Logan Bittner
Published November 15, 2024
Updated May 18, 2026
5 min
How Misconfigured Dependencies Caused a Sudden Memory Leak
Logan Bittner

On August 1, 2024, at 4 a.m. PT, several health check alarms we have set up for apryse.com were triggered. These alarms indicate that our server was responding with non-200 status codes and that people were unable to view our website. This is a very uncommon occurrence as the website has historically been stable with few issues. These alarms sparked a multi-day investigation into what was discovered to be a fatal memory leak that was periodically taking down our servers.
Identifying the problem
When the alarms were first triggered, the first thing we noticed were the classic “JavaScript heap out of memory” errors in our logs. We immediately knew that our servers were crashing due to running out of memory, but we didn’t know for sure yet that it was an actual memory leak. This was the first thing we needed to confirm.
Unfortunately, EC2 by default does not collect memory metrics without installing the AWS CloudWatch agent, which means we had no way to confirm for sure that the issue was a memory leak.
The first thing we did was install the CloudWatch agent and redeploy our servers. After a few minutes of collecting metrics, we immediately saw the dreaded “upward climb” followed by a crash.
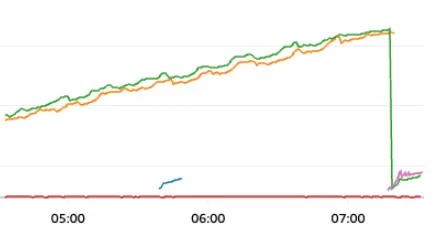
This confirmed our suspicions of a memory leak, and it was time to start investigating what was causing it.
Reproducing the issue
At this point, we knew we had a bad memory leak but had no idea what was causing it. What was especially strange is that we hadn’t deployed any new code around the time that the leak started, which meant the leak seemed to be happening out of nowhere.
We started stepping back through commits and trying to reproduce the memory leak locally using the Chrome memory profiler but failed to reproduce the issue locally.
We tried for hours to reproduce the issue. We downgraded our dependencies, played around with different Node versions, ran load tests to simulate heavy traffic, and pretty much anything else we could think of. But still, we failed to reproduce.
Since we could not reproduce the issue locally, it made us think there might be some platform or dependency discrepancy between our production servers and our local environment. That was the next thing we decided to investigate.
Understanding the deployment pipeline
Our website is currently hosted on AWS Elastic Beanstalk, which is a platform that lets us easily spin up and configure a highly available, load balanced environment. After this incident, we will be moving away from Elastic Beanstalk (more on that later), but for now, this is what we were working with.
Elastic Beanstalk works by bundling your code into a ZIP file, uploading it to S3, and then deploying that code across all your EC2 instances.
The Elastic Beanstalk CLI was a bit of a black box to us, so we assumed that we had to build the website locally before deploying so that the final build was included in the ZIP file. This also means that we thought we were bundling a local copy of our dependencies.
However, we later learned that Elastic Beanstalk reinstalls your dependencies on the EC2 instance during deployment. This on-server installation of dependencies (that we were unaware of) ended up being one of the causes of our memory leak.
A lesson about dependency locking
After looking through some deployment logs, we noticed that Elastic Beanstalk was installing dependencies using NPM, even though locally we use the Yarn package manager.
Any dependencies in your package.json that start with `^` are only pinned to the major version of that dependency. That means if you have `”react”: “^18.0.0”` in your dependencies, you could actually be installing the latest minor version (for example, “18.3.1”).
This is where lock files come in. Lock files are responsible for ensuring you install the exact same dependency tree every time. You can read more about lock files in the NPM documentation.
Yarn and NPM use different lock files. Yarn uses a file called “yarn.lock”, and NPM used a file called “package-lock.json”.
After a bit of digging, we realized that since we use Yarn, our repo only had a “yarn.lock” file, but since Elastic Beanstalk installs dependencies with NPM, it was looking for the “package-lock.json” file. This means that during that on-instance installation phase, we were always getting the latest minor version of every dependency, instead of the dependencies defined in our yarn.lock file.
This explains why we could not reproduce the issue locally - we had different versions of our dependencies locally than what the app was using in production.
Our quick solution to this problem was to switch our repo to use NPM for the time being. Redeploying our application with a package-lock.json file (and therefore pinning our dependencies) resolved the memory leak! This indicated to us that one of our dependencies had introduced a memory leak in one of their latest updates.
However, even though the problem was solved, we still had some unanswered questions.
Out of thin air
The next question we asked ourselves was “how did the memory leak start out of nowhere without any new deployments”?
This one stumped us for a while. We knew the problem was caused by a combination of mismatched package managers and a bad update to a dependency, but we could not figure out how this bad dependency went live into production without us deploying anything.
After snooping around the Elastic Beanstalk UI for a while, we noticed a “managed updates” section. Sure enough, we discovered Elastic Beanstalk automatically upgraded our Node version on July 31 at 11:40PM. This “managed update” triggered a redeployment of our servers, which in turn triggered a reinstallation of our dependencies.
This is how the bad dependency made it into production!
We promptly disabled this managed update feature since we didn’t like the idea of our servers restarting without our knowledge, but at least now we had answers.
Retrospective
We learned a lot from this experience. Here are some of our key takeaways:
Beware the black box
This experience taught us that we didn’t know enough about Elastic Beanstalk and its inner workings. We made too many assumptions about the platform and didn’t truly know how it worked behind the scenes. For example, we didn’t know that Elastic Beanstalk installs your dependencies with NPM on the server (which was ultimately the cause of our issue).
After this experience, we decided to migrate our infrastructure away from Elastic Beanstalk and instead use AWS ECS. We feel ECS is a much more modern, understandable platform that gives us a lot more control.
Pin your dependencies (and containerize)
We also learned to triple check that you use the same package manager locally as in production environments. Not doing so could result in always getting the latest minor version of every dependency in production, which could mean unknowingly installing a dependency with a bad issue, like a memory leak.
Naturally, with our switch to ECS, we containerized our application which is a great way to ensure your dependencies are consistent across different environments.
In hindsight, we should have taken this step a long time ago, but there’s no time like the present!
Auto-scale on memory
Our old Elastic Beanstalk application did auto-scale, but the only trigger was CPU usage. This is because EC2 doesn’t easily provide memory metrics, and auto-scaling on memory is quite a complicated process that we didn’t have time to dive in to.
Luckily, ECS provided memory metrics out of the box and easily lets you auto-scale based on memory. Auto-scaling on memory wouldn’t have prevented our issue, but it would have at least prevented our website from crashing.
Final Thoughts
Ultimately, our memory leak was caused by a bad dependency that was installed due to a mismatch in package managers. Our production servers were always getting the latest version of every dependency, even though we had them pinned locally. This had been going on for years, and only now did it cause a problem.
Situations like this are a great way to learn the ins and outs of your tooling and infrastructure. We learned a lot from this situation, and we took away some really important information and experience that we will utilize in all our projects moving forward.
We’re always happy to hear from you! Please reach out to us if you have any questions.