Home
All Blogs
Document Parsing in PDFs: A Comprehensive Guide to Understanding and Utilizing This Crucial Process
Roger Dunham
Published August 29, 2024
Updated June 27, 2025
4 min
Document Parsing in PDFs: A Comprehensive Guide to Understanding and Utilizing This Crucial Process
Roger Dunham

Summary: Apryse Smart Data Extraction offers a robust solution for organizations grappling with the challenges of unstructured data extraction from various document formats, including PDFs, DOCX files, and emails.
Introduction
Imagine that your company has a data strategy, and you have been tasked with implementing it. But here’s the problem, you have access to vast quantities of unstructured data held in a mixture of emails, DOCX files, PDFs, and so on, and you need to transform the PDF content into actionable data.
Does that sound familiar? If so, read on—document parsing and the use of Apryse Smart Data Extraction may be just what you are looking for.
PDFs are a great file format. They are easy to distribute and view (and consistent) on a wide range of platforms and devices.
They can also be data-rich, potentially containing enormous amounts of valuable information, whether about a contract, sales figures, AEC documentation, or any industries that use the format.
While humans are good at extracting information from PDFs, regardless of variations in structure and layout, it can still be a complex process to do this in a scalable way. Reading, understanding, and extracting data from a few dozen PDFs daily is feasible for a human, but how would you deal with 50,000 or 500,000 documents?
This is where document parsing comes in to make extraction efficient with data processing of information stored within PDFs.
This article provides a comprehensive guide to understanding document parsing, its importance, and how to utilize it effectively.
What is Document Parsing?
Document Parsing refers to the process of analyzing a document's content to extract useful information. That information may be in the form of text, images, tables, and metadata, each of which is a potential source of information and needs to be extracted separately to make it accessible within other applications.
How does Document Parsing Help my Business?
Document parsing, especially for PDFs, adds value in several ways by making the data easier to use. This helps:
Decision-making: PDF-sourced data can be used for further processing and analysis, facilitating better decision-making. If the parsing can be automated, it may also allow faster decision-making.
Improved Document Searching: Once the data is available, it can be used to create better indexes and an improved search mechanism for a PDF-based archive.
Automation: Document generation systems such as Fluent and Apryse SDK Document Generation can be used to automate the creation of documents using the latest data and predefined document templates. Parsing PDFs can provide an essential source of data for these systems.
Further processing: Some users take PDF-derived data as the basis of further processing, automated translation of PDF content would be one example, allowing the value of the original document to be leveraged to a wider audience.
What are the Key Components of PDF Parsing?
1. Layout Analysis: Many people would think of layout analysis as the final part of the process of parsing a document. But it can also be considered to be the first and most important part. If the document contains columns of text, does that relate to ‘Newspaper’ type columns or to the presence of a table, it could be either. Understanding the document's layout, such as columns, margins, and text flow, is, therefore, a crucial part of understanding the document's content.
2. Text Extraction: At first glance, extracting text from a PDF sounds trivial. Even if we set aside the need for OCR or NSE identification (which we will explore shortly) – text is more than just a group of characters, and this is where understanding the layout matters.
Sure, a block of text could be part of the document's body —perhaps a paragraph or, if in large font, a heading.
On the other hand, the text’s location might hint at its different meaning. If located at the top of the page, it might be a page header, and similarly, if at the bottom of a page, it might be a page footer or even a footnote. Then again, if located near an image, it might be the caption of the image, or if located towards the end of a document, it could even be a signature.
Getting text from the document but ignoring how it relates to the document is a surefire way of running into problems when you start to deal with complex, real-world documents.
3. Image Extraction: Detection and extraction of images ought to be straightforward, but what if the image relates to scanned text? In that case, should the image be sent for OCR handling to extract the text? What about if the image was a computer screenshot? Should that be OCR’d, or would the text extracted have no meaning?
