What is PDF Linearization?
By Apryse | 2019 Jun 11

6 min
Tags
linearization
PDF “Fast Web View” or Linearization is a way of optimizing PDFs so they can be streamed into a client application in similar fashion to Youtube videos. This helps remote, online documents open almost instantly, without having to wait minutes or hours for a large document to completely download.
Linearization is thus especially useful when accessing large documents from any remote URL or resource, be it from a browser, mobile, desktop or server application.
Apryse supports Linearized PDF, and it is the first to support PDF linearization within a browser viewer (i.e., WebViewer). It is also a simple matter to create linearized documents using our cross-platform PDF SDK.
The following article provides an in-depth linearization explainer. But feel free to skip ahead if you seek instructions on how to linearize your documents programmatically within an application, or manually.
What is PDF Linearization?
- Linearization pertains to accessing online PDF documents from any software.
- Pages are served or “streamed” via byte-range requests to a client from a Web Server.
(Instructions on how to stream with Apryse SDK)
Watch Andrey, our head of product, explain the different terms and how to implement PDF streaming:
When Should I use Linearization?
Any developer working with large, network-bound documents should consider using linearization. Here’s why:
We’ve found that linearization enables opening of large PDFs in 7 seconds on average when using a 4G connection. And while open time extends when a document has a very large and complex first page, most documents are shown to benefit from linearization so long as they have at least a few pages.
Linearized vs non-linearized documents opening online on an Android device via a 4G network
Linearization therefore delivers a much faster online experience overall. And it provides several other advantages when working with remote, online documents:
- Linearization makes the viewing experience more resilient to network interruptions. A network interruption during a large document download, for example, might require that the user restart; at the very least, it can significantly delay first page view.
- It improves reliability where there is limited memory/storage, where it would be difficult to cache downloaded data locally (for example, when working in a browser and especially, in a mobile browser).
- It reduces network transfer costs. Some viewers such as our Apryse SDK can be configured to download only those pages viewed by the user. This is critical when serving very large 1GB+ to mobile devices with limited or costly data plans, and beneficial even when serving smaller documents of 20MB+.
How Linearization Works - Fast Random Access via On-demand Streaming of Pages
Linearization, introduced with PDF 1.2, has a 20+ page appendix dedicated to it in the core PDF reference.
But if you prefer a faster explanation, read on.
Linearization works by changing a PDF file’s internal structure in a way that enables fast on-demand streaming of partial content.
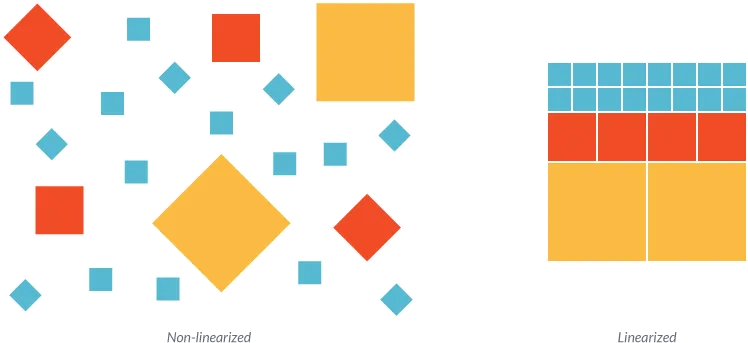
Put simply, each PDF is an object tree, starting with a root node, and ascending from there. Pages can reference other objects hanging from that tree by object number. In the case of non-linearized PDFs, these objects, such as an embedded font, are often scattered across the file. And with no quick method to identify and grab a given page’s resources, a conventional viewer will need to download the entire document before it can open.
In contrast, linearized PDFs are reorganized so that page resources are grouped together logically according to document page order (hence the term “linearization”). A Linearization Dictionary and “Hint tables” are also added to the top of the document. These act as an inventory specifying the location of objects needed to render any given page, essentially enabling random online access to pages.
A system that uses linearization usually converts documents to linearized PDF upon upload.
A viewer designed to handle linearized content can then request linearized PDF content from the web server via a URL. This information is then served as sequential content “chunks” of PDF binary.
