Ryan Barr
Published November 15, 2013
Updated May 18, 2026
6 min
High Quality EPUB / HTML From PDF
Ryan Barr

Related Products
Want to create high quality, fixed layout EPUBs from a PDF? Or simply want to show a PDF file in the browser, taking full advantage of the power of HTML and the browser? Or maybe you just want a simple way to integrate PDF viewing into your web application, without the need for any plugins.
Our new PDF to HTML conversion in PDFNet allows for the creation of fixed layout HTML content. It is optimized to create HTML content that balances accuracy of the source material, while not overburdening the browser. Furthermore, PDFNet can also automatically generate EPUB 3.0 files for you.
Benefits of converting PDF to fixed layout HTML
- Viewable on any platform without any need for a plugin.
- Built in text selection and searching.
- Easy to integrate into existing web applications.
- Search engine indexing.
If you want to try the conversion out, there are multiple of ways to get started. You can download our simple DocPub command line utility, or use our PDFNet library.
For details, see our blog.
The conversion process simplifies PDF files down to an image layer and a text layer. This provides accurate appearance of even the most complex PDF files, by utilizing PDFNet’s advanced rendering engine, while retaining vector text. It is critical to the user experience that text be kept in a vector format. It is well established that reading blurry text is slow and tiring for the reader.
Additionally, vector text can be magnified so that regardless of the font size the reader can find a comfortable scale. Finally, by preserving text you allow native selection and search.
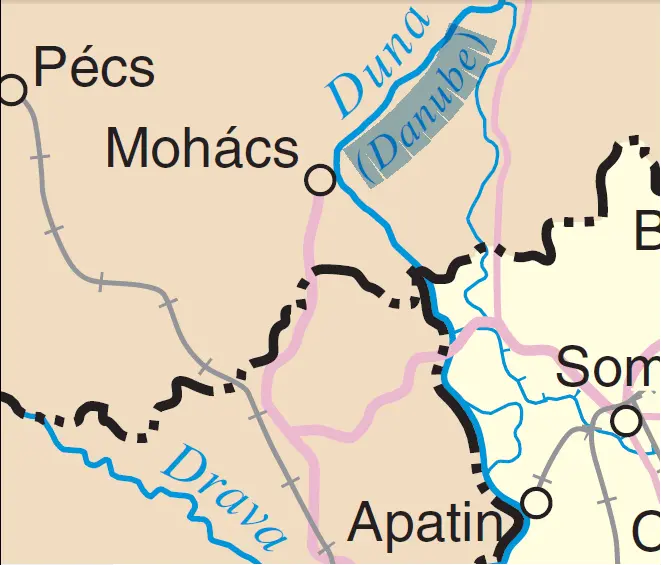
Original PDF
Above is a section of a PDF document, including some selected text. Everything is a vector here, including the text and all the drawing paths; rivers, borders, roads, etc.
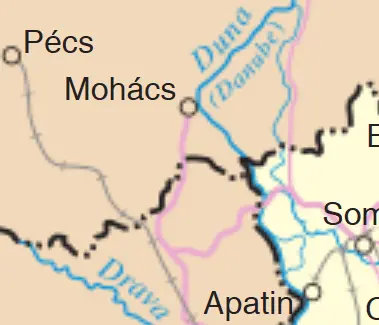
Other vendor HTML output
Next, is a competitor’s HTML output. All the drawing path data has been rasterized of course, as HTML cannot draw paths. However, notice that all the rotated text has also been rasterized also, and is no longer scalable, nor selectable by the user.
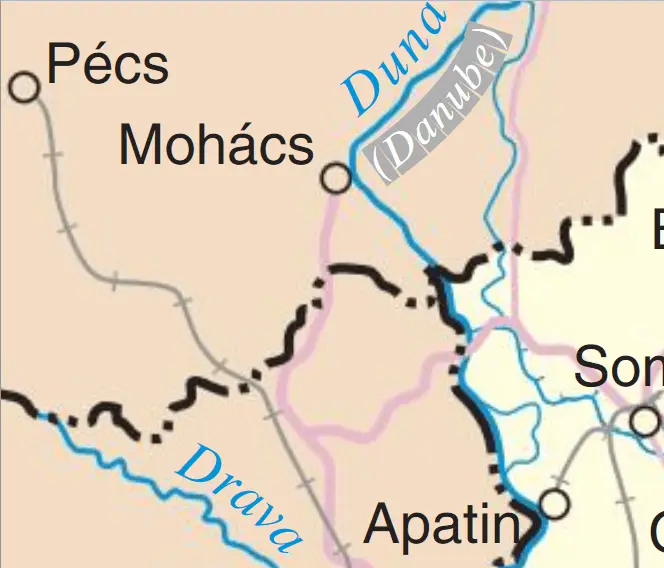
PDFNet HTML conversion
Here is PDFNet’s output. While all the background paths have been rasterized, as expected, all the text, including rotated text, has been preserved, and still selectable, searchable and scalable.
