Josh Coffey
Chief Technology Officer
Published August 23, 2023
Updated February 18, 2026
5 min
How to Accurately Extract PDF Data Using Apryse SDK on .Net with C#
Josh Coffey
Chief Technology Officer

This tutorial explains how you can extract data from PDFs using the Apryse SDK in .Net with C#. We’ll show you how to accurately extract text, tables, and form data from PDF documents programmatically, such as invoices, purchase orders, reports, and many others.
PDF Data Extraction Use Cases
Automating the extraction of data in PDF documents is increasingly necessary in document workflows. Being able to extract text and form field data, analyze financial results, generate reports, and more, means accurately recognizing and extracting content from PDFs is essential.
Overcoming PDF Data Extraction Challenges
Even though PDF is one of the most popular formats for business documents, accessing the data in a PDF scan can be difficult. Since the PDF format was conceived as an output format for displaying documents consistently across many different computers or operating systems, there is no guarantee that content will be accessible. If you’re lucky, the PDF might conform to either the PDF/A or PDF/UA standards, which require content to be structured and meaningfully tagged so that it is easily readable and accessible. More likely, though, you’ll have a PDF with no structure at all, with text stored as characters located somewhere on a page.
However, you can overcome these challenges by using the Apryse SDK Intelligent Document Processing (IDP) add-on. With its powerful Data Extraction capabilities, it enables the automatic recognition and accurate extraction of PDF content as structured JSON or Excel data.
Achieving Accurate Data Extraction From PDF with the Apryse IDP Add-on
This tutorial will guide you through the process of extracting table data from PDFs and exporting it to tabular formatted JSON or Excel XLSX format. Additionally, you will learn how to convert a PDF into structured JSON, providing a comprehensive description of its contents. We'll also demonstrate how to utilize an AI-based algorithm to identify form fields within PDFs and generate a corresponding JSON file containing information about their location and type.
Prerequisites
This guide assumes the developer has a .Net environment preconfigured with Visual Studio. Screenshots in this guide will be from Windows but our .Net IDP tools can be used in either Windows or Linux.
Apryse SDK Trial Key
If you don't already have an Apryse account, go to https://dev.apryse.com and register a new account with Apryse. This allows Apryse to grant you a demo license key which will be used with the Apryse SDK to enable demo functionality.
Developer Portal
Log into https://dev.apryse.com with your registered account. For this guide, we’ll be developing a C# .Net application in Windows so we'll select Windows.
Below the Platform selection is a blurred field with your unique developer trial key. Click Reveal to show the key. Copy and paste this into a text file, as we will need it later for use in your code to enable usage of the Apryse SDK.
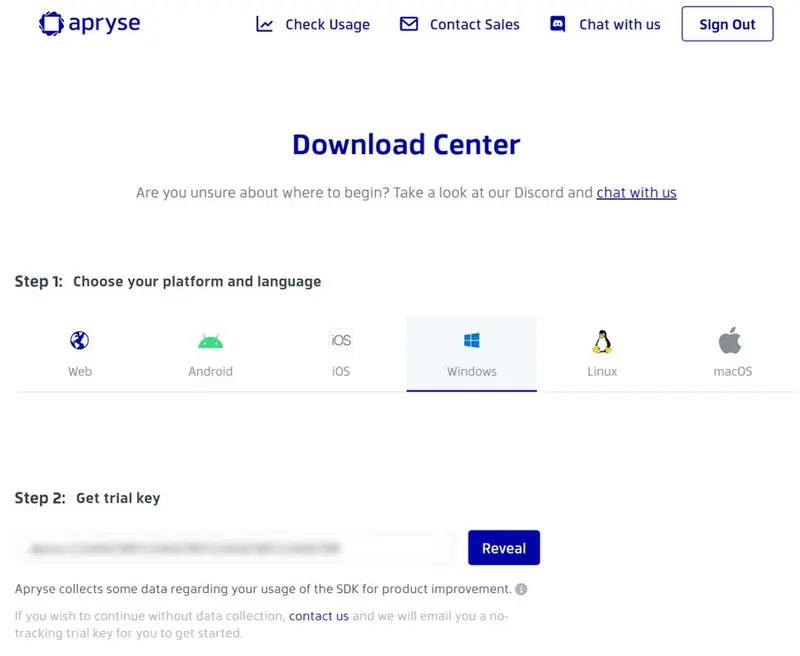
Download Center Platform and Trial Key
Download Apryse Data Extraction Module
Scroll down the page to "Step 4: Get Started". Select JavaScript as the language and expand the "Modules" section. This lists optional binary packages for additional Apryse SDK functionality. We will need the “Data Extraction Module”. Click the download button to download the Data Extraction Module archive. Direct Links are available below:
- Windows: https://pdftron.s3.amazonaws.com/downloads/DataExtractionModuleWindows.zip
- Linux / WSL: https://pdftron.s3.amazonaws.com/downloads/DataExtractionModuleLinux.tar.gz
Download .Net Samples
Now that we have an Apryse SDK Trial Key, we can download and run the Apryse .Net Samples. You can find the download link for the .Net SDK and sample code at: https://docs.apryse.com/documentation/dotnet/get-started/integration/windows/
Extract the downloaded zip file in a convenient location. Inside the Samples folder there are multiple solution files, open the one for your version of Visual Studio. If you are using Visual Studio 2022 or newer, open Samples_2019.sln
Before we can run any of the sample code, we will first need to add our Apryse SDK Trial Key. Open the DataExtractionTest project, open LicenseKey.cs and only modify the following line:
private static string key = "YOUR_PDFTRON_LICENSE_KEY";Replace YOUR_PDFTTRON_LICENSE_KEY with your Apryse SDK Trial Key we created earlier.
