James Borthwick
Published November 10, 2015
Updated May 18, 2026
10 min
PDFNetJS: Complete Browser PDF Viewer and Editor
James Borthwick


The WEB Is Taking Over (Obviously)
On desktop computers, web apps continue to replace activities that were previously fulfilled by Windows/Mac/Linux programs. The advantages are many: web apps are immediately available on every connected computer; the user doesn’t need to download and install something; they instantly update and they’re cross-platform. That they naturally lend themselves to a subscription model is yet another reason that companies are choosing to develop web apps in favor of a traditional desktop program.
However, web apps have historically had a number of shortcomings. An inability to deal with local files (without long uploads). Multimedia required security–challenged plugins (like flash player). And they couldn’t display PDF files.
How Do Web Apps Deal with PDFs Today?
Web apps typically deal with PDFs in one of two ways, either as a download (e.g. for archiving), or render it in-app using a web-technology.

Of course, PDF is not a “web technology”—is not part of or referenced by the HTML/CSS/JS specifications, and can’t be naturally displayed within a web page. So to display a PDF using web technologies, web apps rely on a server to convert the PDF to a web technology, such as HTML, PNG, or SVG.
This is an acceptable solution for some use cases, and one that we’ve offered to our customers for a number of years. (We also developed what in our opinion is the optimal conversion solution, which converts PDFs and other documents such as Office to a web-optimized XPS file format—see the WebViewer product page or WebViewer Buying Guide for more info, or view the following video on editing text in WebViewer.)
However, all server solutions have drawbacks that can’t be overlooked.
Why Server Conversion Is a Problem
Server conversion has to date been the best workaround for the fact that the web platform can’t display PDFs. These are the main shortcomings of server conversions:
- Server conversion adds delays, which can be long.
There are three things that the user needs to wait for: uploading the PDF to the server, waiting for the server to convert the PDF to HTML/SVG/PNG and then downloading the converted version. Nobody likes to wait. - Servers cost money and create hassles.
Application servers are costly to run and maintain. They also require additional developer time and expertise. - Anything that runs on a server will need to be scaled with usage, which is not true with client-side execution.
How Can We Do Better?
At Apryse, we knew that our customers would love a solution that didn’t require converting PDFs on a server. But how would that be possible? Could we make PDF a first-class web citizen, that is a file format that a web browser could independently display?
We investigated, and it didn’t take long to narrow in on the HTML5 <canvas> element, which as it happens is used as the basis for Mozilla’s pdf.js project.
What Is <canvas>?
Here’s the description of the canvas element, as described by Mozilla:
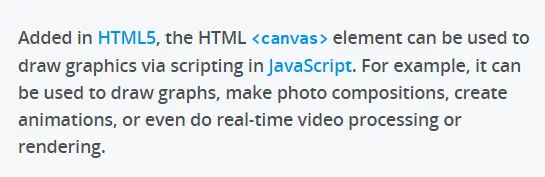
Canvas allows one to use JavaScript APIs to draw shapes, gradients, blends, images, text – all of the component pieces that make up a PDF page. So, the question is if it can draw the component parts of a PDF, can it be used to draw a PDF?
Why <canvas> Is Inappropriate for PDF Documents
The idea is to write a JavaScript program that parses and understands the PDF file, and uses the canvas to render all the elements to the page. It would take the PDF representation of a graphical element, and generate the canvas equivalent.
While in theory using canvas sounds like a good idea, there are actually a number of problems that make it unsuitable for use as a PDF renderer.
The first problem is that all rendering commands are issued in the UI thread, meaning complex pages either freeze the browser, or require constant calls to setTimeout() which slows down rendering.
The second issue is that canvas is hardware accelerated, which makes some rendering operations faster, but also unreliable. The problem is that by shifting responsibility for drawing to hardware, it relies on drivers, which may have issues with the Chrome browser. The drivers are also sometimes buggy. Because of this, the creator of the PDF renderer cannot guarantee it will render PDFs correctly, because much of the critical rendering code is outside of their control.
Lastly, <canvas> and PDF have different graphics models. Because PDFs contain non-image data, it means that the renderer (ie <canvas>) needs to know how to interpret non-image information and render it into an image. If the renderer doesn’t understand certain constructs, then it cannot render the page correctly. Unfortunately, the canvas model is not completely compatible with the PDF model, and so the PDF can contain information that is impossible for a canvas to draw.
An example of this can be taken directly from the PDF specification.
Here is a PDF snippet that draws some text that has a gradient fill, where the text and fill have different transforms.
BT
/Pattern cs /P0 scn
/GS0 gs
/TT0 1 Tf
30 0 0 30 181.5 494 Tm
(ABCDEFGHIJKLM)Tj
ET
This is what it looks like when it’s rendered:

However, in canvas, text and its fill cannot have different transforms. So what happens when this is put to canvas? As pdf.js uses canvas, we can look to it as an example. In this case, it outputs nothing, just a blank space where the text should be. Below is the page in question, rendered correctly on the left, and by pdf.js on the right.

