Adam Pez
Published February 12, 2020
Updated May 18, 2026
5 min
Automating Document Redaction in a Web App using JavaScript
Adam Pez

As a commercial PDF SDK vendor, we work with many customers who seek to replace outdated manual redaction methods by streamlining redaction within a PDF-based review & approval or virtual data room app.
These customers must be sure to completely remove sensitive information before documents are shared, as the consequences of a leak can be enormous. Failed PDF redaction has led to several embarrassing legal snafus, while even small redaction errors carry significant liabilities and non-compliance risks where proprietary information, trade secrets, and personal data are concerned. Customers face additional cybersecurity and non-compliance risks when sending documents across a network to an external document processing server to perform redactions.
Working with these customers, we therefore updated the Apryse WebViewer, our JavaScript PDF library, to make integration of professional redaction and redaction automation features simpler and faster than ever before. With WebViewer, users can perform true redaction on their PDF, MS Office, and image files entirely within the modern browser — no user installations or servers required. (Support for additional formats like CAD and TIFF is also available via our server-side SDK.)
The Apryse WebViewer SDK can:
- Automatically find and remove sensitive information such as credit card numbers using advanced regex pattern matching and accurate text-string-based search
- Leverage document templates to specify regions of a page for programmatic redaction
- Streamline manual review within a single highly customizable web UI
- Safely share suggested redactions with other users as part of review/approvals
- Eliminate risks associated with sending unredacted documents across a network
You can see some of WebViewer’s built-in redaction tools first hand via the online demo. Check out our Ultimate Redaction Guide for more information.
Working in Angular? Check out our specific guide to redaction with Angular in WebViewer.
The Challenge — True Redaction in a Browser
According to the PDF ISO specification, professional PDF redaction should be a two-step process:
- Content Identification — Content such as images, parts of images, and text in the document are identified for removal with redaction annotations.
- Content Removal — Content identified for removal are permanently destroyed within the PDF file, after which a redaction mark (usually a black rectangle) is applied over areas where content has been removed.
In addition to content redaction, organizations may require features to sanitize documents of low-level metadata and stored form data which can contain sensitive information. In the case of metadata, that information can include author name, creation date, title, subject, and keywords, as well as various custom data streams.
Limits to Existing Web-based Libraries
When implementing PDF redaction in a browser, organizations have historically faced challenges due to limited web-based editing capabilities.
Indeed, the UI/API of most web libraries allow developers to mask sensitive information with annotations or images layered over top. But these libraries commonly lack features to directly edit the document file and remove embedded text and images, as well as parts of images. Users are later free to lift hidden information off the page with a few keystrokes, often by simply selecting content and then copy/pasting into another window.
Additionally, web libraries commonly lack many or all the features required to automate removal of low-level information hidden from view such as XMP metadata, and stored XFA form data.
Limits to Other Web Solutions
Due to the limitations of most web PDF libraries, developers usually fall back upon one of several workarounds:
Solutions that flatten each page into a large static bitmap and then black out content.
Solutions that rely on deprecated plugin technology.
Solutions that rely on a server to process redactions.
These methods usually destroy sensitive information in the document file — but at a cost.
For example, solutions that flatten each page into a bitmap will inflate document file sizes and reduce searchability and accessibility, as well as text legibility. Even with OCR, the document experience is never the same. (Check out this analysis of the Mueller report for a deep dive.)
Some solutions rely on deprecated plugin technology (e.g., Silverlight and Acrobat). But these introduce well-documented security vulnerabilities, while often limiting users to old browsers such as Internet Explorer.
Lastly, server-based solutions require transfer of sensitive data across a network and potentially into third-party (SaaS) servers in another country. Developers must therefore consider additional server infrastructure and security measures, such as implementing end-to-end encryption, thereby adding further costs, delays, and complexity to the project.
A server component also impacts app scalability across a large user-base, as organizations may be required to purchase additional servers or server licenses to process a growing number of documents.
And where data crosses jurisdictional lines, organizations may encounter further compliance uncertainties and risks.
WebViewer: True Automated Redaction using JavaScript
The WebViewer SDK is a WebAssembly/Asm.js port of the native commercial Apryse SDK (in C++). The result is that WebViewer delivers almost all the same native PDF SDK functionality across the document lifecycle, including document redaction, document editing, and document conversion capabilities — without any servers or other external dependencies required. Indeed, no information leaves the client as users open, view, redact, and save their documents securely, entirely within their web app.
Pure client-side redaction functionality built into WebViewer allows you to streamline and automate the entire redaction process. For example, Webviewer’s advanced (regex) pattern matching and accurate text-string-based search allows organizations to automate identification of personal information with regular expressions such as credit card numbers, as well as unique keywords such as a specific person’s name.
