Roger Dunham
Published January 17, 2025
Updated May 18, 2026
5 min
What A Save! An introduction to PDF File Structure - Part 3
Roger Dunham
Summary: The Apryse SDK enables creating, editing, and working with PDFs and DOCX files. This article explores PDF file structures, focusing on compatibility, quick-saving for edits or signatures, and linearization for faster streaming. It debunks myths about PDF structures, revealing hidden complexities even in compatibility mode for PDF viewers.
Introduction
If you want to create and work with PDFs then the Apryse SDK is a great way to do so – not only will it create PDFs, it also allows you to work with, edit PDFs and DOCX files
In the previous parts of this series, we looked at how the internal contents of a PDF can vary depending on the objectives of the person that created the PDF.
The three main options are:
- Compatibility with old PDF viewers
- The ability to save the file quickly in response to small changes (or when the PDF has to be digitally signed by multiple people)
- Linearization to support streaming of the file over the internet and the rapid display of the first page.
The first option is often used to demonstrate PDF file structure as it is simplest, but in this article, we will see that, even with compatibility mode, the PDF structure is potentially more complex than many online articles would have you believe. We will look at several myths that relate to the file structure and see how things can be hidden within it while allowing it to be opened in a PDF viewer.
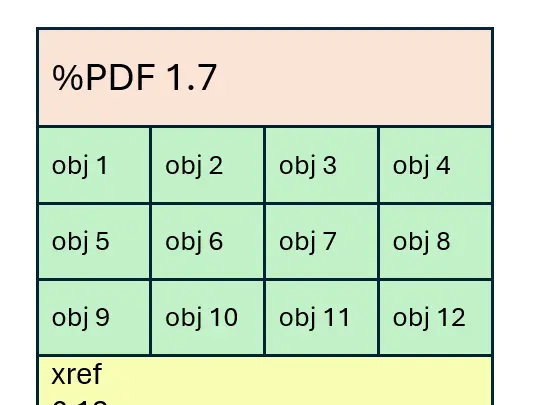
First though, let’s have a quick recap –for a non-linearized file, which has not had changes incrementally saved, the file structure is something like this:
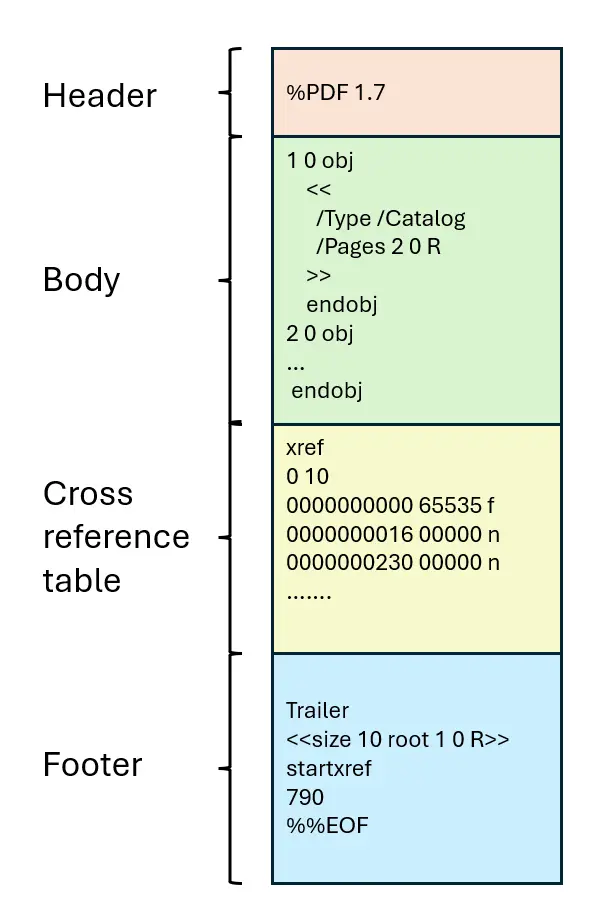
Figure 1 - A simplified example of the PDF structure.
While that layout is possible, the image implies things that are not necessarily true. For example, it suggests that the Body contains just objects which are all neatly packed together.
Myth 1 – The objects in the body are in incremental order.
While the various COS objects might be in incremental order (as shown in figure 1), there is actually no need for this to be the case – what matters is that they are located in the position that the xref table states – since that is used to resolve references from one object to another.
