Roger Dunham
Published September 11, 2024
Updated May 18, 2026
4 min
Splitting a PDF Using Python
Roger Dunham
Summary: PDF splitting is crucial for managing large documents, making it easier to extract specific pages for sharing or processing. Apryse Python SDK simplifies this by providing developers with efficient tools to split PDFs programmatically, ensuring precise control over page extraction and integration into various applications. This enhances productivity and streamlines workflows.
Introduction
Imagine this problem: You have a large PDF containing far more information than a particular user needs. It might be a contract with lots of details, for example, and you want to share the overview of the contract but not the appendices. Why would you want them to have a 1200-page document when their interest is only on pages 20 through 25?
So, how can we take a long PDF and break it up into smaller, easier-to-digest pieces?
You could use a PDF editor, perhaps xodo.com, Xodo PDF Studio, or an app based on Apryse WebViewer.
Any of these would allow you to manually select the pages you want to extract. For example, this is a dialog from Xodo PDF Studio, which offers many ways to split a PDF.
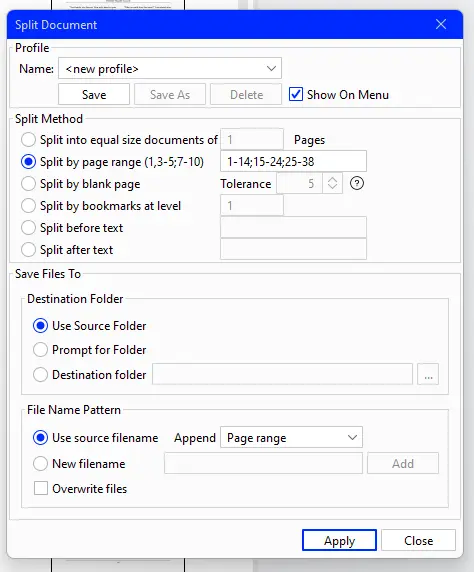
Figure 1 - The Split document dialog in Xodo PDF Studio.
All you need to do is make the appropriate selections and press Apply, and a few moments later, the file will have been split up.
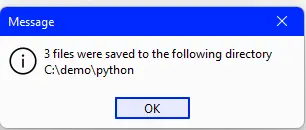
Figure 2 - The result of successfully splitting a document in Xodo PDF Studio.
While Xodo PDF Studio lets you choose a page range, it also allows you to split the document into bookmarks or blank pages, or even before and after specific text, which is pretty awesome, but it does require user interaction.
So what if you want to do this automatically without needing a user to be involved?
In this article, we will look at how we can use the Apryse SDK to split the document using a set of rules that, as a developer, you can define.
I will be using Python, but the SDK is also available for many other languages and frameworks including C++, .NET, Java and Node.js.
The sample code is intended to help you get started, and to illustrate the process. It is not intended to be the basis of robust production ready code.
Getting the Python Apryse SDK
The Python SDK is available for Windows, Linux and macOS, and for Python 2.7 and 3.x. For this article I used Python 3.x running on Windows, but the usage is similar on all platforms.
Step 1: Install the Python SDK
The Apryse SDK is easy to install using pip.
pip install apryse-sdk --extra-index-url=https://pypi.apryse.com Step 2: Get an Apryse Trial Key
If you haven’t already got one, then head to the Apryse website to get a WebViewer trial key.
It’s free to get one, allowing you to check that the SDK gives you everything that you need in your business before you need to buy a commercial license.
Step 3 (Optional): Download the SDK Samples
There is a complete set of sample code full zip file that allows you to explore what the SDK can do. We are not going to use that today, but if you want to go into more detail, the code in this article is loosely based on the sample “PDFPage”.
Let's Get Started
For this example, we will use a PDF that contains the Sherlock Holmes adventures, but the sample code would work just as well with other PDFs, whether they are contracts, legal documents, or even collections of CAD drawings.
