Garry Klooesterman
Senior Technical Content Creator
Published May 29, 2025
Updated May 18, 2026
5 min
How to Redact a PDF in JavaScript
Garry Klooesterman
Senior Technical Content Creator
Summary: Handling and protecting sensitive information must be done properly, or businesses could face serious consequences. Redaction is an effective method of protecting this information, and automating the process with an SDK helps ensure that it is done correctly. This blog looks at redaction and automating the process using the Apryse SDK and JavaScript.
Introduction
Handling sensitive information, whether it’s acquiring, storing, sharing, or deleting, is not to be taken lightly. More than just good practice, it’s also about regulatory compliance. Regulations such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States, or the Personal Information Protection and Electronic Documents Act (PIPEDA) in Canada define how personal and sensitive information is handled, secured, and disclosed.
If done right, redaction is an effective method of protecting sensitive information that should not be shared. Using inadequate tools or methods could result in the information still being accessible and could lead to serious consequences, including fraud, reputational risk, and even personal harm. To help ensure redaction is done right, an SDK can be used to automate the process.
In this blog, we’ll look at what redaction is, why it’s important, and how to redact information from a PDF using an SDK. In the example, we’ll use JavaScript, but the Apryse SDK is also available for other languages and frameworks such as C#, Java, and more.
For a browser-side solution, see our Ensuring Irreversible Redaction: Avoiding Hidden Metadata Risks blog.
PDF Redaction and its Use Cases
Redaction allows for the sharing of select information while protecting other sensitive information. One example is removing client information from screenshots of a customer relationship management (CRM) system used for training. Another example is a business removing client information such as name, age, address, and contact information when sharing client feedback internally. Both examples illustrate how redaction protects sensitive information that could be exploited while allowing other important information to be shared.
Redaction Methods
Paper Documents
For paper documents, common methods of redaction include using black marker or opaque tape to obscure the text before it is photocopied to permanently remove the information.

Figure 1 – An example of a redacted document that raises a few questions.
These are effective methods for paper documents, but what about digital documents?
Digital Documents
Ensuring sensitive information is redacted properly and permanently in digital documents can be more difficult. For example, changing the color of the text or background or covering the text with opaque blocks in an image layer are not effective ways to redact information. Cases have shown that the text intended to be redacted was able to be retrieved.
It’s important to look for information to be redacted in areas such as comments, version history, and metadata as well.
The Redaction Process
In its basic form, the redaction process is made up of two main parts:
- Identifying the content to be redacted.
- Removing the content.
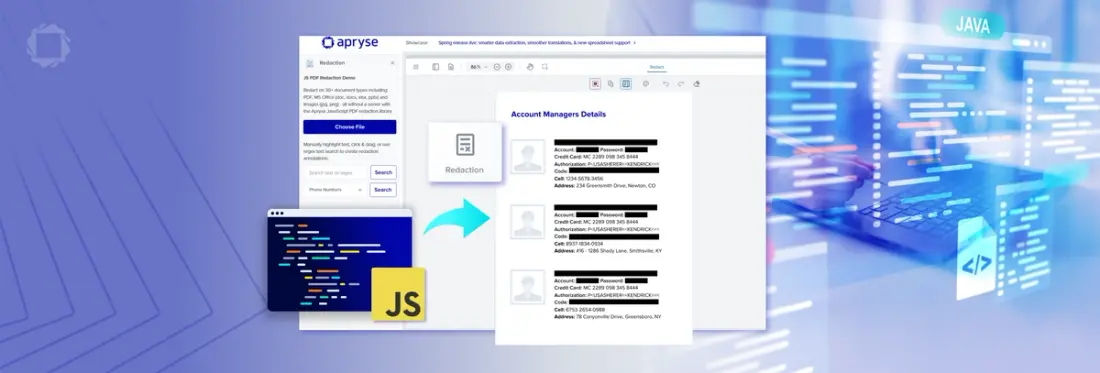
PDF Redaction Using Apryse SDK
Using an SDK like the Apryse SDK to automate redaction provides many benefits such as:
- Bulk Processing: Handle large volumes of documents quickly and consistently.
- Pattern and Keyword Detection: Automatically identify and redact specific types of information.
- Complete Data Protection: Ensure the permanent deletion of text, images, or entire pages, making the content unrecoverable.
- Easy Integration: Our extensive APIs allow you to add redaction functionalities easily and seamlessly into existing systems, supporting client-side and server-side applications.
- Customization: Customize redaction techniques to meet your specific needs.
Using the Apryse SDK, the redaction process consists of two steps:
- Content Identification: Content to be redacted is marked by the user with redact annotations.
- Content Removal: The redactions are applied by the SDK, and the information is removed.
Note: Style elements of the redaction overlay including color, text, font, border, transparency, and more can also be customized.
How to Get Started
Let’s get started with setting up a project using JavaScript.
Why JavaScript?
As one of the most used programming languages in the world, JavaScript can be found in 99% of websites. It can be used for a wide variety of client-side applications, with security as one of the many advantages, but it can also be used server-side for tasks such as queries and authentication.
JavaScript is versatile, easy to learn, and easy to implement, making it a perfect choice for our project.
Process
- Download the Apryse Server SDK. In this case, we’ll want to choose the Node.js PDF library.
- Follow these steps to set up your project.
- Get a free trial key.
We'll now look at how to redact parts of a PDF using the code from one of our many code samples available, PDFRedacttest.
I've provided the code here as well for easy reference.
Let’s break down the code for a closer look.
The array redactionArray is used to define areas to redact and is created using the code:
const redactionArray = []; // we will contain a list of redaction objects in this arrayEach section or region to be redacted is defined by an array element like this:
This line of code tells the SDK that we’re going to redact a rectangular section of page 1 with the coordinates “100, 100, 550, 600”. The content in this area will be permanently deleted and you’ll see the words “Top Secret.”
The following code is used to customize the appearance of the redaction overlay:
The following code is the main line of code that runs the redaction using the parameters that were set earlier:
await redact(inputPath + 'newsletter.pdf', inputPath + 'Output/redacted.pdf', redactionArray, appear);And as easily as that, you’ve redacted your first document!
Conclusion
Properly redacting sensitive information is crucial, and using an SDK like the Apryse SDK to automate the process not only helps ensure it's done properly but also helps businesses adhere to international privacy laws. Using incorrect or inadequate redaction methods can have serious consequences including reputational damage, financial loss, and even personal harm.
Try it out for yourself with our free trial.
Get started now or contact our sales team for any questions. You can also check out our Discord community for support and discussions.