If the viewer detects linearization, it will stop the download after receiving the hint tables and first page. Remaining content chunks are then prioritized based on how the user navigates. For example: if the user skips ahead to page 475 in a 1000-page document, the viewer can request resources for page 475 and surrounding pages, and these will download first.
The remainder of the document will then progressively download and render as the user session continues. And obsolete pages can be easily cleared from memory when required.
When to Linearize Documents
A few things may cancel its advantages.
For example:
- When one routinely serves documents of small size (i.e., one or two pages in length and <10MB).
- When one accesses documents locally (because CPU time may dominate over I/O).
- When one’s documents are dynamically generated in an unlinearized form such as when users download PDF files from external websites or create PDFs on their local machines using third-party tools (e.g., Adobe). It can be difficult for some solutions to linearize these files on the fly without impacting performance.
How can I tell if my PDF Document is Linearized?
A linearized document may be identified by taking a quick look under the hood at the PDF document file header.
Just open the PDF document in any rudimentary .txt editor. Then seek out the header at the top of the document. It should look like the following:
%PDF-1.7
%âãÏÓ
10790 0 obj
<</E 42176599/H [ 1139 11376 ]/L 148887844/Linearized 1/N 2229/O 10792/T 148875428>>
endobj
See a “Linearized” flag like above? That tells you that your PDF file is likely linearized.
Bear in mind that corruption or other issues can impair your ability to correctly identify linearized documents. Even if the flag is present, your PDFs might not be properly linearized.
For example, incremental saving may stealthily break linearization. This is a preferred saving method for big documents due to how it quickly appends new content and changes to the end of the file without making changes to the rest of the file.
How to Linearize Your Documents
PDFs produced and saved “in the wild” by third-party software may not be linearized or may no longer be linearized properly (e.g., because of incremental saving).
Therefore, if you intend to leverage linearization, you will want to consider a solution able to quickly linearize documents when uploaded to your system, and possibly again when saved in client applications.
With Apryse’s cross-platform SDK, you can use linearization cross-platform in a wide variety of situations.
Linearizing Documents with the Apryse SDK API
First download the Apryse SDK.
The following code samples will then let you embed linearization functionality into most applications using the API.
doc.Save(output_path + "filename.pdf", SDFDoc.SaveOptions.e_linearized);
const docbuf = await newDoc.saveMemoryBuffer(PDFNet.SDFDoc.SaveOptions.e_linearized);
saveBufferAsPDFDoc(docbuf, 'filename.pdf');
await PDFNet.endDeallocateStack();
For virtually any other languages/platforms, refer to the guide.
Linearizing Documents with Apryse CLIs
DocPub CLI and PageMaster CLI are easier-to-use, manual solutions.
Both DocPub and PageMaster can perform batch conversion, and each leverages the same advanced PDF conversion engine as the API, including components that can be integrated into any app.
If you’ve never used a command line interface before, it is recommended that you first read or watch a quick beginner’s guide. For example:
For this guide, we’ll go over the basic steps for DocPub, which is recommended if additional page manipulation features are not needed. (Similar steps will work for PageMaster with minor changes in command syntax. Read the user manual provided in your trial download package for more information.)
After downloading the DocPub trial package, unzip to the correct working directory (i.e., the folder directory where you intend to perform linearization).
The basic DocPub command-line syntax is as follows:
DocPub [options] file1 file2 folder1 file 3 …
Adding the parameter --linearize to the [options] section of a command will allow you to convert documents into linearized PDF files.
For example:
DocPub --linearize DocName.doc
This will convert a single document named “DocName.doc” in the current working directory into linearized PDF. (Unless otherwise specified, the CLI will convert to PDF by default.)
Batch Linearizing files via DocPub CLI
DocPub also supports batch linearization.
For example, the following command will let you grab PDF files in a given input directory and save them to a given output folder as linearized PDFs.
DocPub --linearize -f PDF "c:\My Input" - o "c:\My Output"
The next example method batch converts and linearizes any of the 30+ file types recognized by Apryse in the specified subfolders.
DocPub --linearize --subfolders Folder1 Folder2
Further instruction on how to use the DocPub CLI is available in the DocPub User Manual, included as part of your zipped trial download package.
Tags
linearization

Apryse
Share this post