Roger Dunham
Ryan Barr
Published August 01, 2024
Updated May 18, 2026
4 min
Using the Apryse SDK to Convert PDF into HTML
Roger Dunham
Ryan Barr

Summary: Learn to convert PDFs to HTML with the Apryse SDK. Follow our step-by-step guide to create HTML pages with the same layout as your PDF using C# and .NET Core on Windows.
Introduction
The Apryse SDK has supported PDF to HTML/EPUB conversion for many years. In this article, we will demonstrate how to create a set of HTML pages with the same fixed layout as the PDF from which they are created.
There are other options for converting PDF to HTML using Apryse. For example, it is possible to create HTML pages with the same content as the PDF but with the text reflowing using the Structured Output module (which can make the content easier to read, particularly if the PDF contains multiple columns of text). These other options, however, will not be covered in this article.
Learn how to convert HTML to PDF.
What is the Apryse SDK?
The Apryse SDK is a software library that gives you access to a wide range of functionality when working with PDFs and many other document types. It supports file conversion, editing, redaction, encryption, and many other operations.
Whether you prefer macOS, Windows, or Linux, the Apryse SDK is available for your platform and in a range of programming languages, including C/C++, Java, Objective-C, Go, Node.js, Python, Ruby, PHP, VB, and C# for both .NET and .NET Core.
In this article, we will look at C# and .NET Core on a Windows platform. If that isn’t exactly your usage, don't fret, the API is consistent enough that you should be able to translate to another language easily.
Action Plan
By the end of this article, you should have a Command line application that can be used to convert a PDF into a set of HTML pages. To make things a little more interesting, we will add some extra requirements:
- Convert only odd-number pages.
- Limit the size of images to 3 megapixels (MP).
- High image quality (DPI).
- Use PNG instead of JPG.
- Allow no HTML hyperlinks to URLs outside of the document.
Prerequisites
You will need to have Visual Studio and .NET Core installed. I used Visual Studio 2022 and .NET Core 6.0, but you should get the same results with other recent versions of Visual Studio and .NET Core.
If you don’t have those available, then head over to https://visualstudio.microsoft.com/.
Getting Started with the Apryse SDK
Step 1: Create a new project in Visual Studio
In Visual Studio, create a new Console App called ConvertToHTML and have it target .NET Core 6.0 (or an alternative version of your choice).
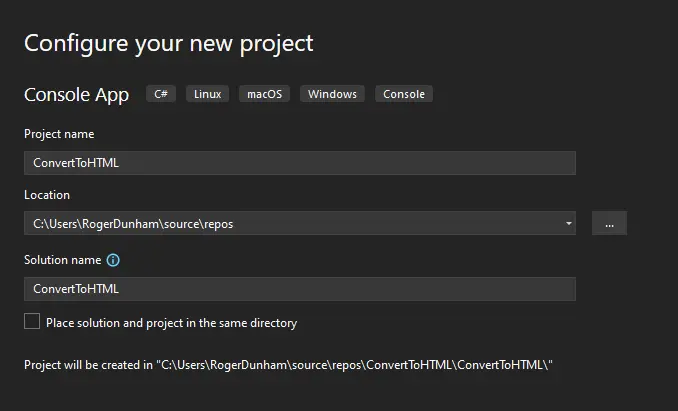
Figure 1 - Setting up the new project in Visual Studio.
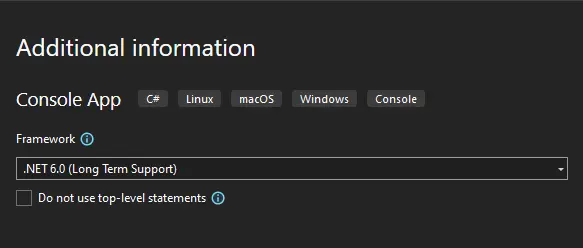
Figure 2 - My project targets .NET 6.0, but other versions are also supported.
Step 2: Add the Apryse SDK via the NuGet package manager
Next add a dependency on the Apryse SDK. You can do this in several ways, but NuGet is one of the simpler methods. Apryse was previously called PDFTron, and the library still has that name. Search for “apryse” then click on PDFTron.NETCore.Windows.x64.