(Even that is a simplification, but we will live with that for now).
As such the COS objects could be like this:
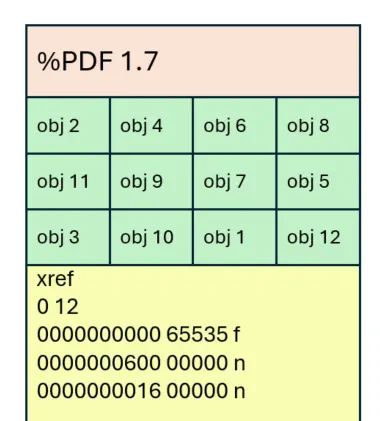
Figure 2 - There is no need for the Cos objects to be in increasing order - they just need to be where the xref table points to
In fact, if the PDF has been linearized then it is quite unlikely that the objects will be all neatly in order. Linearization (to support Fast Web View) results in all objects needed for the first page being close to one another, regardless of when they were added to the PDF.
Myth 2 – the objects in a PDF are next to each other.
Just as there is no need to have the objects in ascending order, since their location is recorded via the xref table, there is also no need for the objects to be directly next to each other.
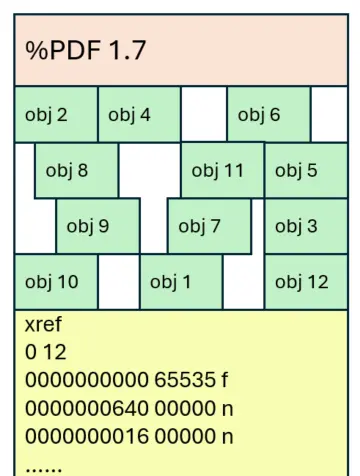
Figure 3 - Even if there are gaps between objects, the file can still be opened in most viewers.
In fact, if you use LibreOffice and create a PDF using that then the objects typically have gaps between them.
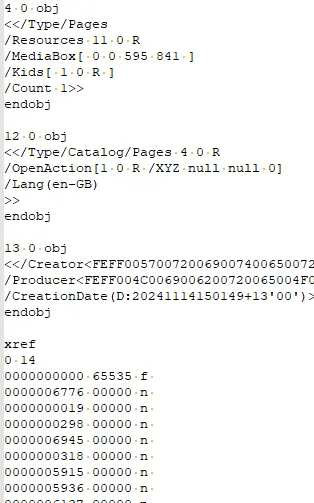
Figure 4 - Part of a PDF created by LibreOffice. Note that there are new lines between adjacent objects and the object sare not in ascending order.
Myth 3 – The %PDF file marker is at the start of the file.
The %PDF marker is often considered to be the File Signature of a PDF. While it needs to be earlier in the file than any of the rest of the PDF structure, it doesn’t actually need to be at start. In fact, it can be anywhere in the first 1024 bytes of the file.
This means that it is perfectly valid for other information to be present in the file before it, and for the file to still be valid.
As an example, let’s add some text there (it’s from the first chapter of “War and Peace” by Leo Tolstoy).
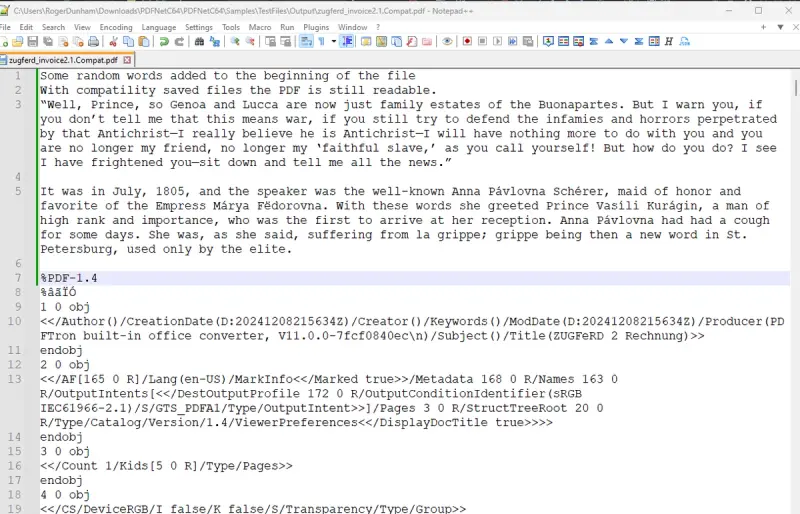
As long as the header text “%PDF1.4” is in the first 1024 bytes the PDF can still be opened in many viewers including Adobe Acrobat.
