Vimal Cherangattu
Published July 24, 2025
Updated May 18, 2026
5 min
How AI Powers Smart Data Extraction: A Deep Dive
Vimal Cherangattu

This blog unpacks the inner workings of Apryse’s Smart Data Extraction engine, how it’s built, trained, and optimized to deliver fast, private, and reliable document intelligence at scale.
Most document AI tools stop at surface-level text. They extract words, but miss meaning. They handle structure poorly, struggle with context, and can’t adapt to real-world complexity, especially at scale.
That’s where Apryse comes in.
What Is Smart Data Extraction, and Why It Matters
Smart Data Extraction is our modular, AI-powered engine designed to do more than scrape PDFs. It understands documents the way a human would: reading layout, interpreting relationships, and outputting clean, structured, AI-ready data.
In this deep dive, we break down how it works, how it’s trained, why it’s efficient, and why it’s built for full control, not cloud lock-in.
How It Works: A Hybrid AI Approach
“What sets Apryle's AI-based extraction apart is its unified approach that combines visual layout awareness with deep natural language understanding — transforming complex, unstructured documents into structured, human-level accurate data.”
— Hossein Khatoonabadi, AI Lead at Apryse
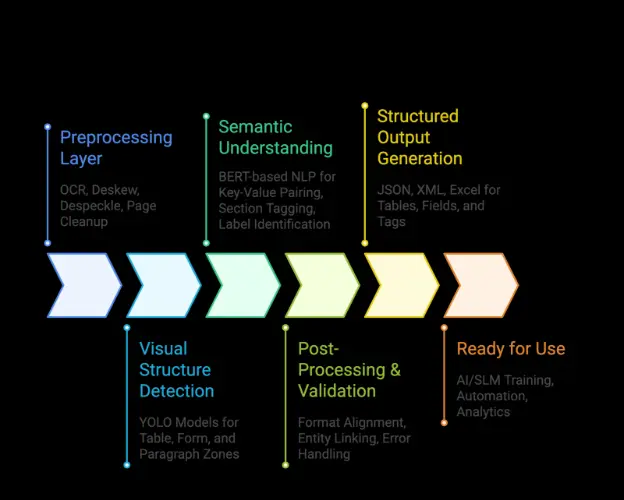
Smart Data Extraction combines computer vision and natural language processing to interpret documents the way a human would. It doesn’t just find words, it understands what those words mean, how they’re grouped, and how they’re presented.
Accelerate your AI workflows by transforming documents into structured, trusted data with Apryse
Key Models in Play:
- YOLO-based detectors handle visual tasks like form-field detection and table extraction, delivering speed and precision even in complex layouts.
- BERT-based NLP models power key-value extraction, merging layout and textual cues to identify structured relationships.
- Transformer architectures are being explored for classification and ICR (handwriting recognition) as part of our roadmap.
This layered architecture allows us to parse not just pixels or text, but full document intent.
Training with Real-World Data, Never Your Data
Each module in the system (tables, forms, key-values) is trained independently using task-specific data.
Rather than relying on massive synthetic datasets, we start with a large pool of real-world, non-customer, unlabeled documents. We then apply active sampling and other selection techniques to identify the most informative examples for manual annotation, forming a high-quality ground truth pipeline. This keeps training focused, efficient, and aligned with real-world complexity.
Models are retrained and fine-tuned continuously based on task complexity, data freshness, and edge case performance.
Efficient by Design: Built for Speed and Scale
Smart Data Extraction isn’t just accurate, it’s optimized. Our models are engineered to deliver high performance with low overhead, making them ideal for production environments where speed, cost, and resource use matter.
What Makes It Efficient:
- Minimal Resource Consumption: Our models require significantly less compute and storage than typical cloud-based alternatives: no GPU clusters or heavyweight infrastructure needed.
- Single-Shot Inference: We avoid multi-pass pipelines in favor of single-shot predictions, enabling fast, deterministic results with minimal latency.
- Consistent Throughput: Whether deployed on a laptop, a server, or a containerized cloud environment, our models deliver consistently fast and reliable extraction.
This level of efficiency translates into real-world advantages: quicker time to value, lower operating costs, and the freedom to scale or embed without compromise.
Why We Deliver It as an SDK, Not a Cloud API
Apryse doesn’t do black-box APIs. We give you full control with an SDK you can embed, run offline, and deploy anywhere. That means:
- No data leaves your environment
- Ideal for air-gapped and compliance-heavy industries
- Total integration freedom: on-prem, private cloud, or hybrid
This is particularly important for healthcare, legal, and government use cases where privacy isn’t optional, it’s mission critical.
Where It Shines: Built for the Rise of SLMs
Small Language Models (SLMs) are domain-specific, lightweight alternatives to LLMs and they depend on clean, structured training data.
That’s where Smart Data Extraction shines: transforming messy, unstructured PDFs into training-grade JSON with labeled fields, tables, and semantic metadata. No manual tagging. No templating required.
Whether you're training internal models or powering downstream analytics, our AI gets your data model-ready, quickly and reliably.
Why It’s Different
We consistently outperform leading cloud-based tools , without sending a single byte outside your stack.
Apryse’s Smart Data Extraction isn’t just another document parser. It’s a deeply integrated AI engine, built for developers, optimized for compliance, and designed to power automation, analytics, and AI pipelines with zero compromise.
Don’t settle for shallow extraction. Get in touch with us and get started with true Smart Data Extraction.
Suggested Read: Turn PDFs into structured data for AI document analysis
Frequenctly Asked Questions
1. What types of documents does Apryse Smart Data Extraction support?
We support a wide range of document types, including PDFs (native and scanned), DOCX files, image-based documents, forms, tables, and contracts. Our system is designed to handle both structured and semi-structured layouts.
2. Does Apryse use customer data to train its models?
No. We never use customer documents for model training. Our models are trained using a curated pool of real-world, non-customer documents, enhanced through active sampling and manual annotation to build high-quality ground truth data.
3. How does Apryse’s solution compare to cloud-based tools like AWS Textract or Google Document AI?
Apryse offers SDK-based deployment, giving you full control over where and how the AI runs. Unlike cloud APIs, we don’t send your documents over the internet, making us ideal for regulated industries. We also deliver comparable or better accuracy, with faster inference and lower resource consumption.
4. Can I deploy Apryse’s extraction engine on-prem or in an air-gapped environment?
Yes. Apryse is built for on-premises, private cloud, or fully air-gapped deployments. You maintain complete control over data residency, infrastructure, and compliance.
5. Is it customizable for domain-specific formats like insurance claims or legal contracts?
Absolutely. Each module (tables, forms, key-values) is trained independently and can be fine-tuned using customer-provided templates or annotated examples—no ML expertise required.
6. What output formats does Apryse support?
We support structured JSON, XML, Excel/CSV, HTML, and XFDF/FDF outputs—ideal for integration into downstream analytics, RPA, AI training, or compliance workflows.
7. How often are the AI models updated?
We update models on a rolling basis depending on task complexity, data freshness, and performance on edge cases. This ensures our extraction remains reliable across evolving document types and layouts.
8. Does Apryse support Small Language Model (SLM) training?
Yes. One of our core strengths is providing clean, structured, labeled data that can feed directly into SLM training pipelines—especially for use cases like summarization, classification, or RAG systems.


