Roger Dunham
Published September 25, 2024
Updated May 18, 2026
4 min
Coordinate Systems When Working With PDFs
Roger Dunham
Summary: This article explains the importance of coordinate systems for developers working with PDFs and WebViewer, highlighting how errors can lead to confusing UIs and incorrect document processing. It covers key systems and how to convert between them.
Introduction
The intricacies of coordinate systems are not a thing the average software user needs to know anything about – a good PDF viewer and editor, such as Apryse WebViewer, just works in an intuitive way, with all of the detail being dealt with under the hood.
As a developer, though, coordinate systems matter a great deal – getting it wrong can result in a difficult-to-understand UI, as well as incorrect output for any kind of automated document processing.
In this article, we will look at the main coordinate systems that you will come across when working with PDFs and WebViewer, and see how you can correctly convert between them.
Things You Need to Know about Coordinate Systems in PDFs
Working with the Extracted Data
Apryse IDP allows you get both content and location of information within a PDF. Correctly understanding the location makes it possible to identify which pieces of data are located near one another, or near to an edge of the page.
Working with Annotations
Annotations can be embedded within a PDF or exported as a separate file that is then loaded into the PDF. If the coordinate system used by the annotation is incorrect, then it will appear in the wrong location.
Adding a Custom Tool to WebViewer
Somehow you need to convert from the location of a click event within the UI to, for example, an element within the PDF.
Before we look at those examples, let's go into a little detail about coordinates in PDFs. We’ll break this into three sections:
- Things that you probably don’t need to know but might find interesting
- Things that you do need to know
- Things that you need to know if you are in a hurry
Things You Don't Need to Know
The PDF Specification is full of detail, which it should be. In practice, though, if you are using WebViewer, then most of those details have been handled for you.
They do provide some useful background and concepts, so if you are curious, then read on – but I will keep it brief.
I’ve heard about various “boxes” with regard to PDFs. What are they?
Some articles about PDFs use phrases such as “Crop boxes,” “Bleed boxes,” “Trim boxes,” “Media Boxes,” and so on. In almost all scenarios there is little need to know about these. Certainly, there are some niche cases when it matters, and if you find yourself needing to find out more or you are just curious, then check out the PDF specification or the article “What are PDF Page Boxes?”.
Coordinate Systems
The PDF Specification says, “Coordinate systems define the canvas on which all painting occurs. They determine the position, orientation, and size of the text, graphics, and images that appear on a page.”
It then goes on to talk about Coordinate spaces. These define the detail of how a pair of coordinates specify the location of a position. The essential parts are:
- The location of the origin
- The orientation of the x and y axes
- The lengths of the units along each axis
Device Spaces
The ultimate intention of creating a PDF is that it will be viewed or printed somewhere, whether that is on a monitor, a phone, a low-quality printer, or some high-resolution printer.
My monitor, for example, has a resolution of 96 pixels per inch, so a line 10 inches long would be 960 pixels in length.
A printer such as the Epson SureColor P700, on the other hand, which has a maximum resolution of 1440 dpi, would print that 960 pixel line as only 0.7 inches long. In fact, it’s more complex than that since the printer has a different resolution in the x and y directions – up to 5760 dpi – meaning that the length of the line depends on whether it is across or along the page.
Coordinates specified in device space are, therefore, not very useful for most people. Thankfully, the underlying operating system deals with that, and most users don’t need to know much detail about it.
User Space
The alternative to device space is User Space which a device independent coordinate system that always gives the same relationship to the current page, regardless of the device on which the PDF is displayed or printed.
The Default User Space has an origin at the bottom-left of the page, with the x-axis increasing horizontally to the right and the y-axis increasing vertically upward – if that sounds confusing, it is exactly the way that you would normally draw a mathematical graph using Cartesian coordinates.
We saw that for some devices (such as the high-end printer), the units used on the x and y axes can be different. That isn’t possible in User Space, though, with the length of the unit on both axes being specified via the optional UserUnit entry in the page dictionary.
UserUnit is measured in multiples of 1/72 inch, with the default value for this is 1.0 and a maximum value of 75000
In reality, very few PDFs specify a value for User Unit, so the default of 1 is used.
Fun Fact: if you set the UserUnit to 75,000, then each UserUnit is about 26 meters. With the maximum PDF size being 14400 x14400 UserUnits, you could, therefore, create a PDF that is about 381km square, which is about half the size of Germany.
Transforming Between Spaces
At some point, there is a need for the PDF to be printed or displayed – at that time, it needs to be converted from User Space to Device Space. That is done using a Transformation Matrix (typically the one specified with the cm operator which then becomes the current transformation matrix).
