John Chow
Product Manager
Published June 20, 2023
Updated March 09, 2026
4 min
How to Extract Data from PDF Using Apryse SDK and Java
John Chow
Product Manager

In this tutorial, we will explain how you can use the Apryse SDK and Java to extract data from PDFs. You will learn how our Intelligent Document Processing (IDP) add-on allows you to extract text, tables, and forms data accurately and programmatically from PDF documents such as invoices, purchase orders, reports, and much more.
PDF Data Extraction Use Cases
For modern document workflows, automating PDF data extraction tasks is becoming essential. For the wealth of business documents that commonly use the PDF format, there are many use cases where accurately recognizing and processing their content is desirable. For example, you may want to extract text and form field data, reuse data to generate reports, or analyze financial results.
Why is PDF Data Extraction Hard to Achieve?
The PDF format was designed to function as an output format for the reliable display of documents, regardless of the user’s computer or operating system. Its ubiquity means it has become one of the most widely used formats for the exchange of business documents, although accessing the data contained within them can be challenging. In structured document formats such as HTML, XML, or JSON, content can be meaningfully labeled using markup, making the task of data extraction easy.
Since PDF was designed first and foremost to be a human-readable format, many documents contain no structure at all, making extracting and processing data extremely difficult. Text content may not even be stored as words but simply as characters located somewhere on the page. While the PDF format does allow for the creation of structured documents (e.g., Tagged PDF or the PDF/A and PDF/UA standards), many documents are likely to pose problems.
However, by using the Apryse SDK Intelligent Document Processing (IDP) add-on’s Data Extraction capabilities, you can reliably and accurately recognize such unstructured content in PDF documents and extract it as structured JSON and Excel data for reuse.
Watch this exclusive webinar to understand everything related to Apryse Intelligent Data Processing and learn to unlock PDF content.
How to extract data from PDF using Java and the Apryse IDP Add-on
For this tutorial, we will cover table data extraction from PDF to tabular formatted JSON or Excel XLSX format or conversion of PDF into structured JSON that describes the PDF in its entirety. In addition, we will show how to process a PDF with an AI-based algorithm to detect form fields, producing JSON which describes their location and type.
Prerequisites
PDF data extraction utilizing the Apryse SDK on Java is easy to setup and integrate in less than 10 minutes.
The prerequisites for running the Apryse SDK are to use a JDK version 5 or greater, which is properly configured so that the JDK is part of the PATH environment variable. Issues with Java setup can be answered in the Java FAQ at https://docs.apryse.com/documentation/java/faq/.
Setup for development
1. Go to https://dev.apryse.com and register a new account with Apryse. This allows Apryse to grant you a demo license key which will be used with the Apryse SDK to enable demo functionality.
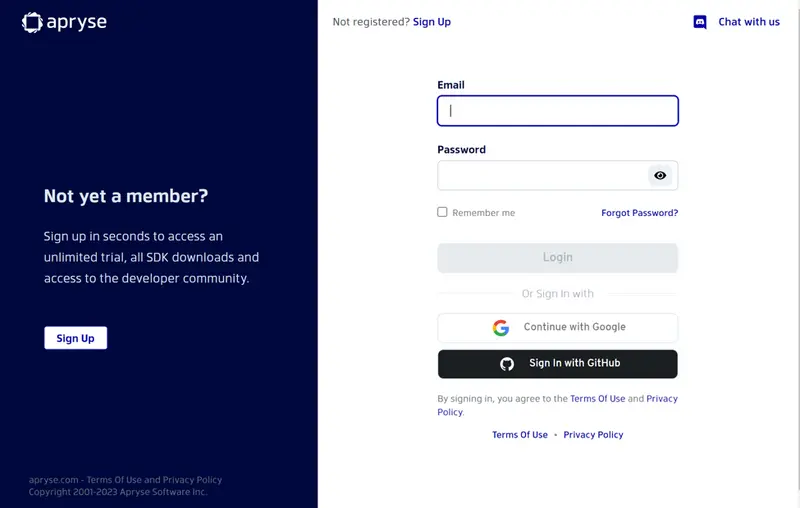
2. Log into https://dev.apryse.com with your registered account. For this guide, we’ll be developing on Windows with Java, so select Windows.
3. Below the Platform selection is a blurred field with your unique developer trial key. Click Reveal to show the key. Copy and paste this into a text file, as we will need it later for use in your code to enable usage of the Apryse SDK.
