensions and regions. For example, you can quickly identify relevant paragraphs by performing programmatic word count on text in the JSON. You can also find the coordinates of a table in the file for easy retrieval and verification.
A well-structured JSON is your ally for automating document processes, as it lets you rebuild PDF content into a dataset — a format that programs easily understand, manipulate, and leverage at scale. Thus, data previously trapped in thousands of scanned or native PDFs becomes available to your organization in many ways. For example, you can feed JSON data into a dashboard, a report, an analytics tool, and more.
To recap, Smart Data Extraction enables the following:
- Text extraction: Smart Data Extraction looks for textual content, sentences, and paragraphs, finding all passages longer than a specified number of words long, for example. The component then pulls out those regions from the JSON file.
- Tabular extraction: The tool identifies table cells, columns, rows, and spanning cells. You can pull tables out from the JSON document, or extract to Excel if you want only tabular data in spreadsheets.
As a bonus, the structured data is available to your organization without the need for upfront templating or training, constant maintenance of templates, or manual repair of extracted data. Now let’s look at a couple of specific use cases of these extraction features and JSON in a few industries.
1. Automated Data Labelling: Build AI Training Datasets without Manual Data Entry
LLMs and AI agents depend on quality training data. Historically, these large datasets have been prepared by human workers, manually tagging relevant sections of texts and documents.
Sentiment analysis studies the subjective information in an expression: the opinion, emotion, or attitude toward something, such as a topic, person, object, or entity. With the help of sentiment analysis, data analysts can get information about how businesses and companies are perceived by consumers.
Expressions can be tagged as positive, neutral, or negative. For example:
“I like your new product.” Positive.
“I investigated a trial license.” Neutral.
“I don’t understand the point of the new product.” Negative.
The Weak Link in Data Labeling: Humans
To create a training dataset for NLP (natural language processing) or sentiment analysis, you must first choose relevant chunks of text or tag text with labels.
Machine learning models should use only high-quality, reliable data. But a heavy human component in the labelling process represents a weak link, which consumes most of the AI team project time. As a result, teams spend considerable resources developing custom solutions to process text, and many teams still tag text manually. Here’s a real-world example: One company currently uses college students to manually clip out articles and scan them for media monitoring, outsourcing the labelling process.
Using Apryse Server SDK and Smart Data Extraction, however, this company can automate detection of news articles in scanned PDFs, label them, and then store extracted text. This approach significantly reduces errors and eliminates manual processing.
Out of the box, Smart Data Extraction reconstructs article structure into JSON. And with document structure, such as headlines, bylines, images, captions, advertisements, and article paragraphs available programmatically, you can quickly segment content, and have your AI do the sentiment analysis or other NLP applications on relevant text.
2. Automated Intake: Turn Documents into Data
Apryse Smart Data Extraction can also be applied to any form of intake process or existing repository to turn your documents into data at scale. Think of PDF documents in your CRM storage, and especially those that are only images of documents, such as scanned or photographed contracts with hand-drawn signatures.
Let's look at some examples: Say your accounting or financial organization has vast numbers of invoices (various layout styles), scanned receipts (images saved to PDF), or even native, editable PDF documents — all of which need data extraction, processing, and classification. Or, say you’re processing medical intake forms, collecting patient history, past surgeries, symptoms, and so on.
Manual data entry for these forms cannot scale; it takes up to several minutes per form. It's also error prone. Thus, it becomes hard to keep up with the influx, let alone take on new business or patients.
However, despite the costs, many organizations continue with manual intake because it's familiar — and automated alternatives that are reliable and accurate aren't common.
What about templating? Creating and maintaining a comprehensive library of templates and rules isn't cost-effective, because developers are scarce and costly resources. Also, templates are seldom bullet-proof because intake forms come in all shapes and sizes and customers often change them.
If you do process identical forms at a high volume, such as ACORD forms in insurance, check out Apryse Template Extraction.
Your staff — or expensive consultants — find themselves constantly catching exceptions, changing settings, and adjusting templates instead of focusing on the business.
Again, this is where Apryse Smart Data Extraction comes in: it leaps past manual processes and template-driven extraction. Instead, it automatically detects and extracts specific PDF data, one PDF at a time or in batch mode.
This automation is a boon to any accounting, insurance, or healthcare organization. It improves extraction accuracy, opens new data sources for business insights, and significantly reduces the workload so staff focuses on business-critical activities.
Learn how Smart Data Extraction boosts efficiency and compliance in the finance sector. Read the blog.
What’s Included in Smart Data Extraction?
We’ve been developing more and more innovative capabilities for Smart Data Extraction over the past 6 quarterly releases. It’s designed to handle all your unstructured documents.
Document Pre-Processing
Normalizes input files —deskewing, rotating, handling multi-column layouts— and prepares content for structured extraction—before the AI steps in.
Document Classification
Automatically identify document type across 19 supported categories: such as invoices, receipts, IDs, contracts, and memos. Each page is labeled with a type and confidence score, so teams can route documents into the right workflow, whether that means extraction, review, or other internal processes.
Key-Value Extraction
Identify fields like “Invoice #” or “Patient Name” from unstructured or scanned documents.
Table Recognition
Parse rows, merged cells, and numeric data from complex, layout-heavy tables.
Full Document Element Extraction
Extract core components from PDFs—including text, images, fonts, layers, signatures, form fields, annotations, and metadata—so nothing gets lost in translation.
CAD Title Block Extraction
Automated extraction of CAD Title Blocks scans and captures information like drawing numbers and revision dates from PDF files which increases efficiency, improves accuracy, and enhances data availability for downstream workflows.
Document Structure & Form Field Detection
Understand document hierarchy (headings, paragraphs, lists) and spot visual markers like checkboxes and labels.
Deploy Anywhere
SDK-based deployment. Works offline, on-prem, hybrid, or air-gapped. Compatible with Java, .NET, C++, Python
What’s Next?
Apryse Smart Data Extraction enables efficient and accurate PDF content extraction without the need for extensive upfront training or templates.
In this article, we just scratched surface with two examples. Other uses abound such as content republishing, when you want to reconstruct PDFs or parts of them somewhere else. For example:
- Automatically turning restaurant menu PDFs into an app-friendly layout for mobile devices.
- Digitizing archived printed media into web or mobile app content.
- Digitizing forms into an app experience and/or auto-filling forms from a database.
We’d love to see what you create using Apryse Smart Data Extraction. If you have any issues or questions during your free trial, don’t hesitate to drop us a line or leave us a note. Use our free trial support to talk to an engineer.
When you’re ready to add Smart Data Extraction and intelligent data extraction to your existing Apryse Server SDK license, contact Sales.