At its simplest, the transformation matrix can just be used to scale and translate points from one coordinate system to another – but the mechanism can easily be extended to also allow rotation and skewing.
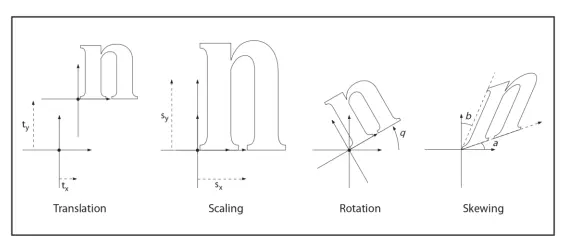
Figure 1 - Effects of coordinate transformations - taken from ISO32000-2:2020
The possible uses for transformation matrices go beyond just converting from Default User Space to Device Space – they can also be used to transform between other coordinate systems. One example of this is to embed a large image into a PDF, then use a transformation to make it smaller, and fit it into a specific location on the page.
Things to Know
So far, we have looked, albeit briefly, at coordinate spaces, transform matrices and so on. If you are feeling overwhelmed there is no need to worry – you mostly don’t need to remember the details.
Coordinate Systems in WebViewer
Multiple coordinate systems are also present when viewing a PDF within WebViewer.
PDF Page Coordinates are the same as those defined in the PDF specification, and have the origin as bottom-left.
PDF Viewer Coordinates are closer to the way that people actually read documents - from the top downward. The origin is therefore top-left,d to know is how such things affect the way that you work with WebViewer.
And it all gets more complex if the PDF is rotated. Clearly, we need a way to Get and Convert PDF Coordinates.
As an example, let's look at a publicly available PDF – the Amazon-10K form for 2023.
In fact, we will just look at one particular page (page 56) from it. There’s nothing special about that page – I chose it because it has a mix of text, table and white space, which will illustrate coordinate systems well – but you could do the same with any other document.
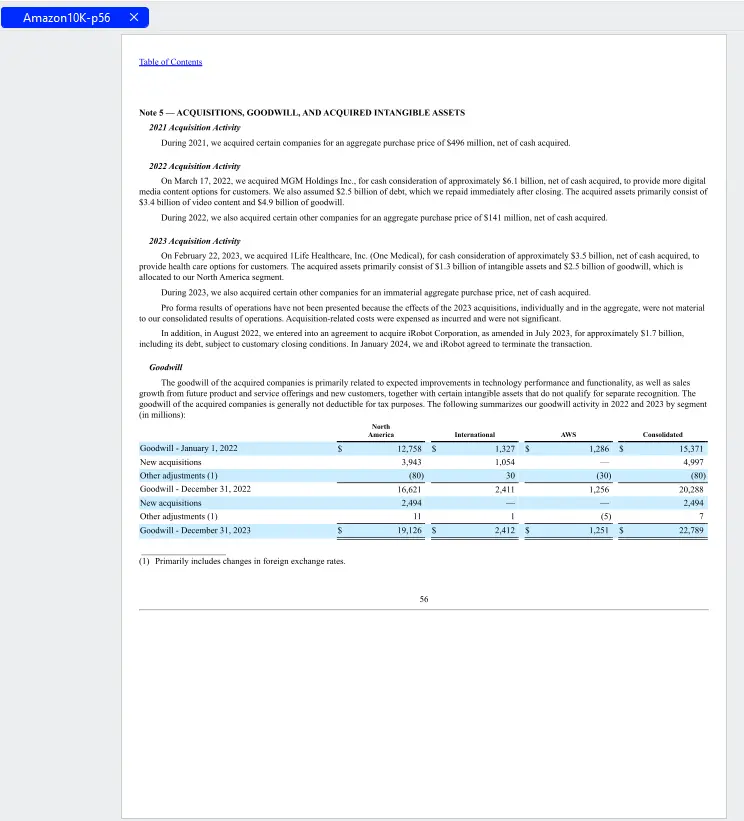
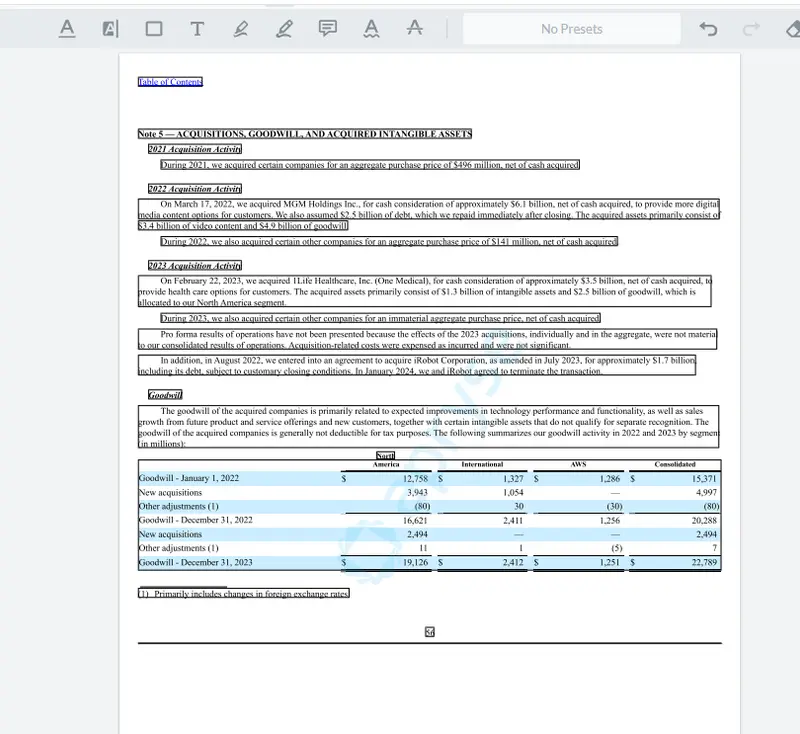
Figure 2- A sample document - Page 56 from the Amazon 10K for 2023.
