Apryse
Published October 19, 2023
Updated May 18, 2026
10 min
Generating Documents and Reports from DOCX Templates and JSON using Apryse and Python
Apryse

Introduction
The ability to automatically generate documents using the most up to date data is a powerful solution for many industries. In addition to time and cost savings, automatic document generation improves consistency and accuracy, helps to limit unnecessary access to confidential data and is scalable as the business grows.
Apryse has two distinct systems for creating documents and reports from templates. In both cases the templates are Office Documents.
The first mechanism is Fluent, and there have been several recent articles on using this versatile and powerful low-code system which can create not just PDFs, but also other document formats (including DOCX, PPTX and HTML) all from the same document template. Furthermore, this sophisticated system can get data from a huge range of data sources, including JSON, XML, SQLServer, OData.
The other system – SDK-DocGen – is high-code and is based directly on the Apryse SDK. It can be used either entirely within the browser, running as a specific process on the server side or as an entirely standalone app running on a local machine. The system uses data in JSON format to populate the template and create PDFs directly.
In this article, we will look at how to use the Apryse DocGen document generation system from Python. We will look at:
- How Text Substitution in a PDF Sometimes gives Poor Results
- Document Generation in Action
- Overview of the Document Generation Process – From DOCX to PDF
- The Pre-packaged Python Sample
- Editing and Creating Templates
- The JSON data structure
- Go Beyond DOCX – Support for other file types
- When Apryse SDK-DocGen should be Used
How Text Substitution in a PDF Sometimes Gives Poor Results
A quick search of the internet reveals some document generation systems that use a PDF as a template, then substitute content within the PDF to create the final document. If that is all you need then that is a good solution, but in reality, when used with real data it is likely that you will soon find limitations.
One product sample, for example, searches for specific text within the PDF, then replaces that text with data from a JSON file, allowing the specific company name to be written into the PDF.
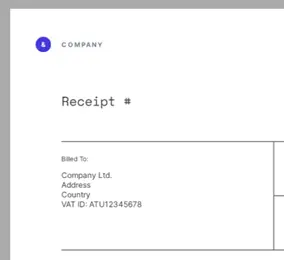
Figure 1– Part of the original PDF template.
If the company name is “Alphabet soup”, then the text fits – a simple solution.
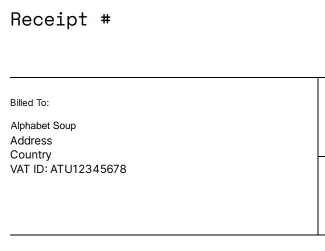
Figure 2–Part of a PDF created by substitution of text from a PDF template.
But if the company name is longer, for example “Alphanumeric Soup Manufacturing Ltd” then it won’t fit into the available space and is truncated.
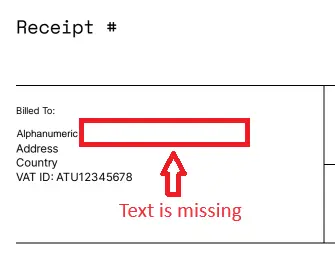
Figure 3 - A PDF created by substitution of text from a PDF template. There was not enough space, so some text is missing.
While in that example the problem can be solved by making the space larger, how do you deal with content that might be one, two or more lines long? Do you leave space for 3 lines, then often have a gap; or leave just one line and have text overflowing onto the next item of information? There really is no simple solution when it comes to using PDFs as templates.
Using DOCX files as a template can solve this problem. Word is great at updating the layout of the page when a line of text at the top of the page suddenly flows onto a second line. While you could use MS Office directly for text substitution (or LibreOffice or OpenOffice), those solutions require additional3rd party software, possibly extra licenses, and may not be easy to call programmatically, particularly on a server.
The Apryse SDK is great at reflowing text in just the same way that Word does, making it an ideal tool for substituting text-markers in a template. Even better, it does all of this without a dependency for Office or any other Word processing application to be installed.
See Document Generation in Action
Before we go any further, let’s look at a live example of document generation from a DOCX template.
You can choose any template, and the program will query it for the tags, and then use those to create a form that allows you to enter data, which is then used to populate the template. While the sample is written in JavaScript, the principles of document generation are language agnostic.