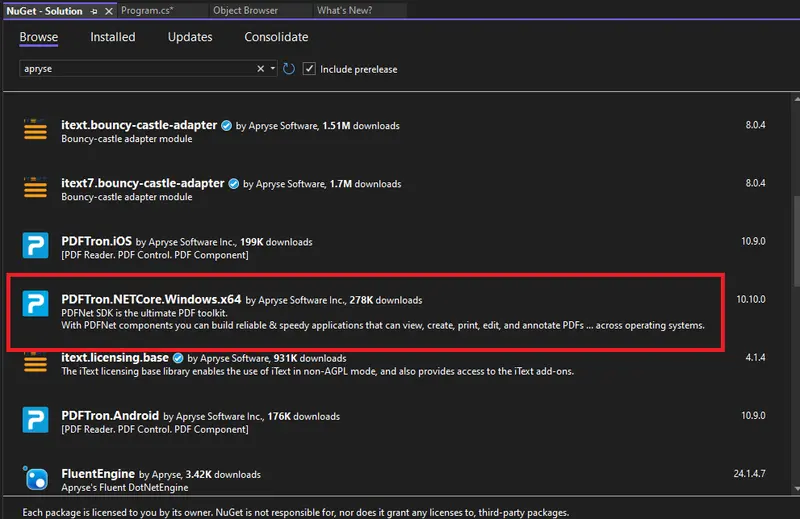
Figure 3 - Adding the Apryse SDK. The version number may be different when you do this, as we regularly ship updates.
Step 3: Copy code into the project
Within Visual Studio, find the project’s Program.cs file, and replace its contents with the following code. We will see a little later in this article how this code works.
Step 4: Create a folder and copy the PDF into it that you want to convert
You can convert just about any PDF into HTML, but in this example, I will use one called newsletter.pdf, which I put into a folder called TestFiles.
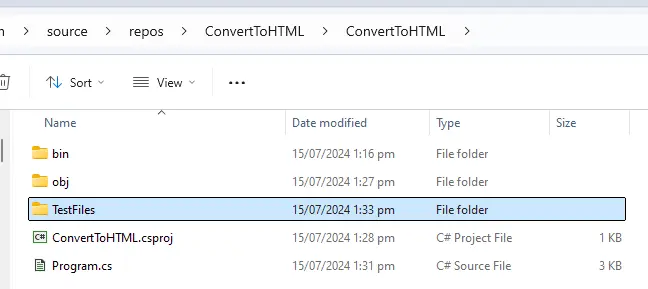
Figure 4 - For this code sample, the file to be converted is expected to be in a folder called TestFiles. You can of course put it wherever you want, but you will need to update the code so that it knows where to find it.
If you choose a different file or put it into a different folder, then you will need to update the code to match the new file location. Making sure that the code uses the correct path and filename is probably the hardest part of the entire process!
Step 5: Run the code
OK, we are ready to go.
Run the code from Visual Studio – after just a moment or two, a new folder will be created that contains a set of HTML pages.
Figure 5 - The output from a successful conversion.
That’s it. You can now click in the new folder and see the files that are present.
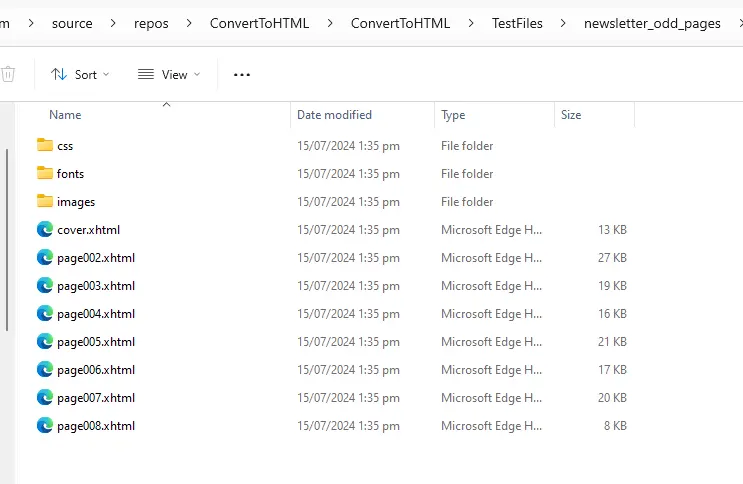
Figure 6 - Once the conversion has been completed, there will be a new folder that contains a set of web pages.
Click on any of those files. Note that the original PDF contained 15 pages, but since we removed the pages with even numbers, we now just have eight .html files.
