James Borthwick
Published November 24, 2015
Updated May 18, 2026
7 min
pdf.js: Interesting Project, Incorrect Rendering
James Borthwick

Editor's Note: This post was originally published in 2015. Read our Comprehensive Guide to PDF.js Rendeirng for a revamped overview of PDF.js rendering accuracy and possible implications for your project
pdf.js is a well known project for rendering PDF documents directly in the browser. In that sense, it is similar to our recently announced PDFNetJS. While pdf.js is interesting project, and may be a reasonable choice in some very specific situations, it has a number of serious problems that make it unreliable for any situation where PDF rendering is important.
pdf.js vs PDFNetJS: Different Approaches
pdf.js was initially conceived by Mozilla (creators of Firefox) as a project to show off HTML5, how it could be used to implement almost anything that a native app could do. PDF rendering was chosen because it was the domain of native apps, and that as PDFs are composed of text, images and vector graphics, a web browser should be able to lean on its existing native capabilities to handle these data types to render them without too much difficulty.
At first it might sound reasonably straightforward, but it didn’t take long for the authors to run into trouble. PDF text was problematic, because PDFs contain many different font types, most of which are not supported by browsers. Images were trouble too, because PDFs use compression formats (CCITT, JBIG2, JPEG 2000, and more) that were not browser-supported. Even the vector graphics were not compatible, with concepts such dashed lines, certain polygon fill rules and a number of blending operations not present and which could not be added without being exceedingly slow.
To solve a number of these problems, Mozilla implement the missing functionality using native code directly in Firefox, exposed as custom “HTML” extensions. Ironically this reliance on Firefox-specific behaviour made pdf.js useful only on Firefox, and not truly an HTML5 program, so Mozilla began to lobby the other major browser developers to add these extensions to their browsers too. The lobbying has had limited success, with the situation now being that Firefox has the custom extensions that pdf.js expects (of course), Chrome and Safari having some, and Internet Explorer and Edge having few.
The result of this is that pdf.js renders quite differently when used on different browsers, as shown below.
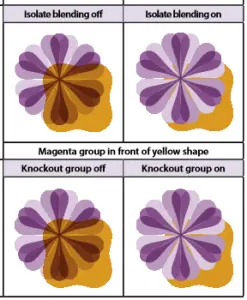
pdf.js rendering in FireFox

pdf.js rendering in Chrome
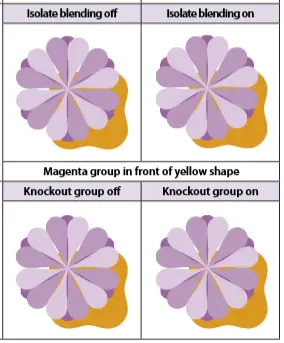
pdf.js rendering in IE
PDFNetJS on the other hand avoids these problems entirely. It does so by not relying the browser’s built-in image, font or vector handling, including the new extensions. By instead handling all of these requirements internally, there are no rendering differences between browsers, and rendering is high-quality and guaranteed.
Here is how PDFNetJS and desktop apps render the PDF snippet shown above, which you will note is actually different than pdf.js:
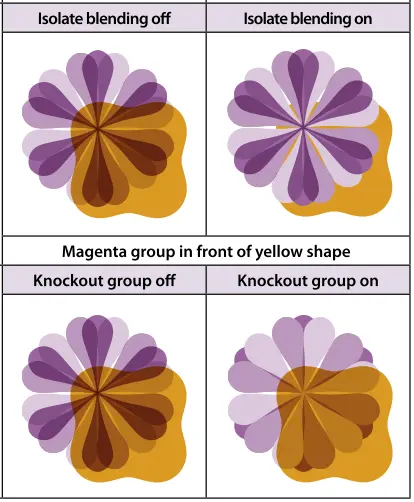
Correct Rendering (PDFNetJS)
Partial PDF Implementation
Despite adding some missing functionality into the browser itself, Mozilla did not add everything that PDF needs, and its authors have no plans to do so. At a presentation on pdf.js, it was said that “I don’t think we’ll ever add support for some of the [patterns and gradients that] PDF supports, because they’re really kinda bizarre” (20:27). Of course supporting these patterns and gradients are required to correctly render PDFs that use them, and if support is missing, the PDF will be rendered incorrectly, if at all.
Excluding parts of the PDF specification is very troubling, as the core promise of a PDF is that it reproduces content in an identical manner. The fact that the pdf.js project is comfortable producing a renderer that intentionally does not fulfill this promise runs against the very essence of PDF, and undermines the trust users put in the format.
Beyond patterns and gradients, other parts of the PDF specification are also absent from pdf.js. Some examples of missing or incomplete features are are soft masks (transparency), overprint, spot colours, and knockout groups, to name a few.
PDFNetJS on the other hand implements everything needed to render a PDF correctly, just as it is rendered on a desktop. It’s rendering is identical to that of our desktop SDKs, and is so on all browsers.
Below are two more examples of PDFs that do not render correctly in pdf.js (and of course do in PDFNetJS):