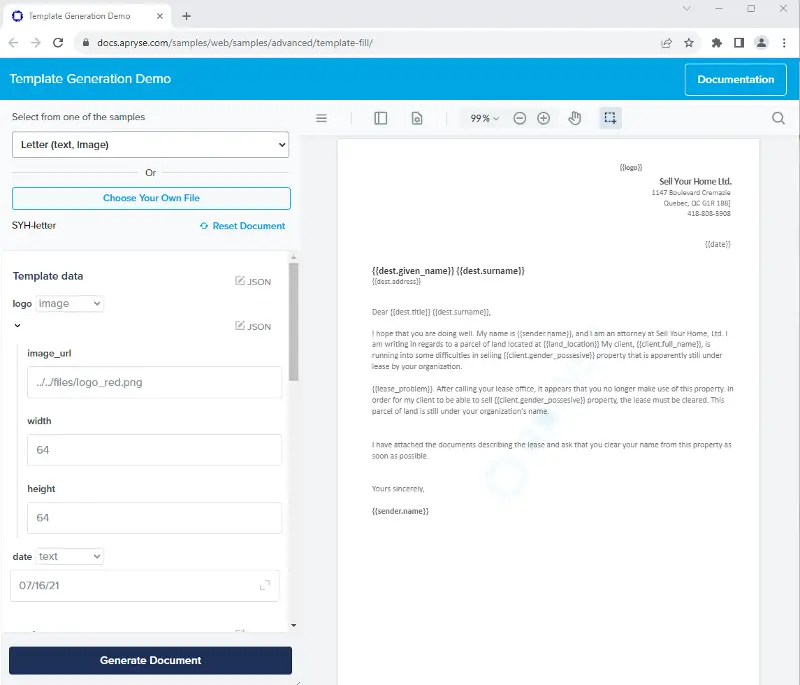
Figure 4 - The online sample showing a dynamically generated data entry area.
So, let’s see how we would do this in practice.
Overview of the Document Generation Process – From DOCX to PDF
- Create a template in DOCX format. This can be done using markers (which Apryse refers to as tags) to indicate where text should be located. In addition to single word replacement, tables with run-time row creation are supported, as is some conditional logic. The method for creating templates is well documented and can be performed by anyone with an editor that understands the DOCX format.
- Gather the data that is to be used for the generated document. This needs to be in JSON format for the template filling to occur, but where you get that data from is limited only by your imagination – whether it is collected from a file, user input, a database or a RESTful API.
- Replace the tags with the real data using the Apryse Python SDK to fill the template then display or save the generated PDF.
The Pre-packaged Python Sample
Head over to Server SDK Python get started guide and follow the steps to install the version of the SDK that matches your Platform and version of Python, then download the samples.
You will need an Apryse Trial key.
Now update the file LicenseKey.py with your Trial Key
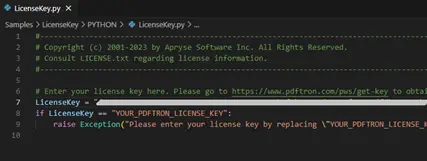
Figure 5 - Entering your license key information into the file LicenseKey.py
Unlike the samples for many of the other languages that Apryse supports (C#, C++ and Java), the Python 3 samples do not include the SDK in the download. As such it is necessary to install it.
But, if like me, you can’t wait to get started, then in a CLI enter
pip install apryse-sdk --extra-index-url=https://pypi.apryse.com
Finally head over to the sample folder OfficeTemplateTest, and within a terminal enter RunTest.bat (if you are using Windows) or RunTest.sh (if you are using Linux or macOS).
After a few seconds you will see that the processing has completed, and a file called SYH_Letter.pdf will have been saved.

Go and look at that file. We will be working with both it, and the template from which it was created, in the rest of this article.
Editing and Creating Templates
The template in this example is just a Word DOCX file (although other Office formats are also supported). It can contain any formatting, and any amount of text that you want. Furthermore, it can contain any number of tags that should be filled when the PDF is created. Although the template is a DOCX file, it doesn’t need to be created in Word – any editor that supports that format can be used.
The easiest way to understand how to use a template is to work with one. We will use the file SYH_Letter.docx in the Samples/TestFiles folder.