Click on those files and see the result.

Figure 7 - The resulting HTML generated from the PDF.
How cool is that?
How the code works
Now we have the code working, let’s look at how it works. There are several distinct parts, so we will look at each in turn. Feel free to try changing values and see what different outcomes you get as a result.
Initializing and Terminating PDFNet
Before doing anything else we need to initialize PDFNet, passing in either a trial or commercial license key.
PDFNet.Initialize("[Your license key]"); PDFNet.Terminate(); If you don’t already have a license key, then you can get one from https://www.apryse.com/pws/get-key.
At the end of the method, we call PDFNet.Terminate in order to free any resources that we have used.
Open the PDF and Perform Pre-processing
The next part of the code opens the PDF document as an in-memory object.
The in-memory document can then modified by, in our case, removing the even numbered pages, since one of the requirements was to only export the odd numbered pages. In fact, we could perform many other operations on the document pages, perhaps rotating them, adding annotations, inserting new pages or whatever suited our requirements.
Note: As long as we do not call PDFDoc.Save(), any changes that we have made do not affect the original source file.
Setting Conversion Options
Controlling Hyperlinks
The requirements included that there should be no HTML hyperlinks to URL’s outside of the document, perhaps to prevent the risk of users clicking on links that take them to malicious sites. That is easily achieved by calling options.SetExternalLinks(false);
pdftron.PDF.Convert.HTMLOutputOptions options = new pdftron.PDF.Convert.HTMLOutputOptions();
options.SetInternalLinks(true);
options.SetExternalLinks(false); On the other hand, as we do want to keep links within the document, we can do that by using options.SetInternalLinks(true);
Controlling Image Quality and Size
Next, we need to set up some image options, which are invariably a tradeoff between quality and image size. Our requirements include a maximum image size of 3 megapixels, high image quality, and that PNG should be used instead of JPG. We can control all these as follows:
While we cannot explicitly say to use PNG, we can choose to not use JPG, which results in PNG format being used.
Specifying image quality is done by setting the DPI (Dots per Inch). A value of 300 DPI generally gives high quality images, but feel free to try other values and see how the result differs.
The final image requirement was that the maximum image size should be 3 megapixels. That is easily implement by using options.SetMaximumImagePixels(3000000); This has the effect that if any image was going to contain more pixels than specified, then it will be down-sampled to the highest DPI that will keep it under the limit (in this case 3MP).
Although they weren’t explicit requirements, we included a couple of extra options in our code.
Optimizing Text
A PDF can contain many small pieces of text, each called a “run”, which has a specific font, size and style. By default, each run is converted independently to give a result that looks very similar to the original PDF. The disadvantage of this is that it results in a complex and large document.
Very often though, many of these runs actually have the same style, so that maintaining every one as a separate object has little visible benefit. By using SetSimplifyText we instruct the SDK to try to merge text runs in the PDF file. The resulting differences are typically not noticeable to the human eye, but reduce download, layout, and rendering times.
options.SetSimplifyText(true); Setting the Output scale
Our final option is to set the scale of the generated files.
While browsers have impressive zoom capabilities, the SetScale option can be used in order to make the HTML easier to read in the browser without the need to zoom.
In our code sample we are scaling the output to be twice the size of the original PDF.
options.SetScale(2.0); Can we achieve these results another way?
In this example, we created a command line tool that did some pre-processing of the PDF - in this case keeping just the odd-numbered pages - then converted the resulting document into HTML.
If though, you just want to have a command line tool that will convert a PDF as it is, then we have a prebuilt one available for you.
The DocPub command line conversion tool supports many arguments and gives the same output as we achieved in the code (other than just returning odd-numbered pages).
For exmaple:
docpub.exe -f html --internal_links --prefer_jpg false --dpi 300 --max_image_pixels 3000000 --simplify_text --scale 2.0 newsletter.pdf Check out the documentation for further examples.
Suggested Read: Convert Office documents to PDF directly in the browser using Java — no Microsoft Office installation required.
Conclusion
If you want to convert a PDF to HTML, then the Apryse SDK has your back – offering precise control over how the file is converted and what it contains. Let us know if you have any feedback, it is greatly appreciated! If you have downloaded our free trial and experienced any issues, we offer free trial support. Don’t forget, you can also reach out to us on Discord if you have any issues.