Andrey Safonov
Director of Product
Published January 28, 2022
Updated May 18, 2026
5 min
How to Capture Feedback on a Live Website via Proxying or Scraping HTML
Andrey Safonov
Director of Product
Related Products
Previously, adding or capturing feedback on live web content was not always easy to do. Which is why we developed Apryse WebViewer HTML.
Apryse WebViewer HTML lets you load live web pages by simply passing any URL or path to your HTML, CSS, and JS content. Users can then annotate this web content easily, enabling reviews in an application via the same rich markup and comment features as they’d use for their PDF, image, and Office files.
Update - Feb. 17, 2022: Try the new website annotation demo
Initially, we showed how you could “scrape” a website for best results with Apryse WebViewer HTML. Working closely with our customers, however, we recently developed a second method for enabling feedback, now bundled into our latest Apryse WebViewer HTML release. This method, proxying, offers more accurate results than with scraping HTML, but it’s not bulletproof in all circumstances.
So, in this post, we take a closer look at both methods, compare pros and cons, and summarize at the end implications for projects.
Scraping the HTML
If you pass a URL that is not on your domain, you will face cross-origin issues – a security measure built into the browser to prevent bad actors from wrapping a legitimate website and capturing any inputs to it.
To get around this issue, we developed two methods to stage live web content for capturing feedback.
The first method we demonstrated lets you scrape the HTML from a website and convert it directly into a PDF file.
In our scraping sample, a user enters a URL they wish to review. Here are steps that happen after:
- The Express server loads the website with the given width and height.
- Next, it stores all the HTML content, assets, scripts and CSS locally.
- The server creates a new link from the same domain as the client and sends it back to the client.
- The client loads the website in Apryse WebViewer HTML without any cross-origin issues.
In this way, scraping takes a snapshot of the website at a single point in time, allowing you to annotate on this version. This means if the website changes, annotations will remain relevant on the snapshot. And if you already store or have full access to your HTML, CSS, JS, etc. on your server, you will not run into any issues with accuracy and can pass the location of your entry point directly to Apryse WebViewer HTML without any server-side dependencies. It’s worth noting however, that in order to annotate on an updated version of the website, the URL must be reloaded (and re-scraped) to obtain a more updated screenshot of the website.
On the other hand, when scraping other external websites, some elements might be scraped improperly or missed altogether. This is not ideal if we are reviewing websites for compliance or want to ensure designs are pixel perfect.
Creating a Proxy
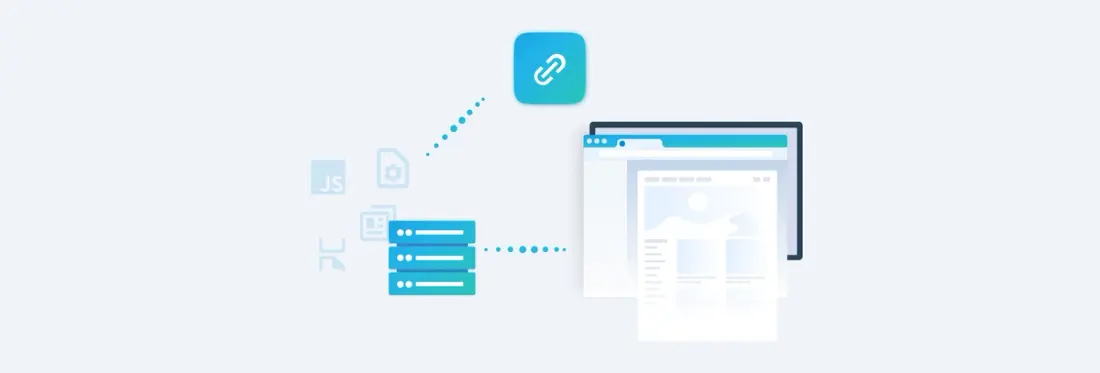
A proxy is a server that acts as an intermediary between you and the resource you are trying to access. Proxying thus also allows you to bypass cross-origin issues and at the same time, very accurately reproduce web content not hosted on your servers.
We have put together a GitHub sample that demonstrates how you can utilize a proxy server to load and annotate any web page.
Here’s how proxying works in Apryse WebViewer HTML:
- The Express server receives the desired URL. (Note: with the latest version of WebViewer HTML, we automatically determine the website page width and height.)
- Express sends back all proxied resources like HTML, CSS, and JS.
- The client loads the resources in WebViewer HTML without any cross-origin issues.
Proxying thus allows us to receive and load the website accurately and exactly how we would view it in a new tab if we navigated to the website ourselves.
There is also no need to store any resources locally on the server with proxying.
On the other hand, since a proxy provides us with a live, real-time view of the website, annotations that are made may no longer be relevant if a developer updates the website. This is unlike scraping, which provides a snapshot rather than a live preview. How do we work around that and ensure our annotations on top of live web content stay relevant? Ideally, you have two staging servers, one (1) for review and another (2) to implement changes onto.
Having two servers allows us to ensure conversations are always in sync on top of content that doesn’t change while developers are still able to implement changes quickly and have stakeholders review and respond to their changes iteratively.
On staging server one, users will be able to add their markups on an accurate representation of the page, having their annotations stay relevant. Meanwhile, on server two, we can implement any reviewer suggestions mentioned by annotations.
A website reviewal process with two servers will then look as follows:
- First, copy over the resources onto staging server 1 as described in steps one to three above.
- We then pause updates to staging server 1 to ensure our copy of the live website doesn’t change as users annotate on top.
- A reviewer then makes comments and suggestions to the website on staging server 1.
- A developer then implements these changes onto staging server 2.
- Any updates to the website made on staging server 2 can then be pushed to staging server 1 so both servers stay in sync with each other.
The Bottom Line
Apryse WebViewer HTML now supports both methods, proxying and scraping, used to load up live websites and enable professional reviews on them via user annotations. The bottom line of when to proxy vs scrape:
When to Scrape the HTML:
- When you want to capture websites as a snapshot in time
- When you do not have access to multiple staging servers
- When you have simple websites without background videos
When to Create a Proxy:
- When you need pixel-perfect accuracy when annotating websites
- When you want to save storage space on your backend setup by not having to store additional resources from scraping
If you would like to learn what else is new in the latest Apryse WebViewer HTML release, we have you covered with a short video on our channel. And if you have any questions or feedback, feel free to email me directly.