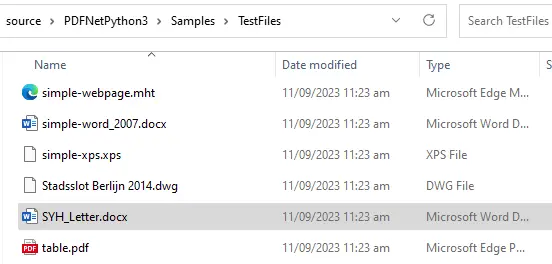
Figure 6 - The location of the template file that we will work with.
If you open that file you will see that it contains text (and possibly images, tables and all of the other things that DOCX supports) and text that is to be substituted (which are known as tags).
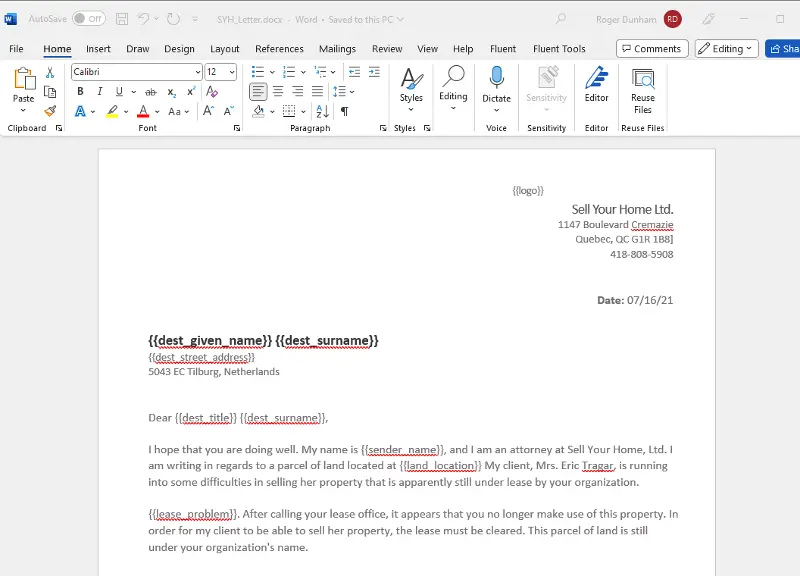
Figure 7 - Part of the report template DOCX file.
The tags typically start and end with two curly braces (sometimes known as “moustache” brackets). If necessary, it is possible to use a different delimiter,(for example if moustache brackets mean something else in your document). You can find out more by asking on Discord.
In the image above there are a number of tags marked, for example {{dest_given_name}}, {{dest_surname}}, {land_location}} and {{lease_problem}}.
When we run the template these will simply be substituted with values from the JSON data source that have keys that match these names.
Setting Up a Multi-Row Table
While we could just use the template as it is, lets add a table to it, as that illustrates an important feature of SDK-DocGen – the ability to add multiple items to the document, when the number of items is not known when the template is created.
We can do this with a standard Word table, formatting cells as we wish.
In this example I have left cell borders visible, simply because it makes it clearer that this is a table.
There are two ways that table data can be shown –by specifying it within the template, or within the data.
Specifying Tables Within the Template
This is the recommended method wherever possible, and is based in the Loops syntax.
In one of the rows add the following tags to the cells in that row:
- {{loop rows}}{{year}}
- {{rent}}
- {{tax}}
- {{year_total}}{{endloop}},
and in the bottom right cell add the tag {{total}}
The {{loop}}…{{endloop}} syntax indicates that there may be multiple rows of data, the name ‘rows’ in this case is used to map where the data should come from in the JSON file, and the other tags indicate what should go into each cell within the row.

Figure 8 - A table specified with the loop syntax.
A benefit of this syntax is that the table can have cells that are not populated from the same JSON data item – perhaps from another key, or with static text. It is also easy to see in the template which tags will be in which column. If there was a need to change the order of columns, then the columns in the table would still contain the correct data.
Specifying Tables Within the Data
This method is not recommended, and should only be used if the template-based specification method won’t give you what you require.
Specifying tables within data makes for simple template structure at the expense of a more complicated JSON data structure, and the risk of generating a messed up document.
