Valerie Yates
Sr. Content Strategist
Published November 24, 2022
Updated May 18, 2026
5 min
How Can I Tell What’s Inside a PDF? Raster, Vector, Text?
Valerie Yates
Sr. Content Strategist

Related Products
So, a PDF is a PDF, right? On the surface, that might seem so, but PDF content, such as graphics and text, can belong to different data types. Depending on how your PDF was created, you will have a vector- or raster-based PDF on your hands. And that can make all the difference in your ability to interact with, measure, and search the content.
Telling vector from raster PDFs may not be possible with a simple visual inspection, as the differences are not evident immediately. So, in this post, we share a few tips & tactics to help you determine what's inside your PDFs.
Some Types of Content in a PDF
We’ll look at the most important content in PDFs from an interactive standpoint: graphics and text.
Graphics
Graphics in a PDF document are embedded as one of two types of data: raster or vector.
- A Raster image is made up of pixels. A raster file specifies what goes into each pixel of an image. Rasterizing a PDF file converts the document into an image or "bitmap" commands.
- Vectors are mathematical commands to draw geometry. You can have vector lines, vector shapes, and vector text. For example, a PDF vector content stream can include instructions to draw a curve in a line or a straight line.
Text
Text is an interesting case: it can be an exception to the saying, "If it quacks like a duck..." Text characters in a PDF might look like text but not be "true" text elements. If text is defined by raster dots or vector line segments only, the text isn’t machine-readable text. This type of "text" is essentially an image, and you can’t search, highlight, or edit characters in an image. For text to be true searchable text, it needs an invisible layer of character encodings. (Most PDFs use the standard UTF-8.)
Why Do These PDF Content Types Matter?
Ask yourself whether you’ve ever tried to do something with a PDF, unsuccessfully. Perhaps you couldn’t do any of the following:
- Search for, highlight, and select text
- Select layers
- Extract data or vector linework
- Snap to objects, such as lines, when taking measurements
The reason is probably that you had a raster PDF on your hands.
This is somewhat of a simplification, but most PDFs are vector files; you can also save PDFs as raster files. And each graphics type is built for specific purposes. Whether to use vector- or raster-based PDFs depends on knowing which is best for the job you want to do.
- Vector PDFs are ideal for storing and working with 2D images composed of line-based elements such as lines and polygons, or simple geometrical objects such as text. Most PDFs created from CAD (Computer-Aided Design) are vector-based.
- Raster files are ideal for complex, highly detailed, and true-color images and graphics, such as photographs. Raster files display a wider array of colors and show finer light and shading than vectors do. You can also edit color pixel by pixel.
How Can I Tell What’s Inside My PDF?
You can easily figure out whether the content of your PDF is vector or raster using a few tricks or tools:
Simple Methods You Can Try
1. Zooming in
Your best bet for most situations is to zoom in to a detailed part of a PDF, to greater than 800% magnification. Vector PDF file content will look clear and smooth at any magnification while raster PDF content will become blurrier and more pixelated the more it’s zoomed.
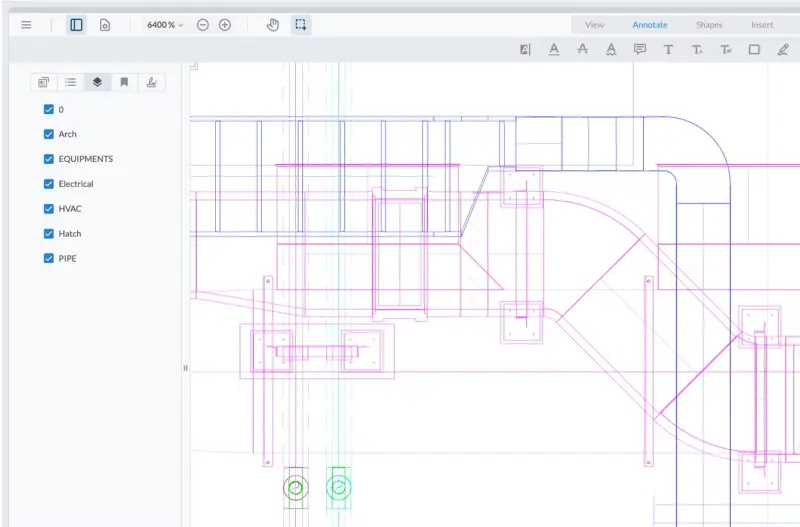
At 6400% magnification, vector content remains clear and sharp.

