Garry Klooesterman
Senior Technical Content Creator
Published March 06, 2026
Updated March 06, 2026
3 min
Why Your Confident AI Pipeline is Probably Failing
Garry Klooesterman
Senior Technical Content Creator

Summary: Our initial AI Readiness research showed that AI adoption is hitting the mainstream, but our latest addendum reveals a startling paradox: while 95% of organizations feel confident in their document pipelines, over half of those same confident teams report frequent quality failures. Here’s why perception isn't matching performance and how to move from a false sense of security to a confident infrastructure.
The AI Readiness 2025 Report Addendum expands on the original dataset, diving deeper into the confidence vs. performance gap across document pipelines.
The Confidence Paradox
In our primary report, AI Readiness 2025, we established that the biggest blockers to AI scaling were security and data quality rather than models or budgets. But as we dug deeper into the data for our latest addendum, we found a bigger concern: the confidence gap.
There is a large disconnect between how technical leaders feel about their infrastructure and how that infrastructure actually performs.
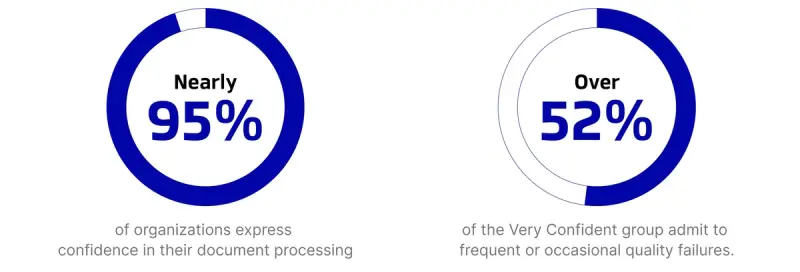
Nearly 95% of organizations express confidence in their document processing. On paper, everyone is ready for the revolution. However, when you cross-reference that optimism with actual performance, all is not what it seems. Over 52% of the Very Confident group admit to frequent or occasional quality failures.
Check out the original AI Readiness 2025 Report.
The Risk Multiplier Effect
For a developer or data scientist, this is a systemic risk. In human-centric workflows, we can forgive a messy scan or a misaligned table because our brains fill in the gaps. In an autonomous AI workflow, those minor flaws act as a risk multiplier:
Compounding Errors: A small error in document structure recognition (like misidentifying a header as a table cell) can lead to massive hallucinations in LLM applications.
Eroding ROI: When confident pipelines produce unreliable data, it forces expensive manual re-work, essentially negating the cost-savings of automation.
The Trust Deficit: Stakeholder trust can easily be lost due to failing pipelines, resulting in uncertainty for future AI investment.
Gaining Back the Confidence
To bridge this gap, technical teams need to shift their focus from adoption to integrity. It’s no longer enough to just have a pipeline. You need a pipeline that can handle the messy reality of enterprise documents.
Based on the survey data, leaders are now prioritizing three strategic shifts:
Automated Stress Testing: Move beyond subjective self-assessments. Teams are beginning to implement automated stress tests that measure actual error rates in data extraction before that data reaches the LLM.
Intelligent Pre-processing: Reliability starts at the source. This means moving beyond basic OCR to tools that understand Document Hierarchy.
Align Metrics with KPIs: Having objective Quality KPIs is the key and is achieved by building QA gates and validation into each stage of the document lifecycle.
How Apryse Stabilizes the Foundation
The addendum data highlights that quality issues stem from the unstructured nature of documents. Apryse’s SDK is built to normalize input files through deskewing, rotating, and handling complex multi-column layouts, ensuring that the data fed into your models is sound.
Our intelligent structure recognition understands the difference between a footnote and a header, or a checkbox and a bullet point. This level of detail is what turns a confident pipeline into a reliable one.
FAQ
How can my team be confident but still experience failures?
Confidence often comes from the fact that the pipeline works (the code runs), but failures come from the output (the data is messy). Many teams lack the objective KPIs to see that their successful extractions contain structural errors.
What is the difference between OCR and Structure Recognition?
OCR tells you what characters are on a page. Structure Recognition tells you why they are there. Knowing that a number is in the Total Due column is the difference between a usable data point and a random integer.
Can I fix my data quality issues without changing my LLM?
Yes. In fact, that is the preferred route. Most AI failures are actually data failures. Improving your intelligent pre-processing layer is often cheaper and more effective than switching to a larger or more expensive model.
Conclusion

The takeaway from our 2025 research is clear: The AI boom has met a bottleneck, and that bottleneck is document infrastructure. If you are part of the 52% experiencing quality failures despite a high-confidence setup, it’s time to look at your pre-processing tools.
Success in enterprise AI relies on building a secure, intelligent, and structured foundation.
Want to see the full breakdown of the data?
Suggested Reads
- Resource: Document Intelligence Toolkit for AI and Automation Workflows
- Blog: AI Is Mainstream, But Document Infrastructure Is Failing to Keep Up, Apryse Global Survey Reveals
- Blog: Foundation First: Why Document Data is the Hidden Bottleneck to AI Workflows
- Blog: C2PA and the Battle Against AI-Generated Deception


