Roger Dunham
Published August 23, 2024
Updated May 18, 2026
4 min
Header and Footer Extraction: Converting PDFs to DOCX on the Server Side
Roger Dunham
The Apryse SDK is a fully featured library for working with PDFs and other documents. It can view, edit, redact, or convert files from one format to another, as well as perform a wide range of other document processing capabilities.
One of the many areas in which the Apryse SDK is far ahead of the competition is in its ability to convert a PDF into an Office document. To help showcase this feature, we will use a publicly available PDF. There is nothing special about that document, it just contains nice examples of headers and footers.
While it is definitely possible to edit PDFs directly and can even be done using WebViewer, making many changes would be difficult and slow. Office documents, on the other hand, are easy to edit, and editors can add and update Tables of Contents, Page Numbers, and Numbered Lists, to name a few.
Structured output (an add-on module for the Apryse SDK) performs the actual conversion from PDF to Word (and also PDF to Excel, PDF to PowerPoint, and PDF to HTML).
It automatically identifies the actual content of a PDF page compared to the headers and footers. It then reassembles those parts into the DOCX file.
Previously, it has not been (easily) possible to modify the way the headers, footers, and body content are used to do this. While the default option was, very often, ideal, there was no option to make a different choice in those scenarios where something else was required.
In this article we will discuss what headers and footers are, what they are for, and how the new options affect the generated output.
What are Headers and Footers?
Headers and footers are sections at the top and bottom of the page that contain information related to the page or document—typically the title, the author’s name, the page number, or the date—although a wide range of other options are possible.
While the same header and footer may be used throughout the entire file, it is common to have different headers and footers on odd and even pages. It is also common for there to be no header or footer at all on the first page. Furthermore, as the document progresses, the headers and footers may also change, perhaps to indicate the start of a new chapter.

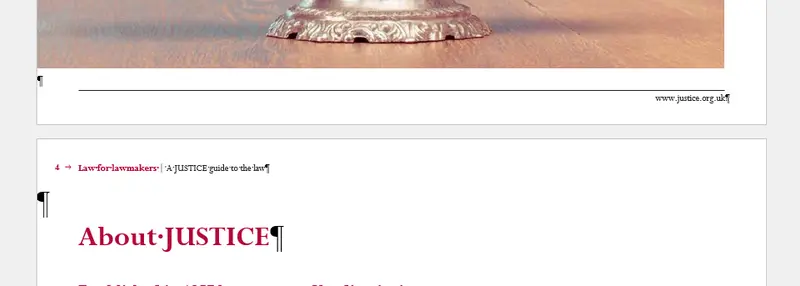
Figure 1 - An example of headers and footers. The odd pages (on the left-hand side) have an image and page number as a header, and a horizontal line and a link to a website as a footer. The even pages (on the right-hand side) have a page number and title as a header, and just the line as the footer.
Headers and footers help the reader to understand what the document is about: who wrote it, what it is called, and where they are in the document. Furthermore, they also help to give the document a consistent and professional look.
But the thing is, they are not part of the content of the document and including them in the content of the document could be very confusing.
Detecting Headers and Footers
Detecting what is, and what is not, a header or footer is complex.
It is trivial to find simple cases where header and footers are easy to identify. However, when working with real-world documents, you will soon come across somewhere the distinction is less clear.

Figure 2 - As a human you might be able to tell whether the first and last paragraph in this document are a header or footer, or whether they are part of the general flow of the document. However, creating generic rules that work in all cases is extremely difficult.
Historically, part of the detection algorithm required that similar text had to be present on multiple pages before it would be considered as a possible header or footer. As such it was, by definition, impossible to detect headers and footers in a single page document. However, now it's possible to detect headers and footers even on a single page document.
Identifying what is a header and footer is only part of the puzzle, it is also necessary to decide what to do with them after they have been detected.
How does the Apryse SDK Handle Headers and Footers?
The default option, when converting to Word, is for the headers and footers to be converted into Header and Footer objects within the DOCX file.

Figure 3 - Headers and Footers within the reconstructed DOCX file
That is usually a great result. Assuming you are familiar with how to use headers and footers within Word, you can now quickly benefit from their functionality. If you make a change to a header or footer in one place, then it will propagate throughout the entire file. What’s more, if you add extra pages into the document, then the page numbering will also update in the headers and footers further down the document. Trying to do the same operations directly within the PDF would be much harder.

Figure 4 - The same DOCX, after two new pages have been inserted earlier in the document, and the footer has been edited. The resulting edits propagate through the document automatically.
Finally, if you add more text to a page, then the text will flow onto the next page, but the footer will remain in the same place.