Creating the Background Image… or Flattening
The first step in the PDF to HTML process is what we call flattening. This is the process of merging all non-text elements of a PDF page and converting them into a single background image. While this may sound simple, when taking into account the entire PDF specification, this stage is actually quite complex.
The other major part of this task is determining what text cannot be displayed correctly unless it is also merged into the background image. This typically happens when the color of text is merged with non-uniform/gradient coloring in the background, for which no browser can render correctly. For example the PDF standard supports eleven different blend modes for merging colors.
Another situation where text has to be merged into the background image is when the text is occluded by a non-text element. While PDFNet does the best that it can to avoid these situations, ignoring where text is slightly occluded, sometimes to produce the best result text needs to be ‘flattened’ into the background image. Regardless, the text remains in the HTML output as transparent text elements so that text search and selection work correctly.

Occluded text
Occluded text
Above, on the left is the original PDF, the middle is where the text is correctly merged into the background, and the right image shows how it would look to not merge into the background. Note, that in the middle image, the text ‘Arad’ would still be selectable and searchable, by means of transparent ‘Arad’ text element in the HTML DOM.
Text Placement
While the merging of PDF content into the background image is a complex and difficult task, the placement of the background image into the HTML DOM is trivial. On the other hand, placing text into the HTML DOM with pixel perfect accuracy is not trivial.
The main problem is that you cannot position text directly in HTML, as is done in SVG, XPS, and PDF formats for example. Instead in HTML you place content boxes, and the browser places the text inside the content box based on various HTML and CSS settings, and information from the font itself. To complicate things, not only do different browsers use different information from the font files, but the same browser, on different operating systems, can behave in different ways.
Therefore PDFNet carefully crafts the font files, and then using the information in them, pre-calculates how browsers will place the text inside the content boxes, and places the HTML content boxes to the adjusted position.
Text Optimizing
While the goal of PDF to HTML conversion is to create as accurate as possible conversion of the PDF. This can result in HTML files that are not only very large, but slow to load and render. A major issue is that HTML does not support adjusting the advance width of individual glyphs. Therefore to preserve exact spacing of characters additional HTML elements need to be injected. However, it is often the case that this variable character spacing can be thrown away, or at least merged/simplified so that it appears close to the source PDF document input, but in a much simpler DOM.
Therefore, starting with the latest version of PDFNet, HTML content can be simplified to reduce the complexity of the HTML DOM.
This also has the added side benefit of improving text selection and text searching.
To try it out: enable the SimplifyText option.
Unicode
Another problem with the HTML specification, versus that of PDF, and XPS, formats for example, is that the glyphs that are displayed on the screen, are not differentiated from their unicode values. Unfortunately there are many PDF files that create problems for this, for example specifying characters in the Unicode control code range (U+0001 to U+001F). In these cases, to convince the browser to draw the glyph, the glyph needs to be mapped to the Private Unicode Range. This ensures the browser draws the glyph, and avoids conflicts with existing glyphs in the font. However, this causes gibberish text to appear in text selection and extraction.
Alternatives
While the information above explains some of the reasons to convert to HTML, it is important to understand what other alternatives are available, and the benefits and cost of each.
For a good overview of the alternatives, see the following posting.
If you want to create fixed layout EPUB files, then you should try our HTML converter. On the other hand, converting your PDF documents to HTML provides some interesting benefits, such as a very simple document viewer web application. Other benefits include making your document content available to search engines.
If you have not already done so, give our PDF to HTML conversion a try. While this feature is new to PDFNet, we are confident you will find it one of the best available.
We hope this post gives you an idea of what our PDF to HTML conversion accomplishes, why it generates what it does, and why you might want to use it.