PDFNetJS Rendering (Correct - left) & pdf.js Rendering (Incorrect - right)

PDFNetJS Rendering (Correct - left ) & pdf.js Rendering (Incorrect - right)
Forms, Annotations and PDF Editing
PDFs course support far more than static viewing. One of PDF’s most used facilities is its ability to act as an electronic form, such as an income tax or passport form. Another feature that is widely used are annotations, which people use to to mark up PDFs with highlights, notes and other annotations for others or for later reference.
As useful as the features are, pdf.js does not support them. It does not have any facility to fill forms or add or manipulate annotations. PDFNetJS on the other hand comes with both of these built-in: it can fill forms (including process Javascript) and add/edit annotations.
Editing PDFs at a level below forms and annotations is also a requirement for many use cases. Document manipulation, such as split/merge, adding new pages, removing pages, rotating pages, and manipulating existing content on an element-by-element basis are useful abilities that PDFNetJS supports. This even extends to creating new, sophisticated PDFs from scratch. However, as with forms and annotations, pdf.js does not support changing PDF content in any way.
Security
Although one of the motivations for using pdf.js was to enhance security, it has actually been responsible for enabling a numberofsecuritybugs.
Support
Support is an important part of any software offering. pdf.js is an open source project that Mozilla has created for Firefox’s own use. This means bugs and problems, if they decide are worth fixing, are resolved on their schedule. Unfortunately this means many bugs go months or even years without being addressed. For example, this rendering bug, which is reportedly a regression, was reported in February 2015, is still not fixed, and has not been assigned to anybody or added to a milestone. This rendering bug has been outstanding since March 2013. This rendering bug has been open since September 2012. The list goes on. Keep in mind these rendering bugs will only be a small handful of those that exist as most Firefox users are probably not reporting bugs on Github.
In contrast, here at Apryse the customer is our priority. If you need help regarding how to use PDFNet or have questions about how to use it most effectively, we are here to offer advice. Should you find a bug, chances are we will be able to provide a patched version in short order. We offer developer-to-developer technical support, ensuring accurate and timely answers to your questions or concerns.
The Future
Support is not only important for the present, but also for the future. The web is changing at a rapid pace, so maintenance for compatibility with new versions of browsers is important. The future of the pdf.js project is somewhat questionable. Its key proponents, Andreas Gal and Chris Jones, have both left Mozilla. Mozilla Labs, which hosted the pdf.js project, was shut down. Active contributors to the GitHub project have petered down to two or three, and it’s unclear if they are employed to work on pdf.js (and if so, if it’s full time), or if they are community volunteers. Either way, pdf.js’ champions have moved on, and it would appear so has Mozilla.
At Apryse, PDF SDKs are our reason for being. PDF is not a side project, it is what we’ve been concentrating on for over a decade. As the software industry continues to evolve, we will advance our offerings to ensure not only are they compatible with the latest technologies but so that they are taking full advantage of them. This commitment is why we are able to offer a multi-platform PDF solution spanning Web/Windows/Linux/Mac/Android/iOS in multiple languages. With Apryse you have a partner who is wholly committed to PDFs, now and for years from now.
Conclusions
pdf.js is certainly the most high profile browser-based PDF renderer. However it is important to understand that the renderer knowingly omits parts of the PDF specification and so displays many PDFs incorrectly. Mozilla has always advocated for the open web, so it is strange that the pdf.js project would be designed to rely on non-standardized behaviour (plus implement only part of the PDF standard at that). Contentment with inconsistent and incorrect PDF rendering harms the entire ecosystem because if low-quality renderers such as pdf.js proliferate, the unreliable rendering will cause individuals to lose trust in the PDF format itself.
Beyond PDF rendering, pdf.js has additional deficiencies: the project is slow to fix bugs, offers little in the way of support and does not support many important PDF features such as form filling and annotations. As for its future, there is little indication that any of the above will change. Pdf.js appears to be losing momentum as Mozilla’s priorities shift away from PDF rendering back to priorities more closely aligned with their core mission.
See our Guide to Evaluating PDF.js for a more in-depth look at PDF.js.
PDFNetJS does not suffer from any of the above problems. Rendering is absolutely reliable and is consistent across browsers. We are wholly committed to the customer and can fix any bugs in short order. We are also here for PDF for the long haul, so as with the rest of our SDKs, you can count on PDFNetJS being updated with new capabilities and to take advantage of whatever changes web browsers bring next.
Please check out PDFNetJS – we think you’ll like what you find.