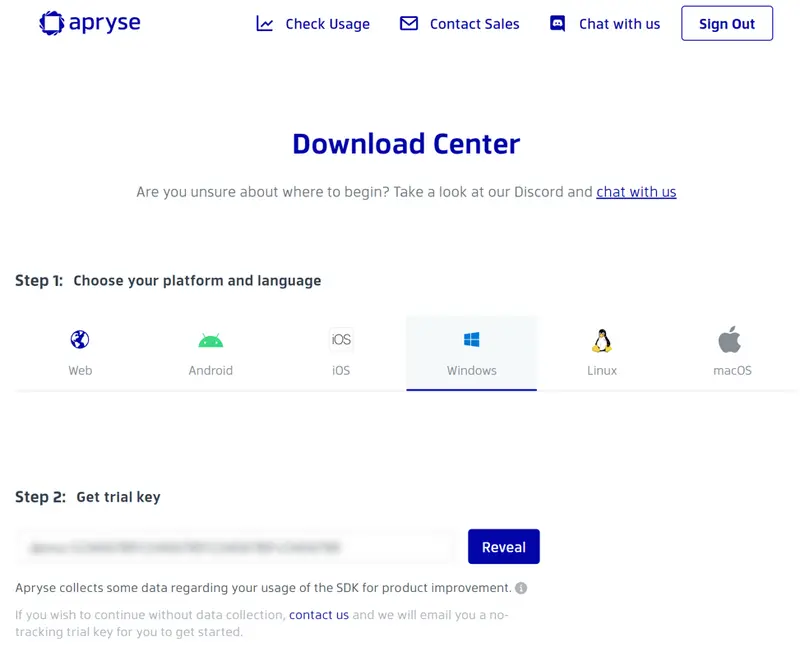
4. Scroll down to Step 3 and select Java for a programming language. This will filter the SDK downloads to just the Java compatible SDK variant. Download the Java Apryse SDK, which is available at https://pdftron.s3.amazonaws.com/downloads/PDFNetJava.zip.
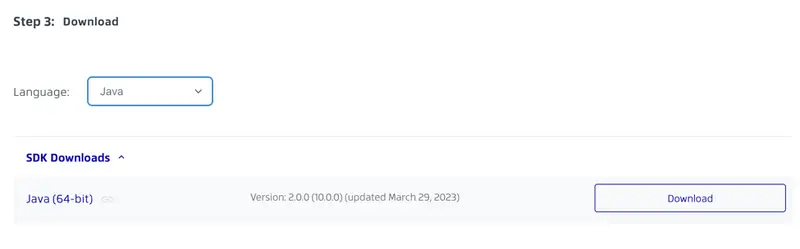
5. Scroll down the page to “Step 4: Get Started”. Select Java for the language and expand the “Modules” section. This lists optional binary packages for additional Apryse SDK functionality. We will need the “Data Extraction Module”. Click the download button to download DataExtractionModuleWindows.zip, which is available at https://pdftron.s3.amazonaws.com/downloads/DataExtractionModuleWindows.zip.
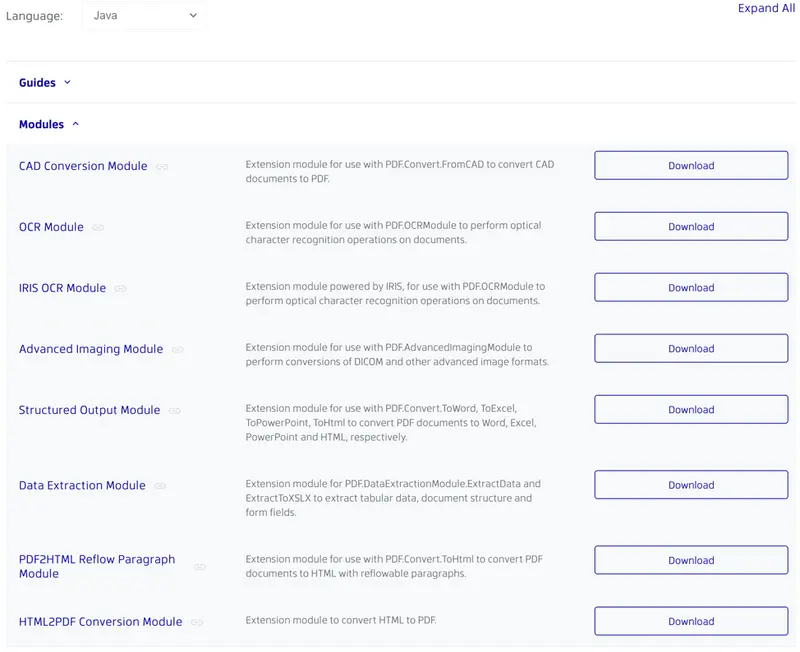
6. Unzip PDFNetJava.zip to a location of your choosing. For this guide, we will just unzip to the root of C:\. This will result with C:\PDFNetJava\ which contains the base Apryse SDK folders for Windows Java development.