In one of the rows add the tag {{rent_details}}, and in the bottom right cell add the tag {{total}}

Figure 9 - An example table with tag values, where the table cells will be implied from the data.
The matching data structure would be something like
We will see in a minute how the tag replacement occurs, but in this case one row of data will be generated for each array in ‘insert_rows’ – with the data for each element placed into a separate cell. This is great when it works, but if the number of elements doesn’t match the number of columns, or the order of columns changes, or you want to have data in cells from another source then this is not possible. As a result it is very easy to end up with an incorrect document, which is the last thing that you want.
For both template-based, and data-based tables, only one row in the table needs to contain tags. We will see in a few minutes how multi-line data is stored within the JSON data object, and how that controls the generation of multiple data rows within the document generation mechanism.
Using Conditional Data
You can find information about how to specify conditional tags. These allows some parts of the text to be deliberately hidden, or shown, depending on what is present in the data. Conditionals, in this case for the key cond,
- start with {{if cond}},
- end with {{endif}}
- and support {{else}}

Figure 10 Figure - A typical conditional. If cond is true then the True clause is shown, otherwise False clause is shown.
The JSON value corresponding to the condition key (cond in this example) is converted to a boolean. It is evaluated as false when either:
- The key is not present in the JSON
- The value is false, "", 0, or null
The conditional key also supports operators.
New in SDK Version 10.4 is the equal operator, which we will use in a few moments.. If you try to use equal with older versions of the SDK then you will get an error.
You can check that you have the correct version installed using pip list -v
As a trivial example, let’s show one message if the rent has increased, and another if it has not:
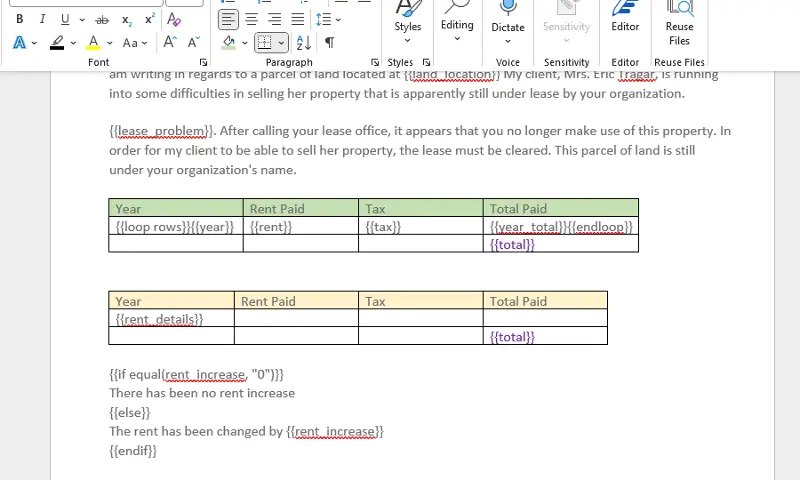
Figure 11 - The template showing the table and conditional data.
Currently the options for making comparisons is limited to just “equal’.
If you need more complex control, then this can be done my manipulating the JSON data source, for example adding an object for “More than 100” so that the message can be shown when the rent increase is greater than a value rather than being an exact value.
OK, we will leave the template there, and move onto looking at the data.
The JSON Data Structure
The text substitution API should be supplied with a JSON dictionary, where each template tag within the template matches a key within the dictionary. The content of the JSON values can be text, images, structured input (html and markdown)or objects.
While SDK DocGen requires that the data is in JSON format, how you generate that data is up to you. It could be hard-coded, acquired from user input, a local file, a database call or even from a web call.
For our simple template though, the sample code already contains some hard-coded data, and we will add a little more to populate the table and conditional text
Most of the layout is self-explanatory, but let’s look at two specific areas:
Handling Rows in the Document
The recommended method of specifying cell tags in the template uses the data from rows. This is followed by an array that contains an object for the values that should be placed into a single row.
The alternative data specified row uses the rent_details object. This contains a property for ‘insert_rows’ followed by an array of arrays. The syntax ‘insert_rows’ is special and indicates that the template filling mechanism should create a new row for each of the sub-arrays.
As such when this code runs it will give the following output – the two sub-arrays have each been converted into a row within the output table, which had the tag {{rent_details}} in the template.