Figure 5 - Despite having a lot of text at the start of the file structure, the PDF can still be opened in Acrobat and many other PDF viewers.
You can even take that a step further and add a different file signature and associated data at the start of the file – as long as you can squeeze it into that first thousand bytes.
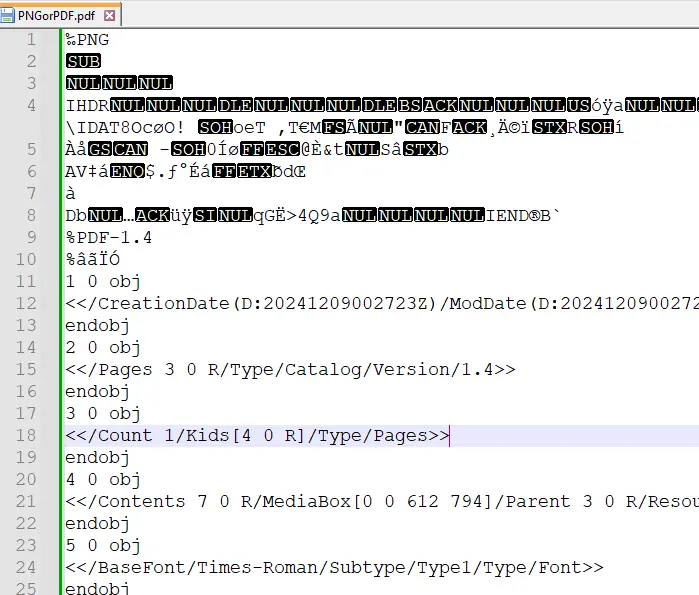
Figure 6 - An example of adding a PNG file into the same file as the PDF – although the data must all fit into the first 1024 bytes.
The file can still be opened as a PDF, but if you try to open it in something that understands PNG files, such as Microsoft Paint, then you can see the hidden image.
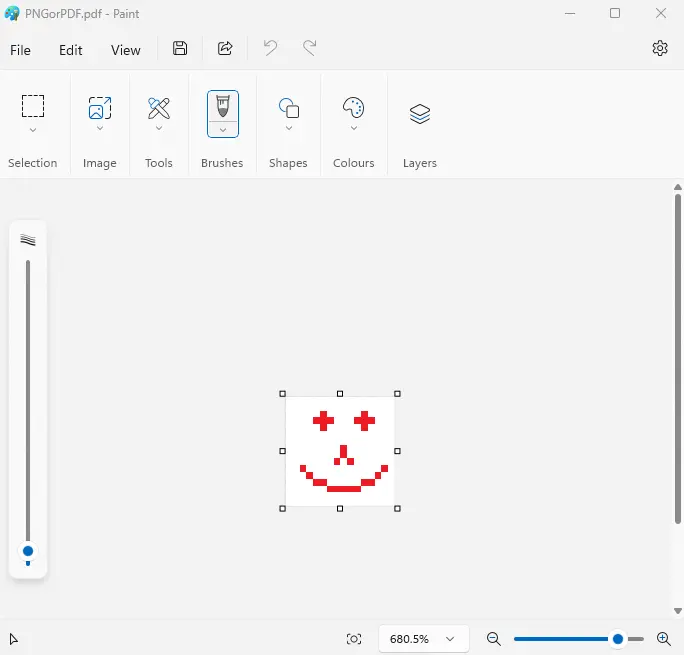
Figure 7 - The same file can be opened in a PDF viewer as a PDF, or if opened in MS Paint, then you can see the embedded image. You can see why I’m a writer and not an artist.
Myth 4 – The objects are immediately after the %PDF marker.
Just as we saw that the objects don’t need to be next to each other, it’s also possible for them to not start immediately after the %PDF marker.
We can even extend what we saw with Myth 3 and use this gap (or in fact in the gaps between objects) to put other information into the file.
One of the problems with putting things before the %PDF marker is that they have to be small – in order that the header is still within the first 1024 bytes. That’s not a limitation for things added after the header – they can be as big as you like.
