Home
All Blogs
Don’t “Dig for Data” — Automate Accurate Data Extraction from PDF with Apryse Smart Data Extraction
Isaac Maw
Technical Content Creator
John Chow
Product Manager
Valerie Yates
Sr. Content Strategist
Published February 17, 2023
Updated November 05, 2025
6 min
Don’t “Dig for Data” — Automate Accurate Data Extraction from PDF with Apryse Smart Data Extraction
Isaac Maw
Technical Content Creator
John Chow
Product Manager
Valerie Yates
Sr. Content Strategist
Related Products
Summary: Smart Data Extraction is built to pull valuable JSON data out of your unstructured PDF documents, including contracts, forms, invoices and more. Whether you're powering a search feature, pre-processing data for a Small Language Model (SLM), or automating regulated workflows, Apryse gives you precision from page one.
This article has been updated November 2025 to include the latest updates and improvements.
As machine learning, LLMs and process automation become more widespread and more complex, structured and high-quality data is essential. Your processes are powered by the data trapped in PDF documents, in forms, notes, invoices, contracts and technical drawings. Our Smart Data Extraction SDK is designed to unlock and organize your document data, enabling document search, automated workflows, and AI-driven insights.
Apryse Smart Data Extraction includes powerful PDF data extraction that recognizes and extracts any document layout along with content elements, such as tabular data and text, to structured JSON and Excel right out of the box. As a result, it gives organizations scalability and leading accuracy in PDF data extractions — it eliminates costs associated with extensive templating, rules, and data entry.
On this page:
- Secure, Fast Setup
- Key Features
- Document Pre-Processing
- Document Classification
- Key-Value Extraction
- Table Recogntion
- Full Document Element Extraction
- Document Structure and Form Field Detection
- Deploy Anywhere
What Does Apryse Smart Data Extraction with Intelligent PDF Data Extraction Look Like?
PDF data extraction presents challenges because PDFs are designed to transfer information, such as natural reading order, to humans, not machines. Under the hood, a PDF file is composed of Cos objects and isn’t WYSIWYG. A reader application parses the PDF file — and after extraction of the objects, an output file may not be in reading order or even resemble the original human-intended PDF.
Interested in LLM Training Data? Read Leveling Up Your LLM with Retrieval-Augmented Generation
As a result, conventional extractors require extensive upfront work: templating, data entry, or training documents to infer logical structures from PDF and to get meaningful data out. Additionally, semi-structured PDF content is highly variable, meaning it’s time-consuming and costly for developer staff to create customized templates to prepare the extractor for every possible document type. These factors make it difficult for organizations to automate their PDF data processing at scale.
But what if PDF data extraction worked right out of the box instead — without training the model on every type of document used across your organization, without creating rules, or having to check for errors post-conversion? Apryse Smart Data Extraction does just that for any structured or semi-structured data in PDF while offering different conversion formats for processing options. It reliably recognizes tables, accurately extracts text and tabular data, and detects and understands articles of text in a document.
Visit the documentation to learn more about Apryse Smart Data Extraction and what it can do in your environment. There's no trial key required to get started.
Secure, Fast Setup
Getting set up is straightforward. New Intelligent Data Extraction features are part of the Smart Data Extraction add-on to the Apryse Server SDK, meaning you can use your language of choice to embed the API into your application. Developers get complete control over extracted data and the workflow itself. Apryse Smart Data Extraction provides greater reliability, performance, and cost-effective scalability compared to external extraction services and on-demand processing.
The Server SDK Get Started Guide in our Docs is a great place to start!
From Chaos to Clarity: Structured Data Starts Here
Let’s take a look at all the features of Smart Data Extraction to understand how the SDK handles all the types of unstructured PDF documents you can throw at it.
- No rules or templates: Avoids extensive upfront work associated with templating and drives accuracy and cost-effective scalability.
- Handles multi-modal content: Text, tables, and forms, including fields in informal forms, such as scanned PDFs or forms specified in text without interactive form data in the file.
- Layout awareness: Preserves natural reading order, logical relationships between elements, and contiguous blocks of text in JSON, for error-free extraction.
