Roger Dunham
Published March 14, 2024
Updated May 18, 2026
8 min
Demystifying JSON: A Comprehensive Guide for Developers
Roger Dunham

Introduction
JSON (JavaScript Object Notation) is a lightweight data interchange format that’s easy for humans to read and write and machines to parse and generate. It’s based on a subset of the JavaScript programming language and is commonly used for transmitting data between a web server and a web application, as an alternative to XML.
Beyond that, it is also used as the format for config files in many programming languages (e.g., JavaScript/Node.js, Python, and Go). Within Apryse, it is the data format used by the Apryse IDP (Intelligent Document Processing) module which we will look at later in this article.
First, we will look at what JSON is and its benefits compared to the alternatives.
The JSON Format
JSON is defined in the standard ECMA-404. But as a quick overview, it is UTF-8 text based (so it can handle all Unicode code points, rather than being limited to Latin language characters). In addition, being self-describing is great for use with unstructured data.
While based on, and commonly used with, JavaScript (it’s what the J in JSON stands for), it is a language-independent data format, making it great for exchanging data between different systems.
It is also very simple, being built on just two structures:
1. A collection of key/value pairs
2. An ordered list of values
The values in the collections and lists can be any of the following supported data types:
- Objects: Unordered collections of key/value pairs. Objects begin with { (left brace) and end with } (right brace). Each key is followed by : (colon) and the key/value pairs are separated by , (comma)
- Arrays: Ordered lists of values. Arrays begin with [ (left bracket) and end with ] (right bracket). Values are separated by , (comma)
- Strings: A sequence of characters wrapped in double quotes (")
- Numbers: Integers or floating-point numbers
- Boolean: true or false
- Null: A special value representing null or empty
Wow, that was a bit complex! Let’s make it a bit clearer by looking at an example – the JSON representation of a developer working for a tech company.
Even without any further information, it is easy to work out that Jane Wordsworth (a string) is 25 (a number) years old and is an employee (a Boolean) who knows three programming languages (an array). Her address (an object) is 123 Main St, Anyville.
And that’s the great strength of JSON – it is simple and intuitive, yet powerful and relatively compact.
What Are the Drawbacks of JSON?
JSON has three major drawbacks:
- Lack of Comments
- Lack of Type Safety
- Lack of Support for Complex Hierarchical Data
Lack of Comments
Arguably the greatest weakness of JSON is that it does not support comments. But that was a deliberate design decision to make parsing easier.
Comments might not matter when JSON is being used to transfer data from a server to a web page, but lack of them is inconvenient if it is used for a config file.
For example, in the following snippet, wouldn’t it be useful to know why the coordinateSystem of originTop was chosen? A comment could avoid the need to search for documentation.
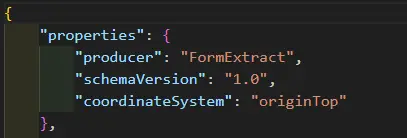
Figure 1 – A snippet of JSON: Comments would have made the intent clearer but are not available in JSON.
Lack of Type Safety
Since all the values are represented as strings, it is easy for typos to be included in a manually generated file. With no built-in mechanism to verify the structure, the errors may not be identified until a failure at runtime. And failures at runtime always happen when you are busy and have other things to do.
Of course, if the JSON is generated and consumed by a program, without manual editing the risk is reduced even if it is still not zero.
Lack of Support for Complex Hierarchical Data
The very simplicity of JSON is also a weakness. Complex hierarchical data is not easily handled. As such, if there is a need to represent documents that contain rich formatting and metadata, a more sophisticated format like XML may be better suited than JSON.
What Are the Alternatives to JSON?
There are clearly many formats that could be used depending on what is needed. However, if we look primarily at methods for transferring data, three major formats exist:
- XML
- CSV
- Binary
XML: Extensible Markup Language
XML is a text-based markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable.
Like JSON, it is self-documenting and has the benefit of supporting schemas so that data integrity can be checked (providing a level of type safety). Another benefit is that with the use of XSL transforms, it can easily be converted into an alternative format for viewing in a browser, for example (although modern browsers cannot do that directly from the file system for security reasons).
If we consider our developer example from above, in XML the data would potentially look like this:
You can see that XML is verbose – this is a double-edged sword. On one hand, the data can be self-describing and support attributes and comments. On the other hand, the verbosity can make the data hard to understand, and increases bandwidth requirements, which may be an issue in some scenarios.
CSV: Comma Separated Values
CSV is another text format and is great for simple tabular data. Each record in the table is converted to a single line in the CSV file. While the “C” in CSV stands for comma, the delimiter can, in reality, be another character provided that the program using the data understands what the delimiter is. That has a practical use if you are dealing with numbers where the decimal separator is a comma, which is common in many European countries.