As a simple example let’s add lots of text after the header and before the first object.

Figure 8 - An example of non-PDF content being squeezed into the PDF file structure. The PDF will still open in most viewers.
So far, what we have seen might be of interest, but it has little practical application.
However, we could embed data into the file so that the same file can be used in two separate, but valuable, ways.
DICOM is a widely used technical standard for storage and transmission of medical images, and it turns out that you can embed DICOM data into the file structure of a PDF and it can still be used.

Figure 9 - An example of a DICOM file embedded within the structure of a PDF.
This gives us a single file that contains both high-level medical information, accessible using a PDF Viewer, that is easily understood by the patient, and also imagery accessible using a DICOM Viewer that contains details intended for the medical practitioner.

Figure 10 - The contents of the file when seen in a PDF Viewer.
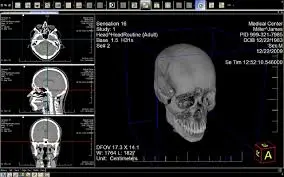
Figure 11 - The same file when seen in a DICOM viewer.
It is also possible to include the DICOM image as a separate file within the PDF, whether as an attachment annotation, an attached file or part of a portfolio.
Read more about the Three ways to embed files into a PDF using the Apryse SDK.
Myth 5 – The COS objects need to be valid.
Let’s look at another sample in this case the PDF is just intended to say “Hello Apryse!”
But let’s add random, but hidden, information into object number 6.
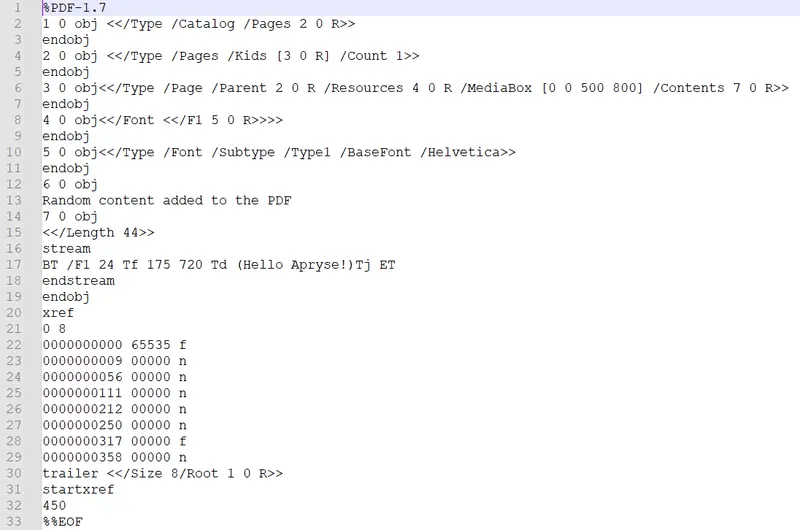
Figure 12- In internal structure of a PDF including an object containing spurious information.
Once again, provided that the xref locations are correct, the PDF can be opened in all common viewers.
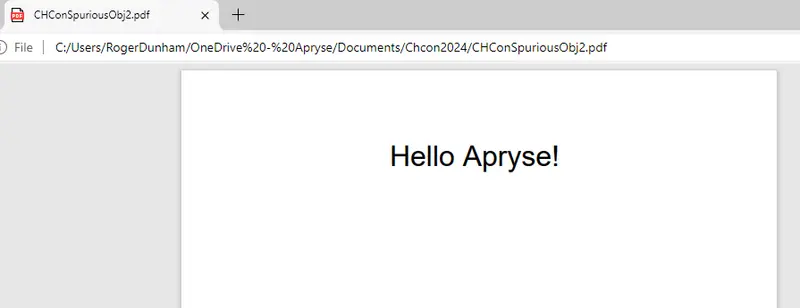
Figure 13 - the PDF will open in all common viewers including Edge.
In this case the object that I’ve edited isn’t even valid – there is text that isn’t in a stream, and there is not even an endobj marker works. How on earth does that not cause a problem?
There’s a hint to the answer within the xref table where object 6 is marked as ‘f’ indicating that it has been “freed”.
In fact, though, the PDF can still be opened even if the object is not marked as freed – that is because nothing is referring to it. Don’t take my word for it – try tracking the references.