- Conversion to different file formats: JSON and Excel allow flexible data consumption.
- Table and cell recognition: Extracts tabular data into Excel, enabling easy analysis or further processing. Provides coordinates to tables in the JSON.
- Much more: at the time of this writing, we’ve spent six consecutive quarters innovating to improve our Server SDK and Smart Data Extraction add-on. This article has been updated to include the most current features.
Document Pre-Processing
First, Smart Data Extraction normalizes input files, including deskewing, rotating, handling multi-column layouts. This step prepares content for structured extraction and improves accuracy before the AI steps in.
Document Classification
Smart Data Extraction will automatically identify document types across 19 supported categories, including invoices, receipts, IDs, contracts, and memos. Each page is labeled with a type and confidence score, so teams can route documents into the right workflow, whether that means extraction, review, or other internal processes.
Key-Value Extraction
With Key-Value Extraction, businesses can intelligently identify and extract critical information such as names, dates, amounts, and addresses from unstructured, free-text documents. Instead of relying on rigid templates, it recognizes key terms and their corresponding values, even when formats vary.
Currently, your organization rely on three primary methods for extracting structured data:
- Manual Data Entry: Slow, expensive, and prone to errors.
- Template-Based Extraction: Works only for predictable layouts, failing when documents vary or come from unknown sources.
- Cloud-Based API Services: Provide extraction but lack control, flexibility, and on-premise processing. They also introduce security risks, especially for industries handling sensitive data like PII (Personally Identifiable Information) in finance, healthcare, and legal sectors, where sending documents to third-party servers can be a compliance challenge.
Each of these approaches comes with trade-offs, either sacrificing speed, accuracy, or control.
Apryse’s Key-Value Extraction doesn’t.
Instead of relying on rigid templates, it intelligently identifies key-value relationships within free-text documents. Whether it’s a bank statement, legal contract, insurance form, or government ID, Apryse extracts the critical information you need, without requiring structured formats.
Table Recognition
Extracting data from a PDF table is challenging even for a person doing it manually.
Smart Data Extraction parses rows, merged cells, and numeric data from complex, layout-heavy tables, including challenging aspects like spanning cells that trip up some extraction tools.
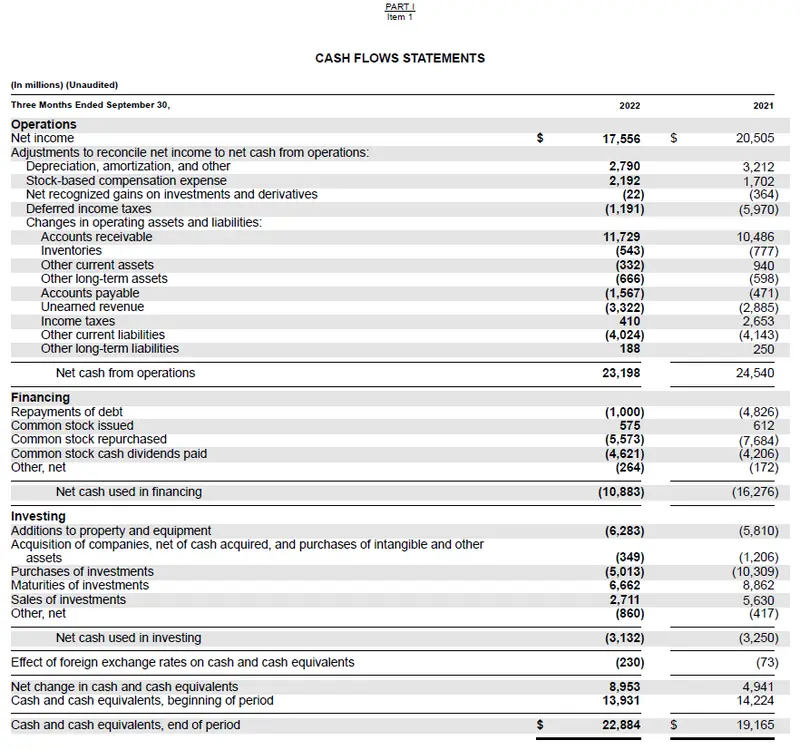
A PDF Table in a SEC 10-Q Report
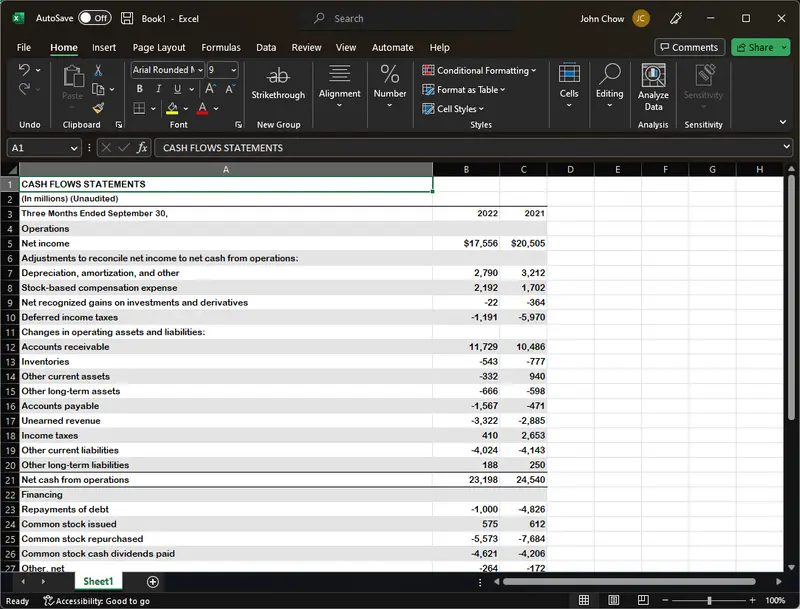
Our Excel output capturing a 10-Q table