Let’s get the locations of elements in the PDF. We can do that by modifying the ElementReader sample so that each time a text element is found in the PDF content its location is written to a file.
Note that even for our single page this will create a lot of output (and we will see why that is an issue in a few minutes).
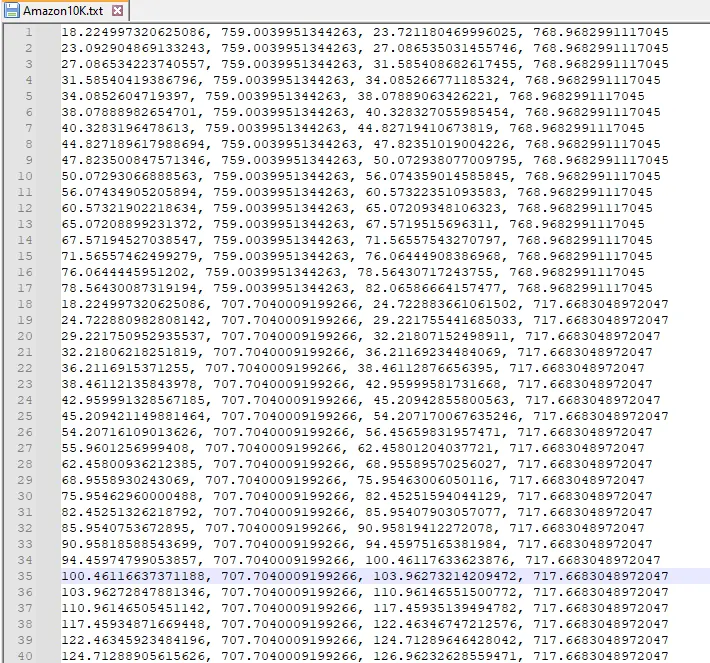
Figure 3 - Part of the file containing the locations of text elements in our sample PDF.
These locations are based on PDF Page coordinates. You can see the Y value - the second number - of the first row is more than 750, even though that relates to the top of the page. That is because the origin of the coordinate system is bottom-left.
Let’s use those locations to create annotations within WebViewer. They should then appear on top of the text that they relate to.
That all seems very intuitive – but when we run that code and load the PDF with the new annotations, it looks terrible!

There are two problems here, but let’s fix the first one first. – the content locations are upside down.
The issue is that annotations when created in WebViewer use Viewer page coordinates (where the origin is top-left).
You could manually create a function to adjust the locations – but there is already an API that does that for you. GetViewerCoordinates() takes PDF Page coordinates and converts them into Viewer Page Coordinates.
If we run that code again, the annotations are now in the correct location.

Figure 4 - After using getViewerCoordinates() the annotations are correctly located.
That leaves us with the other problem – there is just too much information, and in too small lumps. That is common when working with PDFs at a low level. The underlying issue is that many words and sentences in the PDF are specified as individual characters, resulting in huge amounts of data that must be parsed and handled.