Controlling Style from the Data – Structured Input
While most of the data is just text, the “dest_surname”is specified as html.
"dest_surname": {{"html":"<span style='color: red'><b>Symonds</b></span>"}}, This is an example of how the formatting of the document can be controlled from the data using html or markdown.
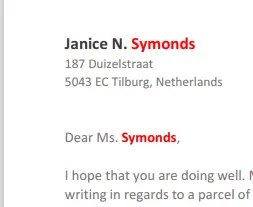
Figure 12 - Part of the generated document. The formatting for the surname was defined in the data, not in the template.
This mechanism is well suited to altering the look of the document via the data – with the ability to add paragraphs, headings, and styling.
Generating the Final Document
Everything that we have seen so far – template generation and JSON format - is platform-independent, and the results will be the same whether the actual conversion occurs within a browser or server side.
The actual process of document generation does have minor, platform specific, variations, however. With SDK-DocGen supported on UWP, Android, Linux, macOS and Windows, as well as the Web, there are many opportunities for you to use this technology. Please check out the documentation for the specific language that SDK-DocGen supports.
This article is primarily about generating documents using Python, and in this case the actual code needed to generate the document is just the following:
The Apryse SDK-DocGen system then replaces each of the tags in the template with data from the JSON object wherever possible, including iterating through tables, and produces a PDF.
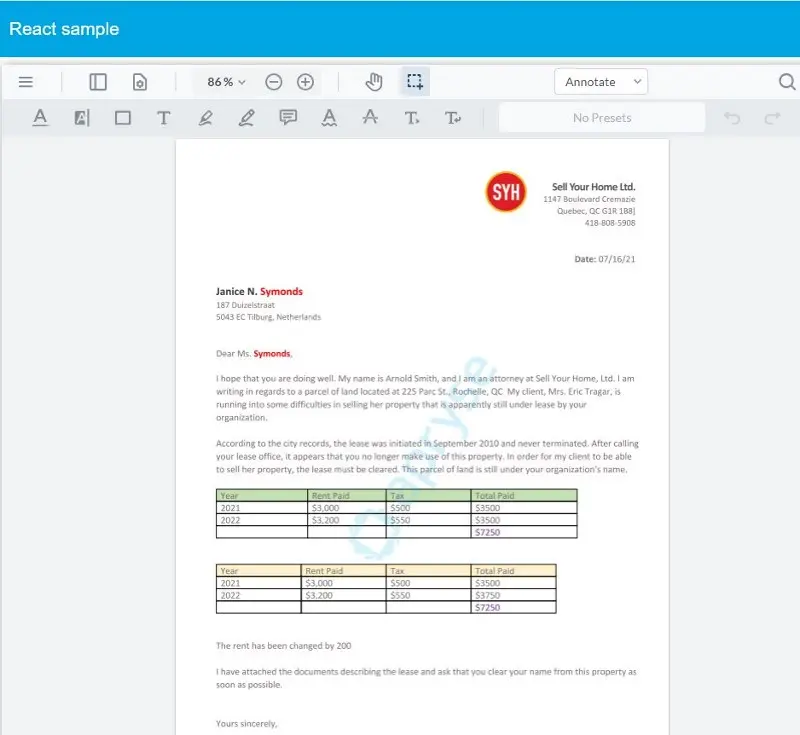
Figure 13 - The generated document – The surname is in Red, both tables have been populated and the conditional text says that there has been a rent increase, and states the amount..
It really is that simple. Three lines of code takes the template, merges it with the JSON data, and creates a document, without the need for Office to be installed.
Go Beyond DOCX – Support for Other File Types
The SDK Doc-Gen mechanism always creates a PDF, and it is extremely good at doing that.
While the most used template format is DOCX, the system also works with PowerPoint and Excel files (including the old-style DOC, XLS and PPT file types).
In each case, the tags to be substituted are marked the same way.