What Makes PDF, PDF?
It’s worth pausing at this point to consider, what makes a PDF a PDF? Why do people use PDF as a file format? We think that a recently posted article on the PDF Association website put it very well:
Truth #2.It’s about a completely reliable experience
The PDF model begins with at least one page, usually including some text or images. PDF allows for many other features like digital signatures, encryption, attached files, metadata, and semantic information (tags) associated with that page, but the format’s core value is based on its ability to reliably represent the document author’s intent in all respects.
The primary value proposition of PDF is that it looks the same everywhere. This reliability is a cornerstone of the PDF format, so if a PDF renderer only renders some PDFs correctly, or parts of a PDF correctly, is it really a PDF renderer? At Apryse, the thought of shipping an unreliable renderer with a poor user experience is totally unacceptable, and something that we could not do. So <canvas> was out.
But we still wanted to provide web-based PDF rendering. So what could we do?
PDFNetJS
The answer, as we’ve discovered, does not lie in the latest and greatest web technology. The answer is actually old, using the same method as that used by the most popular desktop viewers. Reliable desktop renderers don’t use OS-provided graphics libraries like GDI or Quartz, but implement their own rendering internally. This way it is completely controlled by the renderer, and so correct rendering can be guaranteed. And this is in fact exactly what we’ve done with PDFNetJS. With PDFNetJS, the rendering is completely under our control, which means we can guarantee the accuracy, reliability, and user experience.
More than that, PDFNetJS goes well beyond basic PDF rendering and offers a complete PDF toolkit. It provides the same extensive functionality as our PDF SDK, because it is the same SDK, now available in the browser.
Besides rock-solid in-browser PDF rendering, PDFNetJS also allows developers to:
- rock-solid in-browser rendering
- annotate PDFs and fill out forms
- generate PDFs
- open PDF in a browser
- view PDF in browser
- edit PDF in browser
- split/merge
- reorder and organize pages
- redact pages
- extract text
- convert PDF
- PDF/A conversion/validation
- encryption, decryption
- optimization
PDFNetJS: No Server Component

Not relying on a server component for an in-browser PDF viewer provides a number of substantial advantages, for developers, your end users and the bottom line.
With PDFNetJS, Apps Are:
1. Easier to Develop
Skipping a server component means a number of things from a developer’s point of view. First, there is no need to set up a PDF server stack, so one substantial task is eliminated there.
Applications are easier to write, because complexities involved in spreading the PDF logic between client and server are eliminated. Similarly, asynchronous client-server communication is avoided, which is often a source of bugs that are hard to reproduce and hence to fix. Having all the code in one place makes programs easier to write, and easier to write without bugs.
With server conversion, you need to keep a duplicate representation of the content, which may or may not be ready or need updating. This is a form of caching, which we all know is one of the two hard things in computer science, and a frequent source of bugs and frustration. With PDFNetJS, there is no server, and no caching, making apps faster to develop and developers more productive.
2. More Responsive
With a server, a person needs to wait for their PDF to upload _and _be converted before they can do anything with it. This can be slow and tedious, and so undesirable. With PDFNetJS, local files can be viewed and worked on immediately, without an upload or conversion step. Cloud files can be instantly saved locally after annotating or modifying, without a 2nd download step.
3. More Reliable
A server is typically responsible for many, many end-users. If there’s a bug in your PDF processing logic that crashes or freezes your server, it has the potential to cause a major system-wide disruption. By placing all of the PDF processing in each user’s browser, they are all naturally isolated, so a problem encountered by one user will have no effect on others.
A second benefit is that as PDFs are a type of user input, placing their processing on the client side provides a large security benefit. The web server never needs to process the PDF – even if it’s stored online, it can be treated as a binary blob and never opened, except on the user’s computer. From the user’s point of view, the PDF may not need to ever hit the server, providing them with privacy.
4. Infinitely Scalable
PDF processing can be CPU intensive, so if you convert PDFs on a server, it means the more users you have, the more PDFs you’ll need to process and the more servers you’ll need to pay for and maintain. With PDFNetJS, all of the processing is done client side, so the browser-based PDF editor is as scalable as the plugin model: infinite, and free.
5. Cheaper to Develop
Building on the above, development costs are substantially reduced using PDFNetJS because there are no additional servers to run, maintain and scale. Developers are more productive, able to write high quality code more quickly. The cumulative reduction in costs can be substantial.
Code
So what is it like to use in code? Pretty simple.
Viewing a PDF
This presents a browser PDF viewer as shown in our online demo. It can be used as-is, or of course customized for both functionality and look/feel, to fit the requirements of your application.
Merging PDFs
This demonstrates how to merge two PDFs. If you’re familiar with the PDFNet API, it will look immediately familiar, as the API is the same as on our other platforms.
You may be wondering what all the yield statements are. These allow a special type of function (known as generator functions) to be conveniently run and resumed in a style that looks like regular code. This is required because PDFNet uses web workers to execute on a background thread, which keeps the UI responsive. For a more detailed tutorial, please see the WebViewer Getting Started Tutorial.
Performance
The performance of PDFNetJS is also very good. We’ve found that in most cases it’s as fast or faster than pdf.js.

When compared to native solutions, it’s about 95% as fast on Chrome, and about 50% as fast on other modern browsers. For most PDFs, the speed is sufficient that most users won’t notice any speed difference between PDFNetJS and a native app.
Showcase
After reading this we hope you’re itching to try it out. We have an online showcase available.
Another showcase is the Xodo web app, where you can not only view a PDF in a browser and annotate it, but also rearrange pages and merge documents.
Video Presentation
Apryse gave a presentation on XodoJS at the PDF Technical Conference. It contains information similar to this blog post (the sound is a little hard to hear, but it is audible).
Conclusions
PDFNetJS is an exciting and unique offering in the PDF world, and one that changes what is possible for web app developers to achieve.
In contrast with server-based conversion, PDFNetJS offers snappy performance and decreased development costs. In contrast with pdf.js, it offers correct rendering and a wide variety of PDF creation/modification APIs.
So download the SDK, give it a try, and tell us what you think.