The following expression, when entered into the search field of the online redaction demo — or programmatically — will find and highlight all phone numbers and email addresses:
(\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]?\d{3}[\s.-]?\d{4}?|[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)
Here’s the above sample in action:
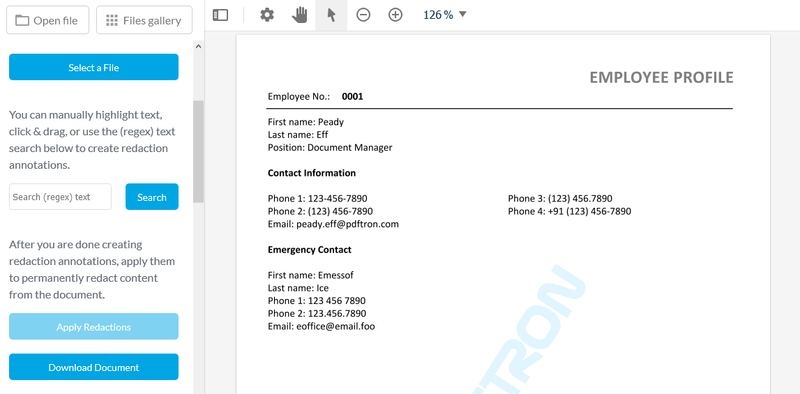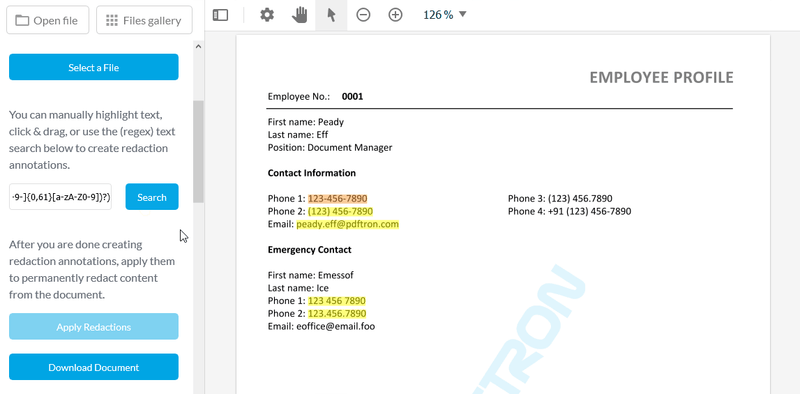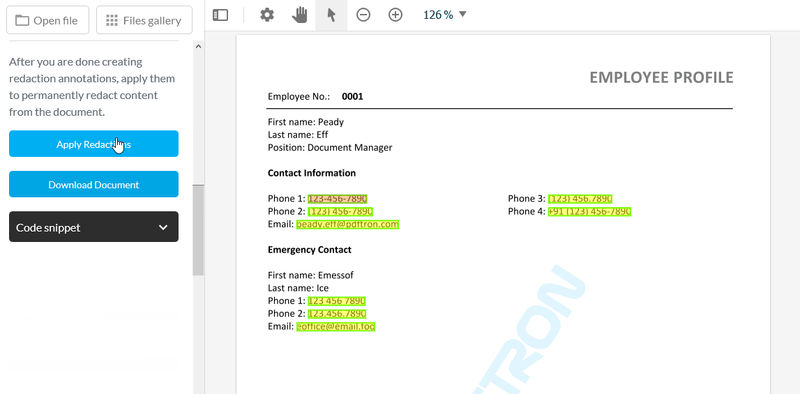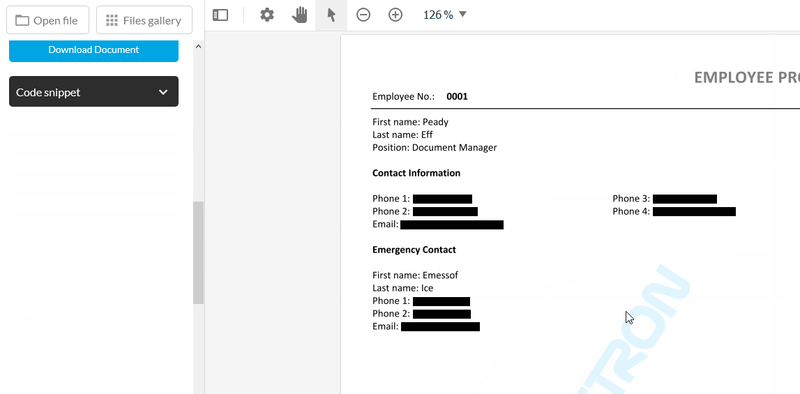
Manual review is also simplified via tools built into the WebViewer UI. These features let users identify content for redaction by selecting text and images — or by drawing a rectangle over top a region, such as part of an image.

Redactions can then be performed individually or in bulk at a couple clicks via the UI — or programmatically via the API — to completely remove identified content from the file, while preserving an original copy of the document. You can also leverage document templates to identify regions of a page for programmatic removal. Just annotate a sample document, and then export/import your redaction annotations onto new documents as an XFDF overlay.
Customization
Apryse redaction functionality comes with a number of options to control the style of the redaction overlay (including options for colors, text, font, border, transparency, redaction codes, and more).
And with WebViewer’s open-source UI and access to hundreds of unique PDF SDK features, it’s easy to customize the UI to your desired look and feel, as well as hook WebViewer into an external workflow.
For example, you can drop in real-time collaboration capabilities to let users share unapplied redactions, plus their other markups, comments, and replies to comments within a separate annotations overlay, featuring fine-grained user access controls and specific user read/write permissions on annotations.
You can also leverage WebViewer’s low-level editing capabilities to automate removal of hidden XMP metadata, document attachments, stored XFA form data, and so on.
The Future and Next Steps
If you’re interested in our Document Understanding functionality, please get in touch with our developers to discuss your unique user and document requirements.
If you’re interested in WebViewer’s redaction automation features, be sure to visit the WebViewer redaction guide and code samples. And for those interested in support for additional file formats such as CAD as well as advanced features such as image diff, also check out the client-side API and the WebViewer deployment guides.
We hope you found this article helpful! If you have any questions or comments, don’t hesitate to contact us.