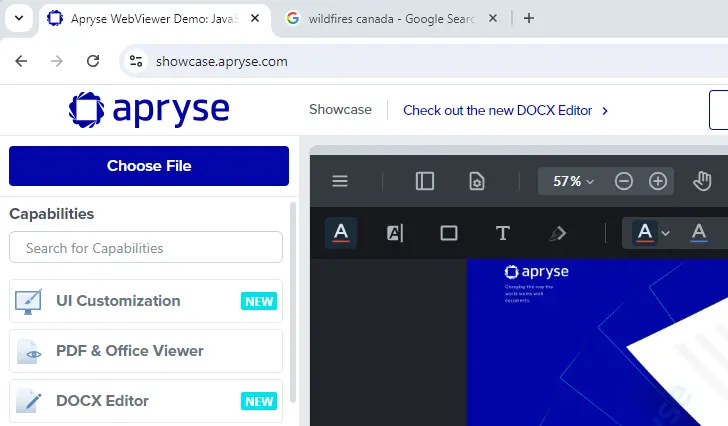
Figure 1 - An example Screenshot. If this was in a PDF, how should it be interpreted? Should it be OCR'd?
The answers are not straightforward.
4. Table Extraction: Being able to extract tabular data is an awesome result – many businesses use tables to store data, so being able to identify a table, as being such, is often a way of getting a rich source of data from a document. Sometimes extracting a table is easy and the PDF may be tagged to say that something is a table, and if not, then there may be gridlines and borders to make it obvious. Unfortunately, not all tables have grid lines, or are consistently laid out, and tagging can be incorrect – so once again, this can be a challenge.
5. Metadata Extraction: Finally let’s look at document metadata, information about the document itself, such as the author, creation date, and keywords. Metadata can be a useful way of filtering those documents that are of high value from those that are not – for example you may not be interested in documents that are more than five years old. Even knowing the author can be of value. For example, not all document authors are equally good – so being able to select only PDFs from well-respected authors may help to get quality information.
Be careful of metadata though, it may be absent or incorrect, since, like many other aspects of PDFs, it can be edited.
Document Parsing Challenges
Complex Document Layouts: PDFs with complex layouts, such as multi-column formats or embedded tables, can, as we mentioned earlier, be challenging to parse accurately.
Inconsistent Formatting: Variations in formatting styles across different PDFs, or even within the same PDF, are common.
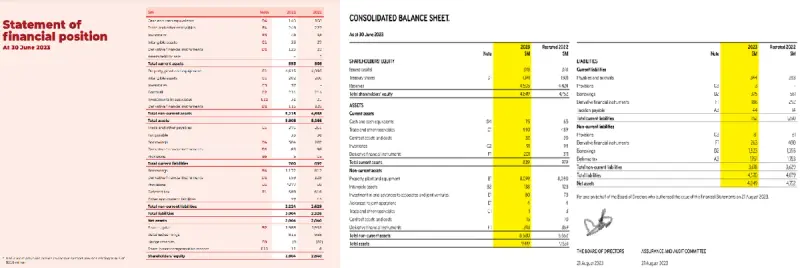
Figure 2 - Financial information laid out in entirely different ways in two PDFs.
The same information may be in entirely different locations in different PDFs, making automated identification difficult.
Quality of Source Documents: This is a particular issue with scanned documents, where low scan resolutions, artifacts on the page – whether hole punches, staples or even dog hairs can reduce the effectiveness of OCR and other parsing techniques.
Non-standard Encoding: NSE can cause chaos, while the document looks correct, when text is directly extracted from the PDF it may be complete nonsense. Some tools can deal with this automatically, others cannot.