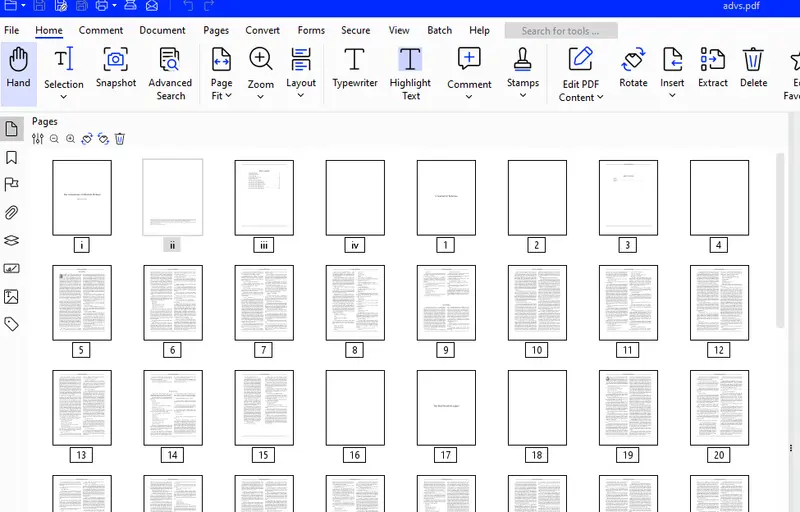
Figure 3 - Thumbnails of the start of the test PDF
The Sherlock Holmes PDF is 162 pages long, so we are going to look at
- Creating a PDF that contains just the first ten pages
- Creating a PDF that contains just the odd pages
- Creating a PDF that contains just the even pages, but without any blank pages
- Creating a set of PDFs, one for each story.
Each example will demonstrate a different aspect of working with the Apryse SDK.
Creating a PDF that contains just the first ten pages
- Open the original document
- Create a new empty document
- Copy pages from the original document to the new one using insertPages
- Save the document
- Close both documents to free up the memory
Now run the code, and in a few moments a new file with just the first ten pages will have been created.
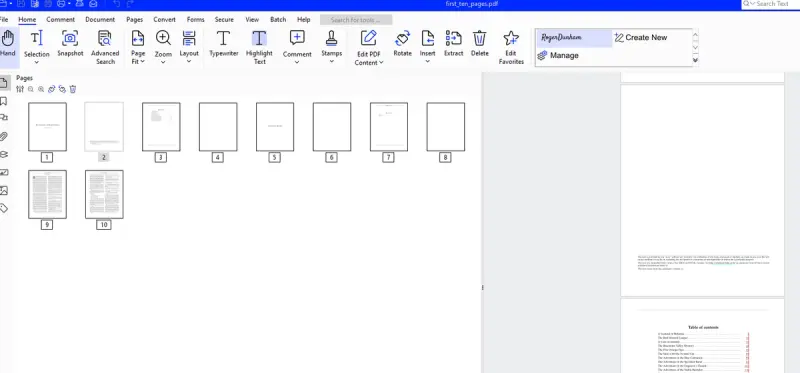
Figure 4 - The resulting document - only the first ten pages are present – exactly as expected.
How the Code Works
In this example, we inserted pages using the first (1) and last page (10) of a range. We have also specified the index of the page (0) before which the new pages should inserted.
The option PDFDoc.e_none indicates that we do not want the pages to be bookmarked. The alternative would be to pass PDFDoc.e_insert_bookmark.
There’s also a little setup code (specifying imports) and specifying the license and original document. That doesn’t change in the following samples, so I won’t repeat them.
Seventeen lines of code (some of which were comments), and you have created a new PDF based on a page range. That’s pretty awesome!
Creating a PDF that just contains the odd pages
So far, we have inserted pages from a contiguous range.
The other way to insert pages is to use a PageSet. PageSets are great if you want to extract non-contiguous or multiple sets of pages. They are also useful if you are interested in extracting just odd, or just even, pages, since they have that functionality built in.
As an example, let's use a PageSet and the filter PageSet.e_odd to just extract the odd pages from the PDF.
