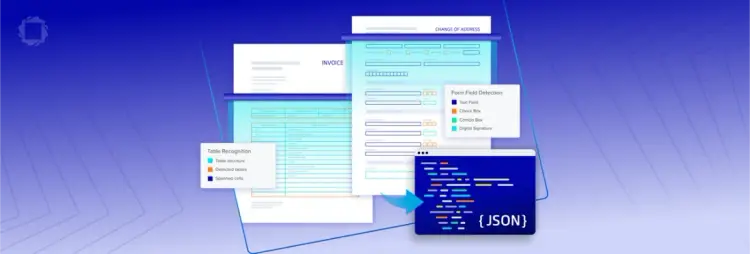
Context-Aware Output, Built on Document Logic
Power downstream workflows with context-aware output. By recognizing the underlying logic of complex PDF documents, Smart Data Extraction automatically maps key-value pairs and nested tables into reliable, structured formats. It serves as the industrial-strength foundation for analytics and AI initiatives, backed by consistent model training and enhanced extraction logic to ensure your pipeline stays ahead as document standards evolve.







AI at Apryse
Extraction to Action: The Full AI Workflow
Smart Data Extraction, a capability of the Apryse Server SDK, turns unstructured content into automation-ready data. It's one stage of a larger pipeline, including human-in-the-loop review and validation, that you can build across the Apryse platform.





How it Works: Purpose-Built Models for Document Logic
Extracting structure from PDFs is difficult. Text is often unselectable, and tables lack underlying tags. Apryse solves this by applying advanced computer vision to understand layout and semantics. We utilize real-time object detection (YOLO) to identify tables and sections, paired with BERT-based models to resolve text meaning. These aren't general-purpose models; they are purpose-built and trained on high-stakes documents like contracts and forms. Most importantly, your privacy is baked in. Our models are trained exclusively on public and synthetic data, ensuring your documents are never part of a training set.
Extraction FAQ
Smart Data Extraction refers to the use of AI and machine learning technologies to automatically extract, understand, and process data from various document formats, transforming unstructured data into structured, actionable information.
OCR (Optical Character Recognition) converts printed text from scanned images and non-searchable PDFs into machine-readable content, while ICR (Intelligent Character Recognition) extends that capability to handwritten text. Both focus on accurately capturing and digitizing the raw content of a document. Smart Data Extraction goes further, using AI and machine learning to understand the meaning and context of that content, transforming unstructured document data into structured, actionable information ready for downstream processing or automation. Think of OCR and ICR as the digitization layer, and Smart Data Extraction as the intelligence layer built on top of it.
The SDK provides structured, schema-ready output, typically in JSON, XML, or Excel. This allows for direct integration into downstream applications, ERP systems, or AI/LLM pipelines without the need for manual data cleaning.
Absolutely. Apryse's Smart Data Extraction solutions can be customized to meet the specific needs of various industries, with the ability to recognize and process industry-specific document formats and data types, ensuring high accuracy and relevancy in data extraction.
Instead of relying on fixed coordinates, the SDK uses a combination of visual layout analysis and semantic understanding. It "sees" the spatial relationship between a label (the Key, e.g., "Invoice Number") and its corresponding data (the Value, e.g., "INV-001"), even if they are separated by white space or nested within complex forms. This allows for accurate extraction across varying document templates without requiring pre-defined zones.
Assigning a classification to a document happens at the page level, assigning a specific document type and confidence score to every page in a file. This granular approach allows the SDK to accurately identify and split "multi-document packets," such as a single PDF containing an invoice, a contract, and a memo, ensuring each component is routed to the correct downstream pipeline or recipient.
Yes, Apryse’s Barcode Extraction, can accurately read damaged, skewed, or low-quality barcodes. This ensures reliable performance even in challenging conditions.
RESOURCES
Innovative Technology. Proven Results

Smart Data Extraction Guide
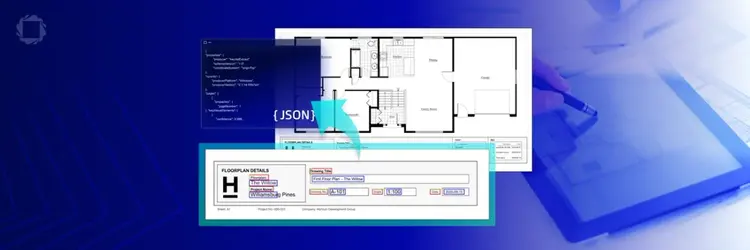
Smarter Workflows with Apryse Server: Introducing CAD Title Block Extraction

Smart Data Extraction Webinar
What’s New in Apryse 10.7?
2024-02-28

Automate Accurate Data Extraction from PDF | Apryse Smart Data Extraction