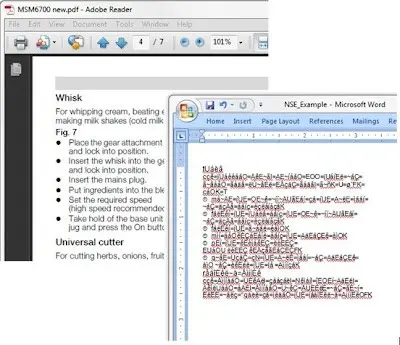
Figure 3 - An example of Non-standard encoding - while the PDF is entirely readable the actual text within it is not directly meaningful
Best Practices when Parsing PDFs
Standardize Documents: Wherever possible, standardize the format of your PDFs to simplify parsing – if they are generated inhouse then that may be straightforward, but if they come from a third-party organization, or, worse still, many different third party organizations, then you will have to deal with multiple document layouts which will make parsing much more challenging.
Use Good Tools: There are many tools out there that work, more or less, often less. Few, if any, tools are perfect, but low-quality tools will just result in lots of post-processing, a need for error-correction and a lack of confidence in the system that you develop.
Value and Validate your Extracted Data: You are going to be making decisions based on the data, or else using it to generate documents. Treat your data as being valuable. Better still, make it more valuable by implementing validation checks, whether manual or automated, to ensure the accuracy and completeness of the extracted data.
How do I Parse a PDF?
There are lots of tools for extracting content from PDFs.
A couple of free ones are PDFMiner, for example which is a Python3, and PDFBox which is a Java based library.
In some situations, these may give you all that you require, which is great.
The problem with these is that, while they may be adequate for simple PDFs, if the PDFs become more complex then they may not be able to deal with them effectively. When that happens, then first you will end up with a decline in data quality, and then there will be a frantic rush to modify your data-acquisition process, possibly migrating to new tools. That doesn't sound much fun.
As such, it may be worth looking at commercial tools in the early stages of developing your PDF parsing process.
Apryse Smart Data Extraction would be one of the tools that you should consider. Key features include:
Advanced Data Extraction: Using proprietary AI algorithms, Smart Data Extraction can, of course extract text, but it can also discern and extract tables, forms, and intricate document structures (such as headers and footers) with unparalleled precision. And that all happens without the need for you to create specific templates to teach the tool where to look for data.
Refined Form Processing: Imagine that you have a form with labels and associated content in a non-interactive PDFs – for example containing a label such as "Name" and content such "John Doe". Smart Data Extraction can detect those key/value pairs and identify that they relate to each other. That data then ends up as JSON and can be used as you wish.
Table Recognition and Data Capture: Tables, including those with no obvious borders, can be recognized and extracted either as JSON or as Excel Spreadsheets, even when NSE text is present.
Read more about Automated Data Extraction with Apryse Smart Data Extraction.
Whether you use one of the open-source tools, Apryse Smart Data Extraction, or another tool, you will still need to post-process the data to wrangle it into the final format that you require, and this is an area where you will need to have some development and data-science skills. It is also an area where you can apply your expertise to give you an advantage over the competition. As we have said above though, if you need to manipulate data, make sure that you start with the highest quality data that you can get.
Can I just buy a pre-built solution?
There are, of course, dedicated SaaS solutions available from other vendors, but they are tightly tailored to specific industries – if your business is different from the average, then it might not be a perfect fit.
Furthermore, those SaaS providers generally require you to upload your, potentially sensitive, files to their server. Can you be sure that they won’t be intercepted, or retained, and seen by someone that should not be able to?
Apryse Smart Data Extraction, on the other hand, can be deployed in whatever way you choose. You can deploy it within the cloud, on bare metal or within a container – but in each case you have control over your data throughout the process. And that’s a good thing.
Conclusion
Document parsing, particularly for PDFs, is an essential process for unlocking the value of information contained within these documents. Whether you are dealing with simple text extraction or complex layout analysis, understanding document parsing, and getting it done well, is a crucial step towards efficient document management and data-driven decision-making. Having a good tool makes a huge difference.
Apryse has great tools for doing exactly this.
When you are ready to get started, see the documentation for the SDK to get started quickly. Don’t forget, you can also reach out to us on Discord if you have any issues.