Run that code and in a few moments a new file will have been generated containing just the odd pages.

Figure 5 - The generated document, showing pages 9,11, 13 and 15
Creating a PDF that contains just the even pages, without any blank pages
We could tweak the previous sample code to have a PageSet that just contains the even pages. However, the original PDF has many even pages that were blank (it was done so that a new story always started on an odd number page, with a blank page following the title).

Figure 6 - In the original document, many of the even pages (shown in red) contain no text.
That’s quite common in books, but similar things might also be found in business documents, with titles or introductory information that adds little value, which you would like to remove.
So, let’s see one way of removing specific pages. In this case we will get the content for each page and if it is empty then we will discard the page. This is done using TextExtractor to test for empty pages, then adding all non-empty pages to the PageSet using AddPage.
Again, run that code, and a new document will be created, with all of the empty pages removed.

Figure 7 - The generated document - you can see that the two adjacent pages in the image are pages 28 and 34. Pages 30 and 32 were both blank and have been removed.
In addition to generating the new document, this code also logs the pages that were empty (just in case you want to check out what is going on).
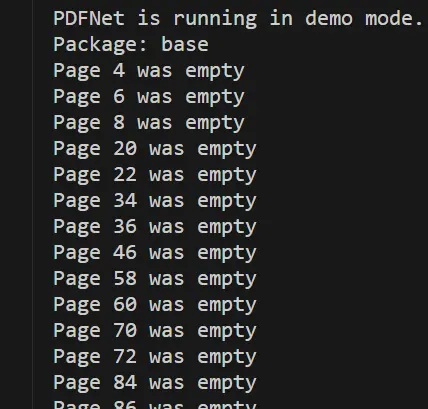
Figure 8 - Typical output showing that pages were found that were empty.
You could extend this sample, so that rather than looking for pages with no text, you could search for ones with specific text and either keep or exclude them, offering you huge flexibility.
Splitting the PDF at bookmarks
As a final step, let's look at how we can find out where the bookmarks are in a PDF, then split the PDF at those bookmarks. This sample borrows code from Bookmark Sample Code (which also shows many other ways to work with bookmarks that we won’t look at here).
It uses PDFDoc.GetFirstBookmark to find the first bookmark, then iterates through that obejct to find othe bookmarks.
The code works by first finding the top-level bookmarks (which relate to the start of each chapter) and creating a list of pages that the bookmarks point to – giving the start pages for each chapter.
The document splitting code takes that list and for each item gets the start page and calculates the last page in the section (the end is either the page before the start of the following section, or for the final section it is the end of the document).
A new document is then generated using that start and end, and saved with the chapter number.
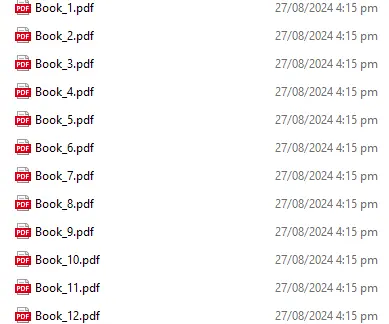
Figure 9 - The code creates a set of files, one for each story.
Had I wanted I could have set the file name to that of the actual story, which is available from the Bookmark objects as you can see from the logging.

Figure 10 - The logging output of the sample code includes the name of the story which was included in the Bookmark.
What’s Next?
The examples we looked at are simple but still cover a range of useful scenarios. The flexibility of working with the Apryse SDK means that you could extend the logic in many ways to suit your requirements.
If you wanted to, you could use the output from Smart Data Extraction to extract header and footer text, then split the document when these change since that might indicate the start and end of sections in a document even if there is no explicit title page.
In fact, by combining the Apryse SDK with Python (or any of the other available languages) there is a huge opportunity to increase the value of your documents by zoning in on those parts that matter the most.
But don’t take my word for it, try it out for yourself.
If you run into any problems, then reach out to us on Discord and our Support Engineers will be happy to help.