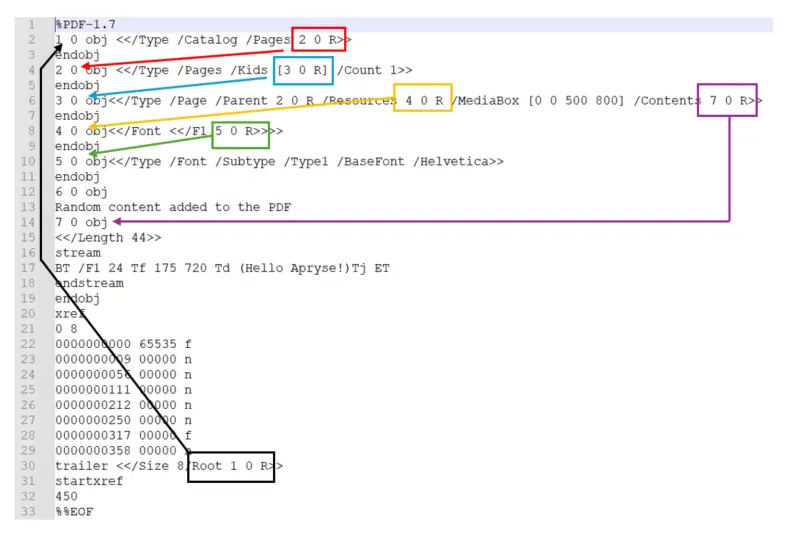
Figure 14 - If you track the references then you find that nothing is using object 6 - so the PDF can be rendered even though object 6 is invalid.
With nothing referring to the object the PDF can be rendered without ever having to deal with that bad object, so it doesn’t cause a problem.
In the previous article we looked at the various options that Apryse offers when saving a PDF. This unused object is a great example of where saving the file using SaveOptions.RemoveUnused, would be effective.
Suggested Read: PDF File Structure: Part 1
Finishing up
We started this article with a simplified image of the structure of a PDF. By now you should realize that it can be much more complicated. Not only might there be gaps in the file (such as LibreOffice creates), but those gaps might contain things that are not expected.
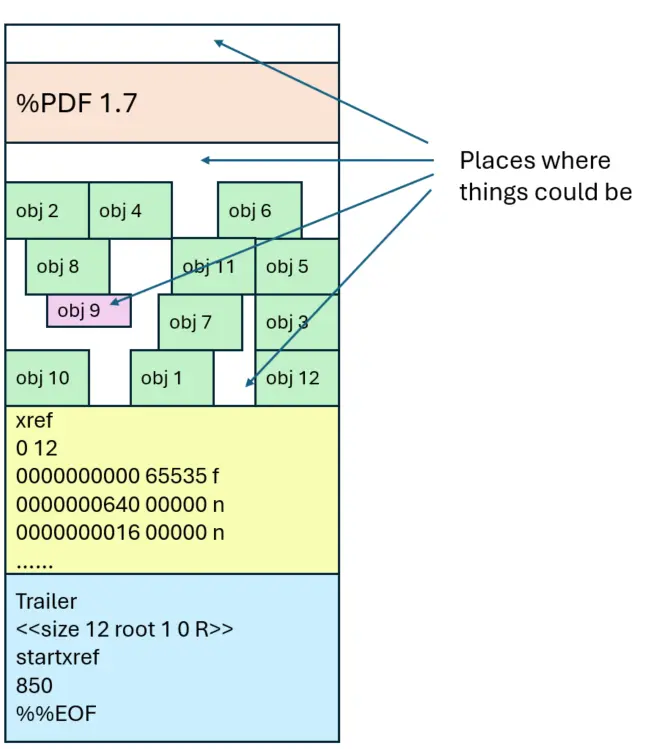
Figure 15 - A potential, but valid file structure, indicating gaps that might contain things. PDFs are potentially much more complex than some online articles suggest.
In this article we have only looked at benign (or in the case of DICOM, beneficial) things being inserted into the PDF. In reality though, malicious actors could potentially add malware into those gaps.
In the final part of this series, we will look at how the Apryse SDK can clean up files that might contain spurious objects and content, helping to keep you safe, while also providing a host of editing and other tools to save you hours when working with PDFs and other documents.