Garry Klooesterman
Senior Technical Content Creator
Published December 03, 2025
Updated May 18, 2026
3 min
Foundation First: Why Document Data is the Hidden Bottleneck to AI Workflows
Garry Klooesterman
Senior Technical Content Creator

Summary: Our new research reveals a critical AI readiness gap. While AI adoption is soaring, almost half of companies are blocked from scaling by the security and data quality challenges of unstructured document data, demanding a shift to controlled, intelligent infrastructure.
The buzz around AI is everywhere. From predictive models that forecast customer behavior to generative systems that create content, and agentic tools that automate decision-making, companies are deploying increasingly sophisticated technologies to streamline entire processes, from claims handling to contract analysis. It’s like building a high-tech, automated kitchen. But what happens if the plumbing is rusty and the water quality is terrible?
That’s the challenge organizations are facing today with enterprise AI. Our new report, AI Readiness 2025: Benchmarking Infrastructure, Strategy, and Scale, confirms that most businesses have achieved deployment, but they're hitting a wall when it comes to scaling. The reason isn’t a lack of budget or a shortage of data scientists. It’s the messy, complicated, and highly sensitive information that AI must consume.
Based on a survey of technical leadership across global enterprises, we’ve found that the biggest blockers to true, enterprise-wide AI scale lie not in the models, but in the foundational document infrastructure.
The Two Non-Negotiable Barriers
AI initiatives are failing to move beyond the pilot stage, not because of the complexity, but because organizations can’t compromise on the need for powerful automation with the requirement for absolute control.
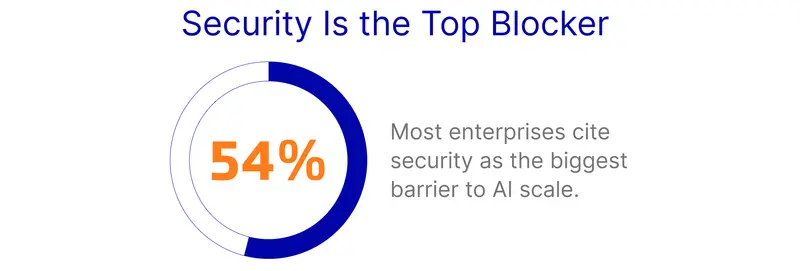
1. The Security Crisis: Data Sovereignty is the Biggest Blocker
When leaders were asked about the single biggest barrier to scaling AI, they didn't point to cost; they pointed to trust. Privacy and Security Concerns topped the list (54.0%) of roadblocks.
Enterprise data, such as contracts, financial reports, and health records, is too sensitive to trust to a black-box cloud API. Technical leaders are fiercely protective of their perimeters, and this caution translates directly into infrastructure demands. A staggering 67.3% of companies say keeping document data processing within their own infrastructure is "Extremely Important."

For those organizations in North America, this mandate is even higher, with nearly 79% demanding in-house control. This isn't just a preference; it's a fundamental requirement. Any solution that forces data to leave a secure environment before it can be parsed or structured is a non-starter for serious, regulated enterprises.
2. The "Good Enough" Data Trap
The second major barrier is the quality of the raw material (documents) itself. A massive 76.6% of enterprise data is stored in documents like PDFs, forms, and scanned images.

The problem: Only 38.1% of organizations rate their document data as "Excellent." The majority say their data is "Good," usable only with cleanup. When a human calls data "good enough," they compensate for the flaws. When an autonomous AI model encounters that "good enough" data, it interprets the inconsistencies as fact, leading to compounding errors. This is why over 62% of companies report that document quality issues frequently sabotage their AI or automation outcomes.
Accelerate your AI workflows by transforming documents into structured, trusted data with Apryse
The Engineers’ Roadmap: Structure Over Text

If data quality is the problem, what is the clear-cut solution? The answer lies in what technical teams are prioritizing for their next investment cycle.
Companies aren't looking for basic Optical Character Recognition (OCR) anymore. They're looking for intelligence. The most desired capability in document automation tools is Table and Form Recognition (53.5%).
Let’s look at the difference. OCR just sees characters where Table and Form Recognition sees the context. It knows that the numbers under the "Total Due" column belong to a specific transaction, adding the semantic structure that AI models require. This structure recognition is the key to transforming data, so it’s AI-ready.
Technical teams also demand tools that fit their engineering culture with Developer-Friendly SDKs ranking as a top priority. They want powerful components they can embed and control, allowing them to build secure, custom pipelines without relying on rigid, third-party systems.
The market has spoken, and it appears that the future of AI belongs to those who invest in this secure, intelligent, pre-processing foundation.
Ready to Close Your AI Readiness Gap?

The report provides an analysis of the readiness gap including detailed data on regional trends such as why Oceania is both the most AI-driven and the most concerned about data quality and how North America maintains its confidence lead.
Don't let your AI projects stall due to messy data or unnecessary security risks. The time to solve the input problem is now.
Download the full report, AI Readiness 2025: Benchmarking Infrastructure, Strategy, and Scale, to get a complete analysis of the readiness gap and learn about building a secure, scalable document-to-data foundation.
See Where Your Organization Stands: Read the Report Now!


