Unlock the document data your AI needs
80–90% of enterprise data is still locked in unstructured PDFs, scanned forms, and legacy records - invisible to your AI pipelines and quietly limiting your ROI. This eBook shows you how to close that gap. You'll learn:
The hidden infrastructure gap costing AI projects their ROI
How Smart Data Extraction turns flat PDFs into structured JSON
A 5-step document lifecycle built for enterprise AI scale
The AI Readiness Gap Is a Document Problem
Source: Apryse AI Readiness Report
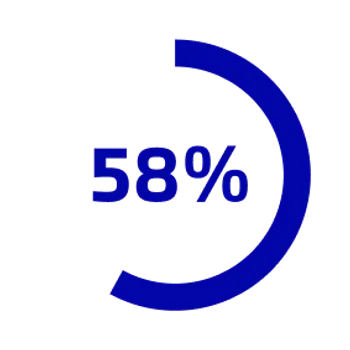
58% of organizations cite data extraction as their primary AI bottleneck
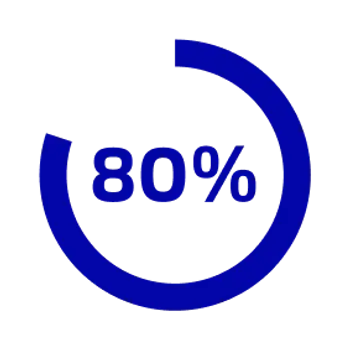
80% of enterprise data sits in unstructured formats including PDFs, scans, and legacy records
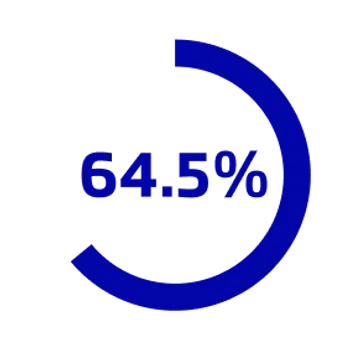
64.5% of organizations already have AI in production but most lack the infrastructure to scale it
AI Transformation Runs on Document Infrastructure
True AI-enabled transformation requires a document foundation that is intelligent, interoperable at scale, and secure by design.
The Core Problem
The gap between AI ambition and AI results is not a model problem. It is a data infrastructure problem, and documents are at the center of it.

Fragile OCR Pipelines
Custom pipelines built from open source libraries break the moment a document format changes, scan quality degrades, or volume scales.

Unpredictable cloud costs
Per-page cloud billing turns document processing into a financial ceiling on AI growth. At enterprise scale, those fees compound.

The Table Tax
PDFs don’t have native table structures. Most extractors fail when tables split across pages or columns shift.

Vendor Sprawl & Compliance Risk
Separate tools for viewing, editing, redaction, signing, and extraction each carry their own SDK, license, and integration complexity fragmenting your AI infrastructure.

Don’t let weak data foundations limit your AI
Smart Data Extraction is the scalable infrastructure layer that makes AI-enabled digital services possible at enterprise scale. Download the AI-Ready Document Infrastructure eBook to learn how to future-proof your AI strategy with a unified document intelligence layer.
Apryse SDK Capabilities
The intelligent document layer that turns unstructured files into AI-ready data.

Optical Character Recognition
Multilingual, high-accuracy text extraction

Intelligent Character Recognition
AI-powered handwriting recognition

Document Structure Recognition
Recognize complex paragraphs, tables, headers, and graphics

Table Extraction
Custom-built AI models extract complex tables accurately

Form Extraction
Template-based field identification and extraction

Barcode Extraction
Seamless barcode reading integrated into document workflows
See all capabilities at a glance, available with Apryse SDK on web, mobile and server.