Figure 5 - Adding more text to a paragraph may cause the page to overflow. The headers and footers, however, have remained in the correct location.
For the vast majority of documents, the default option works extremely well. However, in a few use cases it would be helpful to be able to handle headers and footers in a different way. As such the ability to do so has been made available.
What are your Options for Dealing with Headers and Footers?
Recover
This is the default option - identify the headers and footers and convert them into headers and footers in the generated DOCX file. For many users, as we have seen, this is exactly what they want.
DoNotDetect
No attempt is made to detect the headers and footers, and they are just considered to be part of the general flow within the document.
Superficially, this will look the same as with the default option. However, now if you edit the ‘footer’ on one page, only that single instance is modified, as such if you want to change all the ‘footers’ then you need to edit every page.
Since the footer from the PDF is now considered to just be ordinary text, if you were to add new pages to the document, as we did in the previous example, then, now, any page numbers will not update.
Furthermore, if text is added within the page, then the footers can end up being pushed onto the next page.

DetectAndRemove
The final option is detect and remove, which means that the headers and footers in the PDF will be identified but will not be present at all in the final DOCX file.

Figure 7 - The effect of removing headers and footers when viewed in a .DOCX file.
This can be useful if you want to use the .DOCX file as an intermediate processing step, or intend that the document will be read aloud by assistive technology, and you don’t want the headers and footers to be part of the general reading flow of the document.
A related issue would occur if you were exporting to a ‘reflowing’ format such as a .TXT file, since once again you would not want the headers and footers scattered throughout the document content. Let’s look a little further through our example PDF to a place where there is a header and footer between blocks of body text.

Figure 8 - An example of 'body' text, as well as header and footers.
What we want is to get the body text and ignore the footer and header. However, with default options the result is not what we want.
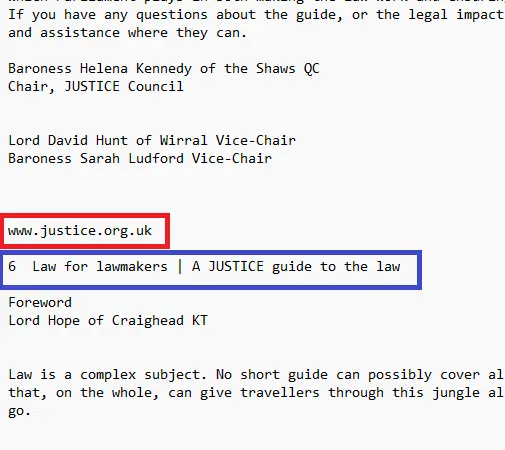
Figure 10 - When converting into a .TXT file, the default option keeps the footer (in red) and the header (in blue). In reality you probably want neither.
You may even want to remove the existing headers and footers simply because you intend to replace them with something else when you are editing the document within Office.
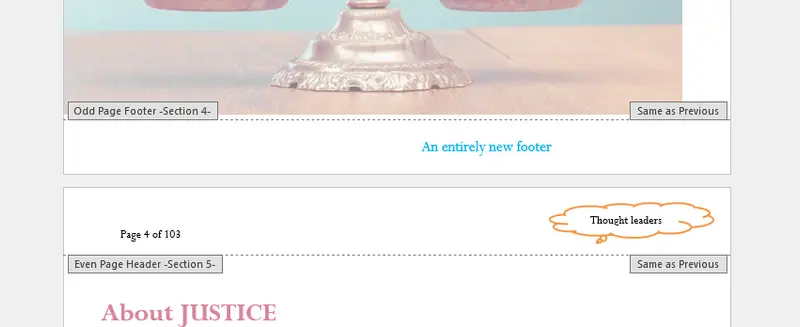
Figure 11 - Having removed the original headers and footers, you are still able to add new ones.
Whatever your requirement, we give you the ability to make the choice.
How to Specify the Headers and Footers Option
Specifying the required header and footer option is a breeze. The details vary slightly between programming languages, but the essential details are the same. All you need to do is create (or use an existing) wordOutputOptions object and specify the value via SetHeadersAndFootersSetting.
In fact, you can perform the entire conversion in just a few lines of code.
Wow, that really is easy for world-class PDF to Word conversion!
Next steps
What are you waiting for? Get yourself a trial license and download the SDK for whichever language and platform that you want. The SDK comes with lots of samples, including one, PDF2OfficeTest, that uses code very similar to that which I have used. There is also lots of documentation, not just for converting from PDF to Office, but also for all the other functionality that is supported.
Try it out and see how much time it could save your company when you need to convert a PDF into DOCX format.
Don’t forget, you can also reach out to us on Discord if you have any issues.