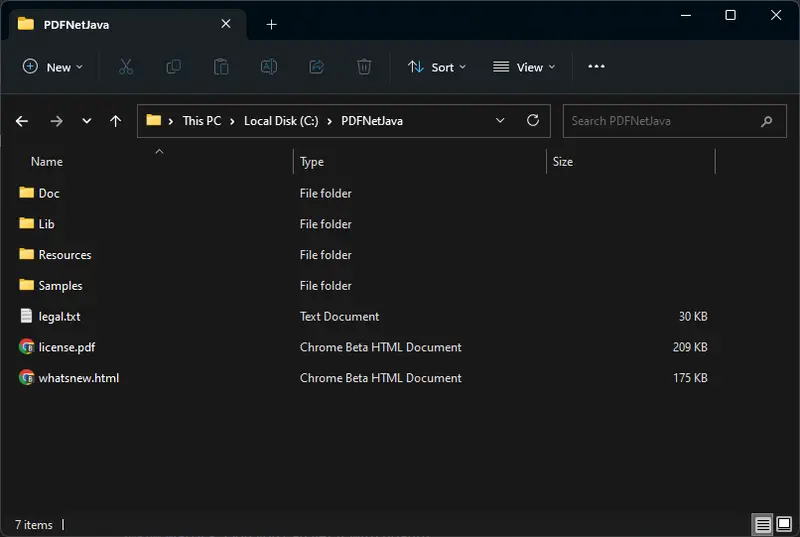
7. Open the DataExtractionModuleWindows.zip where you will find a “Lib” folder. Unzip the .zip file into C:\PDFNetJava so that the DataExtractionModuleWindows.zip Lib folder gets merged with C:\PDFNetJava\Lib. If done correctly, there should now be a C:\PDFNetJava\Lib\Windows folder with some additional folders and binaries. Now the environment is set up for developing with the Apryse SDK and the Data Extraction APIs of the IDP add-on
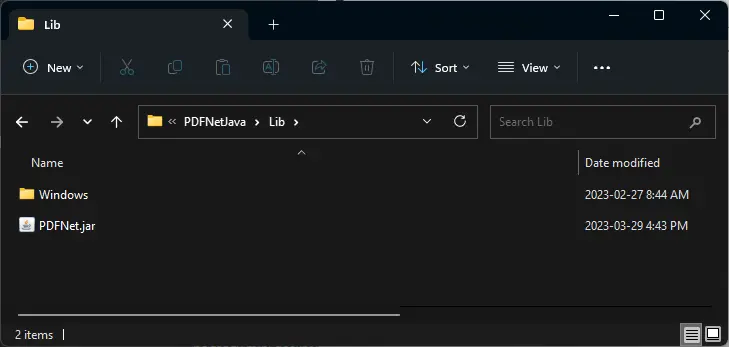
Building a Sample Java Application for PDF Data Extraction
Now that the Apryse Java SDK is set up, we can start building a sample application. To do so requires we add the Demo License key copied from dev.apryse.com
1. Navigate to the LicenseKey sample, which in this guide is available at C:\PDFNetJava\Samples\LicenseKey\JAVA. Open the PDFTronLicense.javafile for editing. This file will contain the LicenseKey utilized by the SDK at run time.
2. Within the PDFTronLicense.java file you’ll see a line of code declaring a private variable
private static String LicenseKey = "YOUR_PDFTRON_LICENSE_KEY"; Replace YOUR_PDFTRON_LICENSE_KEY with the demo license key copied from dev.apryse.com. Now when running sample projects from the Apryse SDK, they will properly initialize the SDK but also have some demo limitations, such as limiting page numbers for batch operations.
