Valerie Yates
Sr. Content Strategist
Published December 08, 2022
Updated May 18, 2026
7 min
PDF Rendering and Viewing: What Is the Difference?
Valerie Yates
Sr. Content Strategist
Like any format, PDF comes with its own jargon, which can all seem very complicated. One set of terms we see frequently are PDF rendering and PDF viewing. As a commercial PDF SDK vendor, we see these terms confused very often. So, in this post, we take a closer look.
Since we have some expertise in the field, we’ll also look at our native SDKs and JavaScript PDF rendering library and how it renders PDFs. In the process, we peel back some of the layers of mystery of how it unpacks your PDFs for display.
TL;DR
PDF rendering means turning PDF file contents into images that can then be displayed in a viewer application. In contrast: PDF viewing is what we call it when rendered images are displayed in a viewer application viewport. Once a PDF file is rendered, you can interact with the content. All PDF viewers are built on top of rendering functionality.
A Quick Look Inside a PDF
PDF is a portable document format that is used to present documents that include many types of content. Most PDFs contain 2D vector graphics, including vector text, and some may contain 3D graphics. PDF also lets you embed "raster" images (JPEG and many other image formats). A PDF file can contain annotations, signature and form objects for data capture, JavaScript code, links, and a lot more. The type of content it contains depends on how your PDF file was created.
PDF is much more than simply a display format. In addition to content, a PDF file contains instructions about how to organize and lay out that content.
What Is PDF Rendering?
To display a PDF file, its contents must first be rendered into an image (i.e., display) format. PDF rendering is the process of turning your PDF into an image you can view on screen.
A PDF library first needs to decompress the binary PDF file and parse its contents. Next, the PDF rendering engine converts parsed PDF file contents into drawing operations.
Most often, the graphics in a PDF document will be encoded as one of two types of data: raster or vector.
Raster Data
A raster specifies what goes into each pixel of an image. Rasterizing a PDF file converts the document into an image or "bitmap" commands. A raster image is made up of pixels.
Vector Data
Vectors are mathematical commands to draw geometry. You can have vector lines, vector shapes, even vector text. For example, a PDF vector content stream can include instructions to draw a straight line of Y length, turn X degrees, and repeat the line. Or with a little extra math, it may specify a curve in the line:
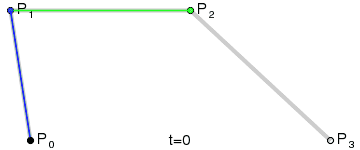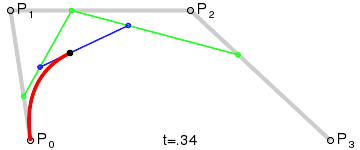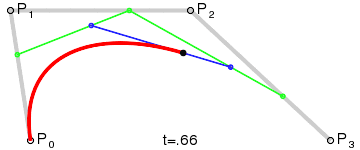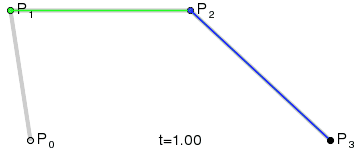
A Bézier curve with control and anchor points. (Source: Wikimedia commons)
Most PDFs are vector files, but PDFs can also be saved as raster files. Most PDFs created from CAD (Computer-Aided Design) are vector-based because they contain more data that make it easier to work with drawing and model content, and the display of the geometry remains sharp when you zoom in with vector. Measurements and takeoffs (as well as their calibration) also retain precision in a vector PDF because you can use Snap to Content to snap to the vector lines in the PDF.
- How to snap-to lines and objects in PDFs using JavaScript
- How to tell if your PDF contains raster, vector, or text
What Is PDF Viewing?
PDF viewing is when the user interacts with displayed (i.e., rendered) content. Since PDF content is interactive within the viewport, the PDF renderer needs to be responsive also.
A PDF rendering and viewer library typically mounts controls in the viewer UI that allow the user to navigate the content (pan and scroll across, and zoom into content). A PDF library may also provide APIs to control the rendering and viewer behavior programmatically.
During navigation, the viewer communicates to the engine what parts of the document it needs to rasterize and at what scale. As the viewer requests information, the lines, text, and shape instructions that make up a PDF page are painted in memory and the result is used to update the display viewport.
How Are PDF Rendering and Viewing Handled by the Apryse SDK?
In our JS PDF viewer and editor, WebViewer, the display viewport consists of the HTML5 <canvas> element. But we use our own in-house engine to control final rasterization of the PDF rather than rely on the browser for rendering.
Building a custom viewing application directly on top of PDFView is a lot of work; most developers prefer to use the prebuilt controls. On platforms including mobile, this is the PDFViewCtrl class. On the web, developers use Core.DocumentViewer, a more accessible object in the WebViewer instance.
The DocumentViewer allows you to work with documents without working in detail with the WebViewer Core.
For example, with DocumentViewer, you can programmatically control viewer behavior such as zooming and scrolling, set actions on an event, such as to flip to the second page when the document loads, and access many other controls for your PDF and Office document viewing. DocumentViewer also provides functions for manipulating the image/raster output, including controls for color processing.
Additional Rendering Techniques
To ensure a fast yet precise UX, the Core Apryse engine applies additional techniques as the document displays, including viewport rendering, page caching, and other strategies. For example, depending on the PDF file being viewed, the Apryse SDK may use one or both of Progressive Rendering and Pre-Rendering:
- Progressive Rendering: Provides early updates of a complex page such as a vectorized technical drawing. The engine provides a simplified image representation that is later replaced, so the user has something to preview right away at the start of their session.
- Pre-Rendering: Renders pages off screen ahead of the user, so pages can be instantly displayed in the viewport as the user navigates through the rest of a document such as a long report.
The Apryse SDK supports each step of the PDF rendering pipeline—from initial PDF file parsing, to final rasterization in the viewport as an image. Along the way, it provides several classes, giving developers the option to build a custom viewing application atop the Apryse Core or to control the user experience within the pre-built viewer. The customizable, out-of-box UI is also available on GitHub as React for developers to fork.
Interactive rendering is handled by the PDFView class: this implements critical features such as double buffering and multi-threaded rendering, as well as scrolling, zooming, and page navigation that are essential for an interactive rendering application.
A Note about PDF Rendering Engines
Many aspects distinguish a good rendering engine from a poor one. And there are several ways to get an engine, from using open source to leveraging a proprietary PDF SDK rendering library.
In Conclusion — PDF Rendering vs. PDF Viewing in a Nutshell
In summary: PDF viewing is when rendered images are actually displayed in your viewer UI, typically with controls so you can pan, scroll, and zoom into content!
Rendering is extracting, parsing, and converting PDF file binary into images you can see in the viewer viewport.
There is obviously interaction between the rendering engine and viewer layer; the viewer communicates to the engine the images it needs to display in the viewport—the rendering engine creates those images dynamically!
Further Resources
Want to learn even more about PDF rendering and viewing technology? Check out:
- A comparison guide with GitHub samples for the different JavaScript PDF rendering and viewing libraries to embed in a web app, including our in-house JS PDF viewer and editor library
- More tips on how to choose the right PDF rendering engine for a PDF viewer app
- The Apryse documentation for advanced PDF rendering and printing
- Guide to creating viewer-optimized PDFs for fast rendering in mobile and web apps
Much like the PDF specification itself, our powerful in-house rendering engine came into being several decades ago and has since seen constant enhancements and refinements. We’d love to hear about any PDF rendering and viewing challenges you’ve experienced or ideas that may deliver yet more benefits for PDF-centric workflows. Feel free to reach out to us!