At 6400% magnification, raster content is jagged and blurry.
2. Select Text
If you can’t display text using a file menu option (such as Show All Text), then the text in the PDF is a raster image or vector lines without character encodings. Therefore, it is not “real” machine-readable text. Raster “text” is an image in which you cannot search text, select text, or edit text. The same goes for vector lines used to create the appearance of characters but without encodings.
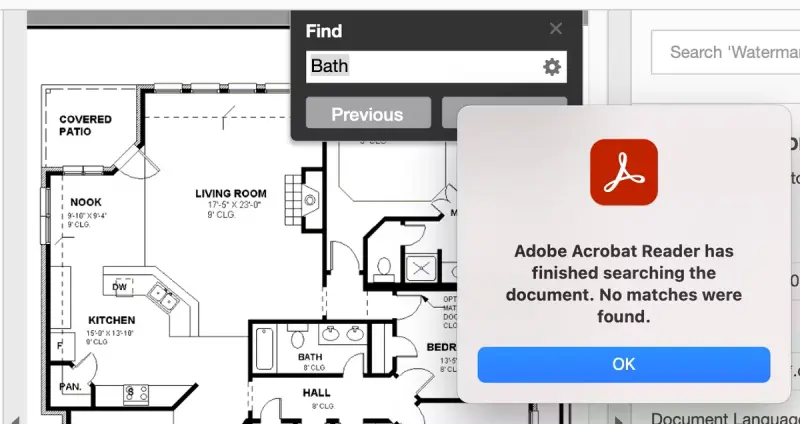
Text above is not searchable, because content is a raster image.
PDFs created from character-based programs (e.g., Word and Excel) almost always create PDFs that contain real text.

Text above can be highlighted, because the content is vector with characters encoded.
You can run optical character recognition (OCR) on a PDF if you need to convert raster and vector images into searchable text. OCR interprets the images on a scanned PDF and creates an invisible text layer on top. This layer allows you to access real text that would otherwise be unavailable for manipulation in an image.
- Try the Apryse online OCR converter
Tools & Tactics for Pros
Simple methods like zooming in are great if your PDF contains a huge image, such as a drawing of a building, and you just want to quickly verify its contents.
But what if you want to look at different elements on an individual level or across many pages?
Some tools can help shed light on what’s image content quickly, so you can work efficiently.
1. Audit Space Usage
Adobe Acrobat Pro lets you audit space usage to determine whether a PDF contains a lot of image content.
Choose File>Save As Other>Optimized PDF, or Go to Tools>Optimize PDF, and then click Advanced Optimization. The PDF Optimizer dialog box opens.
Click the Audit Space Usage button at the top of the dialog box.
2. Low-Level PDF Editors
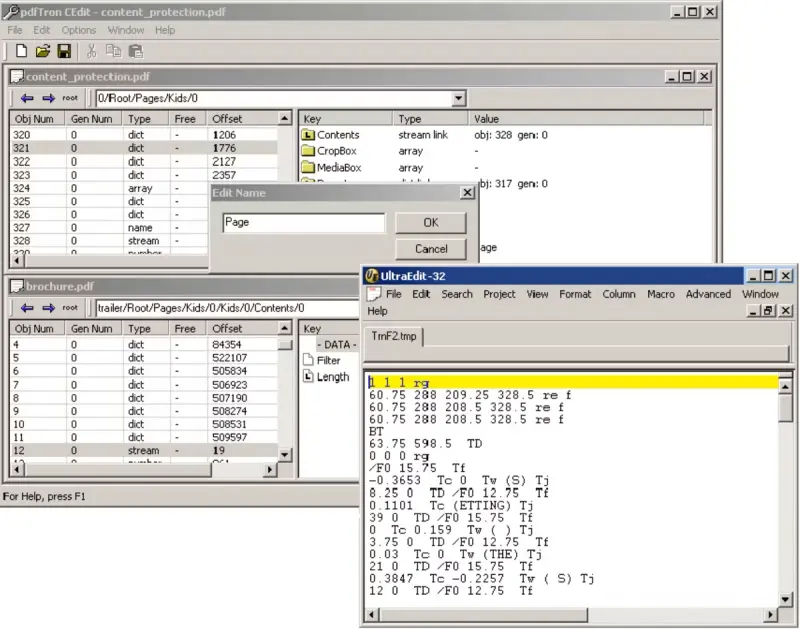
You can also use a tool like CosEdit to examine the low-level content of a PDF (Cos Objects, which represent components in a PDF file). PDF CosEdit is a stand-alone, low-level PDF editor. It allows you to create, browse, and edit PDF and other COS-based documents at the object level.
Using a low-level PDF editor provides insight into what’s inside a PDF.
3. Downsampling
Downsampling is the process of changing the resolution of an image, usually done during compression to reduce the PDF file size. Downsampling makes raster content low quality and thus its presence obvious.
You can downsample a PDF programmatically. Use the Apryse SDK and Class Optimizer. Specify a very low value for DPI (like 1) for ImageSettings and MonoImageSettings.
Conclusion
We hope that this blog has shed light on the types of data contained in PDFs and how to figure out what your PDF contains – raster, vector, or text.
If you’d like to deepen your understanding of PDF rendering and PDF viewer libraries, check out our articles:
- PDF Rendering and Viewing: What is the Difference?
- Open Source or Proprietary — What PDF Viewer Engine is Right for My Application?