However, understandability is a major disadvantage of CSV. Let’s consider our developer data:
"Jane Wordsworth", 25, true, ["C++", "JavaScript", “C#"], "123 Main St, Anyville"It is easy to work out that “Jane Wordsworth” is probably a name. But what do the 25 and true indicate? Without knowledge that is not included in the file, it really is anyone’s guess, and guessing is not the way to software success.
Binary Formats
There are hundreds of binary formats that could be used to transfer data. They are compact and memory efficient, and they can be extremely fast to process using pointer-based programming languages.
The downside, though, is that they are entirely unreadable to humans. Technology will get faster. Humans probably won’t, so having a human-friendly (text) format in most scenarios will be better than a binary one.
JSON and Apryse IDP – Intelligent Document Processing
Apryse IDP uses Artificial Intelligence (AI) to understand what the content of a PDF, even a scanned PDF, is.
At one level, IDP can be used to extract tabular data from the PDF and place that into an Excel spreadsheet, saving hours of manual work.
IDP can, however, do much more. For example, it is possible to get the content and structure of a document, or to get the content and labels from a PDF-based interactive form and store it in JSON format.
There is some great sample code for extracting document structure that illustrates the power of IDP. Before running the sample, though, you will need to download the Data Extraction Module, which is an add-on to the Apryse SDK. If you forget to do so, don’t worry, the sample code will remind you that it is required.
IDP has the ability to not just recognize text but also to identify headers, footers, paragraphs, and the reading order. It also stores the coordinates of those elements as well as tables and images.
Let’s look at an example of how this works. The following file is from the Apryse Showcase but you can download it directly.
The notable parts are the list items, bolded text, and various paragraphs.

Figure 2 – Part of the PDF we want to extract structure and content information from
The essential line within the sample code is “ExtractData”.
DataExtractionModule.ExtractData(input_filename.pdf, output_filename.json, DataExtractionModule.DataExtractionEngine.e_doc_structure);When this is called, it creates a JSON file that gives us not just the location of each paragraph, but also correctly identifies that some of the paragraphs are list items, and that some of the text has a higher weight font than other parts.
Typical output is shown below:
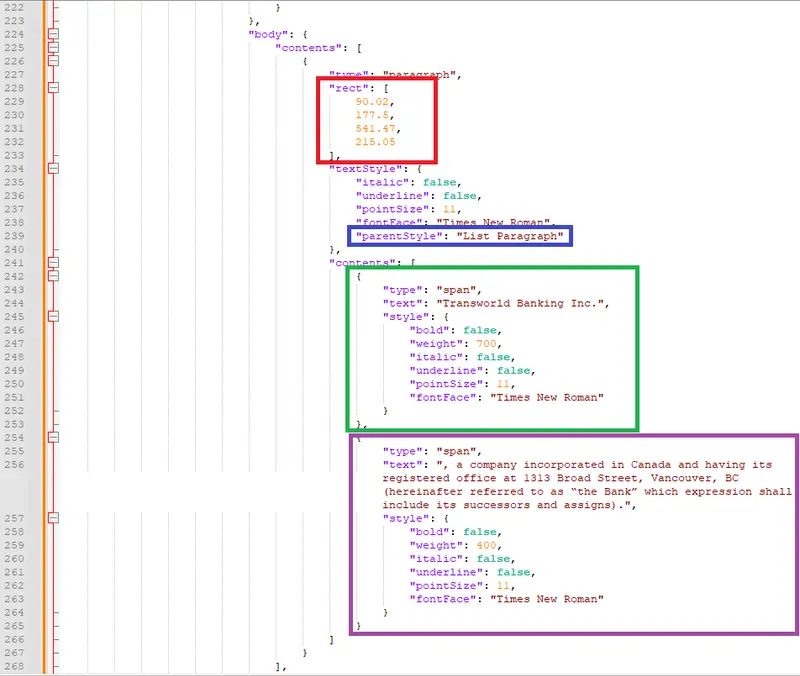
Figure 3 – Typical output in JSON of extracting the structure and content of a file. A paragraph’s location is shown (in red), that it’s a list paragraph (in blue), the bold text (in green), and non-bold text (in purple).
There is a slight gotcha in the file – bold text may be shown as having a high “weight” (in this case 700), rather than "bold” being true, since boldness is not necessarily an attribute of the font that is used.
If that was an issue for you, there is an easy workaround. Since the generated file is JSON, it is easy to update the text in this file to set the bold attribute based on whatever rules you require (e.g., weight >600). Attempting to update a binary file in the same way would have been all but impossible.
What you do next with the data is up to you. For example, you might want to republish the information in another application, such as a mobile viewer. In that case, the content of this JSON file would be a great starting point to generate the modified document layout required for the screen size and orientation, used on many mobile devices.
Conclusion
JSON is a well-known standard data format, which is easy to read and modify, and which can be easily generated and consumed by software.
Coupled with the power of Apryse IDP it can be used as a way to get the content and structure of documents, allowing you to leverage knowledge within your applications.
If you have questions about IDP or the JSON file format, please reach out to us on Discord.