The Table Data Extractor works within the recognizer workflow but is a separate function. It extracts tabular data into an Excel spreadsheet file, with one table per sheet, and to a JSON companion file.
You can use the extractor to pull out just one table element-- from one PDF or many PDFs at once.
Full Document Element Extraction
As well as going granular, Smart Data Extraction can extract core components from PDFs, including text, images, fonts, layers, signatures, form fields, annotations, and metadata, so nothing gets lost in translation.
CAD Title Block Extraction
PDF versions of CAD drawings are widely used because they allow stakeholders to review drawings without costly design software seats. Automated extraction of CAD Title Blocks scans and captures information like drawing numbers and revision dates from PDF files which increases efficiency, improves accuracy, and enhances data availability for downstream workflows.
Document Structure & Form Field Detection
Structure Recognition refers to awareness of how the content elements in a PDF are positioned on a page and in relation to each other, rather than simply what these elements are (such as text and tables). As part of parsing the PDF, the Intelligent Data Extraction component reconstructs the formatting and layout (structure) of content elements and what they look like on screen into JSON.

Image of the document structure in JSON
Smart Data Extraction goes beyond OCR by understanding document hierarchy (headings, paragraphs, lists) and spotting visual markers like checkboxes and labels.
Because the SDK intelligently detects the difference between form titles and fields, it can extract just the data you need, and nothing you don’t.
Deploy Anywhere
As a SDK-based deployment, Smart Data Extraction doesn’t introduce any external dependencies to your solution, making it ideal for highly sensitive documents and data. The Server SDK works offline, on-prem, hybrid, or air-gapped. It’s compatible with Java, .NET, C++, Python and more. Visit our documentation for more details on deployment and getting started.
What’s Next with Apryse Smart Data Extraction?
Our Smart Data Extraction solution enables efficient and leading accuracy PDF content extraction without need for extensive upfront training or templates.
Visit the documentation for samples and feature details. Also, visit our page on JSON for details on the output structure and tags. As always, your feedback is invaluable, helping us continually tune and improve performance and accuracy. If you have any issues with your free trial, don’t hesitate to send any questions you might have our way via the trial support.
When you’re ready to start with the Apryse Server SDK and Smart Data Extraction, or to add Smart Data Extraction to your existing Apryse Server SDK license, contact Sales.