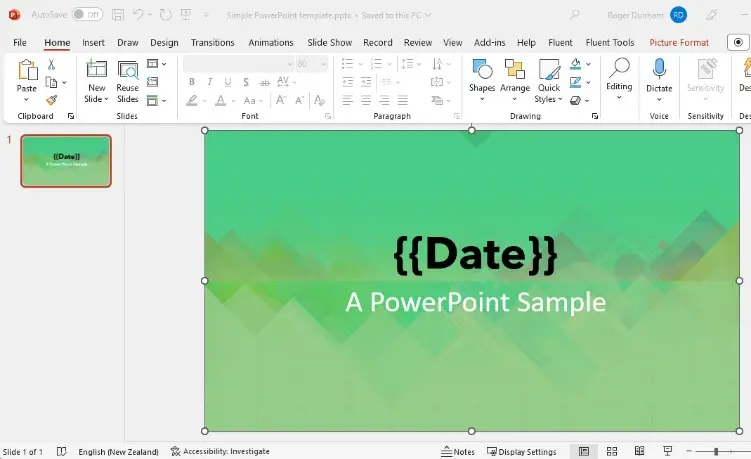
Figure 14 - A PowerPoint template, and the resulting PDF.
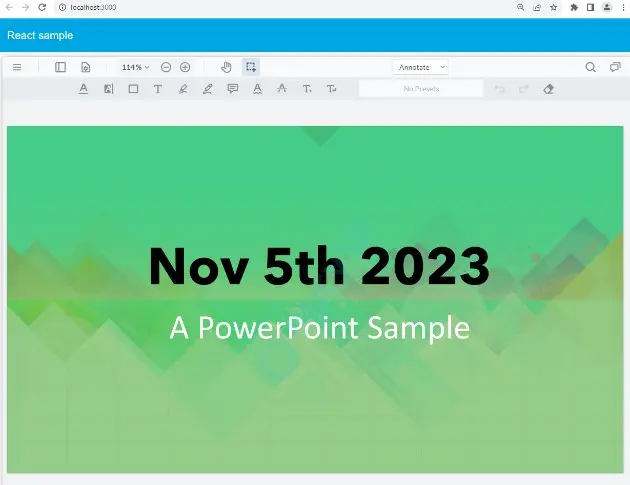
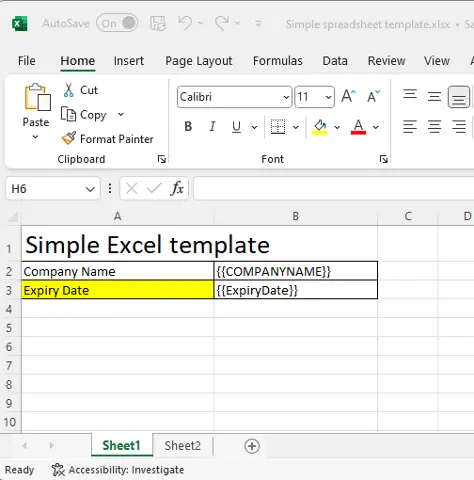
Figure 15 - A multi-sheet Excel template and the resulting PDF.
When Apryse SDK-Doc Gen Should be Used
This system is great where the data source is JSON (or can easily be converted into JSON), the required document format is PDF, and its structure is relatively straight forward. This mechanism is also a great solution for use with Appian or SalesForce– with no external libraries being required.
One of the disadvantages of this system, however, is that a change in the data source will probably require help from a developer. For example, the data source for a RESTful API might change, or the structure of data coming from a reporting system might need to be updated. In the case of Structured Input (formatting via html and markdown), if the formatting needs to be modified then that would likely also need developer help. As such, if your data source or complex formatting is likely to change then the low-code Apryse Fluent may be a better fit.
Similarly, in any situation where your use-case isn’t supported (such as needing complex conditional formatting or charts) then Apryse Fluent will be able to take you much further. Currently DocGen only supports generation of PDFs, but direct creation of Word (DOCX) documents will be available soon.
Conclusion
We have seen how we can create templates in a familiar environment that can support text of initially unknown length, adjusting the layout of the document to work around the text. We have also seen how we can add logic to the template so that some parts of the document are only shown if some data condition is true, and how multi-row data can be added into tables.
We have also seen how this can all be done without the need for Office to be installed. Furthermore, if you want to extend the document generation in some way – perhaps developing a desktop app, or providing browser-side processing, then the information that is included in this article is a great basis for taking those next steps.
When you are ready to get started, see the documentation for the SDK to get started quickly. Don’t forget, you can also reach out to us on Discord if you have any issues.