It’s not a coordinate system problem, but solving it illustrates another aspect of coordinate systems. Thankfully, the clever Engineers at Apryse have made it easier to understand the content of PDFs by creating tools that take the raw PDF content and join it into something more meaningful.
Let’s use the Data Extraction module to get the page content. There are some notable differences from just reading elements. In addition to combining the individual characters into paragraphs, it also creates JSON output and has a default co-ordinate system based on the top-left of the page.

Figure 5 - The start of the generated JSON file. You can see the coordinate system in green, the location of the first paragraph in blue, and the text of the paragraph in red.
Now let’s use those coordinates and create annotations from them:
That works a treat – since the output of the Data Extraction module uses Viewer Coordinates which is the same used when creating Annotations there is no need to do any kind of transformation.
You can see that we have solved the second problem too – the annotations now show the locations of entire paragraphs and tables – improving your understanding of the PDF content.
Exporting Annotations
So far, we have created the annotations in WebViewer. It is, however, also possible to import (or export) annotations from (or to) a file or database in XFDF format.
Let’s look at the simplest way of exporting them – just using default options.
var anns = await annotationManager.exportAnnotations(); If we run that code, then the annotations are exported in PDF Page Coordinate space. If you were to parse this file and create new annotations from their reported locations, you would need to convert them back into Viewer Page Coordinates.
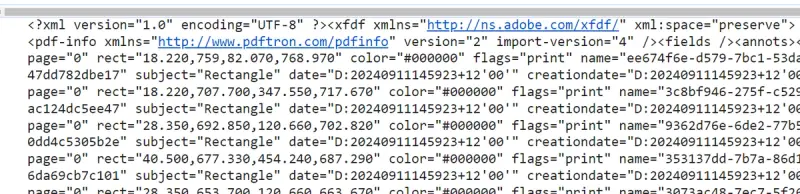
Figure 6 - the result of logging the exported annotation stream. Note that the coordinates have an origin at the bottom left.
In practice, there is an easier way of getting the annotations in their correct place in the PDF. If you use annotationManager.importAnnotations() then this will automatically convert between the two coordinate systems, making the creation of annotated documents seamless.
Working With Mouse Coordinates
The final area that we will look at is when we are dealing with user-initiated events. As an example, let’s consider a mouse click – which could be the first part of a process for measuring or drawing something.
When a mouse click occurs, it is possible to access a wide range of information
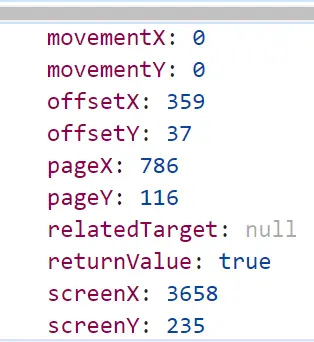
Figure 7 - Typical result from logging a mouse click event - there’s lots to choose from!
Unfortunately, it’s not intuitive how you use those values to calculate where the click event occurred on the page – having to do so manually would involve needing to know the location of the browser within the screen, rotation, zoom levels, and a range of other values.
Once again, the Apryse Engineers have created an API to simplify your life – taking the native event which is triggered when the mouse is clicked, and returning the location of the click relative to either the top-left (if you use getViewerCoordinatesFromMouseEvent), or the bottom-left (if you use getPDFCoordinatesFromMouseEvent).
You can then use those coordinates to add an annotation, or extract content at that specific location. Awesome!
Important Takeaways
There are two main coordinate systems that you need to be aware of when working with PDFs in WebViewer
PDF Page Coordinates: Have the origin as bottom-left.
Viewer Page Coordinates: Have the origin as top-left.
You can convert from one to the other using either
getViewerCoordinates() or getPDFCoordinates()
These functions work on a page by page basis, and take into account differences in page size and orientation.
Mouse coordinates can be converted into PDF Page and Viewer Page coordinates using getViewerCoordinatesFromMouseEvent() and getPDFCoordinatesFromMouseEvent().
Conclusion
Coordinate systems, in both PDFs and their viewers are technically complex.
However, if you are using Apryse WebViewer (or other Apryse SDK tools) then much of the complexity is removed, creating a development platform where you can quickly get to market – focusing on the parts of the problem that are specific to your business, and leaving the details of coordinate transformations to be handled with little or no effort on your part.
The best way of learning is by doing, so get yourself a trial license for Apryse WebViewer, check out the documentation and try out the samples to get started quickly. There’s also lots of blogs and videos to help you on your way. But if you do run into problems then reach out to us on Discord and our friendly Support Engineers will be happy to help.