3. Open the DataExtractionTest sample in your dev environment so we can test the Data Extraction in Java. This will be available at C:\PDFNetJava\Samples\DataExtractionTest\JAVA\.
4. Open the DataExtractionTest.java file in your favorite code editor and see the sample Java code that runs all aspects of the Data Extraction APIs of the IDP Addon.
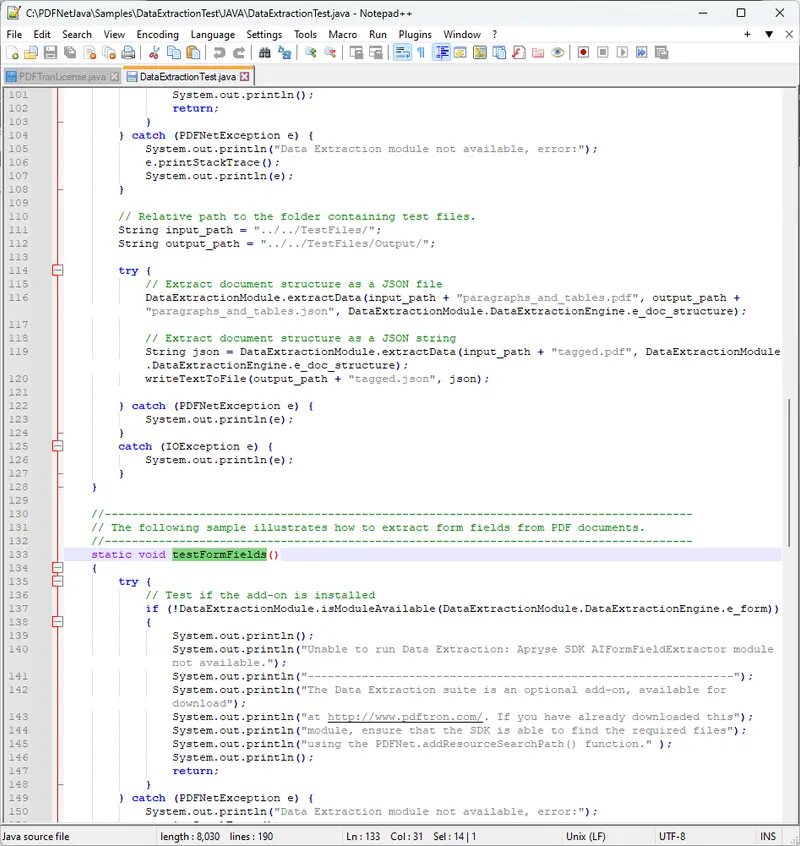
5. The Data Extraction Module has three main APIs which have been divided into three sample functions within the sample code:
- testTabularData(),
- testDocumentStructure(),
- and testFormFields().
testTabularData() will convert some sample PDFs containing tables into both tabular formatted JSON as well as Excel XLSX files. The conversions performed by the tabular functions will convert all content in the PDF into an Excel or tabular JSON file, so non-tabular data, such as paragraphs, will be included. If this data is not required in the output, it will have to be manually removed post-conversion.
testDocumentStructure() will convert some sample PDFs into a document structure JSON which describes the PDF in its entirety. This JSON will contain a JSON element for every item in the PDF, whether it’s text, images, graphics, or tables. Each element will have position data as well as text formatting so that the JSON is an accurate 1:1 reconstruction of the PDF.
testFormFields() will process a PDF with an AI-based algorithm and produce a JSON document describing the location and type of detected form fields. This AI will detect forms from not only PDF native forms but also flat non-interactive PDFs containing forms for printing and additionally from scanned image-based documents.
6. To run the sample code, there is a RunTest.bat batch file at C:\PDFNetJava\Samples\DataExtractionTest\JAVA\RunTest.bat. This will execute the command line application built by DataExtractionTest.java. If successful, no errors should be visible in the terminal.
7. To view the output of the sample code functions, open the folder at C:\PDFNetJava\Samples\TestFiles\Output. Here you will find JSON documents and Excel files, which are the result of the previously mentioned test functions.
Suggested Read:Learn how to extract data from PDF in C# using .NET
Conclusion
The Java sample will show that very few lines of code are required to extract data from PDFs using the Apryse SDK and the Data Extraction Module. Visit our Smart Data Extraction guide for more details on our cross-platform API, or for more general help with Java development and the Apryse SDK, visit our developer guides for Java.