Install Data Extraction Module
In order to use the Data Extraction Module, we need to let our application know where to find it. Additional resource paths, such as our Data Extraction Module, can be added to our application using the following method call:
PDFNet.AddResourceSearchPath("./Path/To/Lib/");The sample code expects these libraries to be installed inside the Lib folder of the zipped folder we created. Once combined the Lib folder should contain a folder called PDFNet and a file called PDFNetLoader.dll from the SDK download, and the Windows folder from the Data Extraction Module zip we downloaded.
Run the Data Extraction Sample
We should be able to run the sample code now. Set DataExtractionTestCSXXXX as your startup project by right clicking the solution name in Solution Explorer and selecting "Set as Startup Project". You can then run the project by pressing ctrl-F5.
Terminal output
We can see the results of this by looking at the Samples\TestFiles\Output directory. For each JSON and Excel file, there is a corresponding pdf file in the TestFiles directory used as the input.
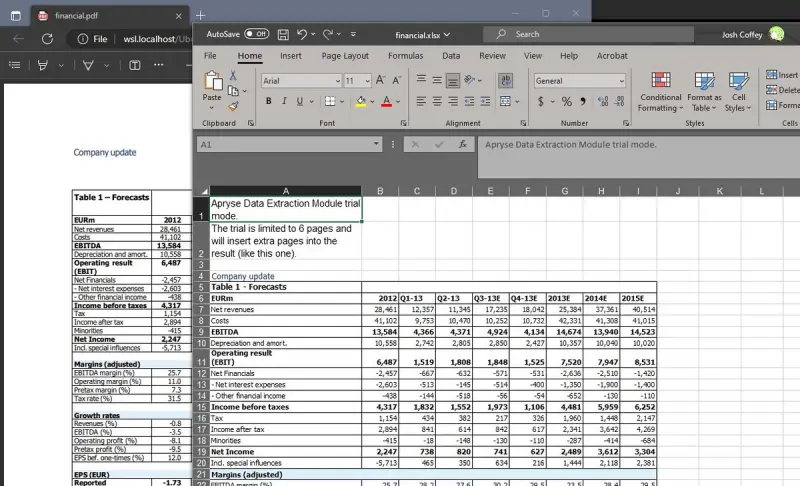
Financial data successfully extracted from a PDF to an Excel file
Next, let’s look at how much code was required for the samples to work. You may be surprised at how easy it is to extract data from a PDF document using the Apryse SDK!
Sample .Net Application for PDF Data Extraction
All of the code we executed is contained in DataExtractionTest.cs. Let’s open it up and take a look at the code required for each of the sample extractions that ran.
The Data Extraction Module has three main APIs, which have been divided into three separate methods within the sample code:
Extracting Tabular Data
The tabular data tests convert some sample PDFs which contain tables into both tabular formatted JSON as well as Excel XLSX files. Conversions performed by the tabular functions will convert all content in the PDF into an Excel or tabular JSON file, so non-tabular data, such as paragraphs, will also be included. If you don’t require this data in the output, you will have to manually remove it post-conversion.
Document Structure Conversion
The second section converts some sample PDFs into a document structure JSON which describes the PDF in its entirety. This JSON will contain a JSON element for every item in the PDF, for example, text, images, graphics, and tables. Each element will have its position data as well as text formatting so that the JSON will be an accurate 1:1 reconstruction of the PDF.
Extracting Form Fields
The third sample block processes a PDF with an AI-based algorithm to produce a JSON document that describes the location and type of detected form fields. This AI will detect forms from not only PDF native forms but also flat non-interactive PDFs containing forms for printing and even from scanned image-based documents.
Conclusion
The sample project demonstrates that you only need a few lines of code to extract data from PDFs using the Apryse SDK and the Data Extraction Module. Visit our Intelligent Data Extraction guide for more details on our cross-platform API, or for more general help with .Net development and the Apryse SDK, visit our developer guides for .Net. If you have any further questions, you can visit our Discord to chat with us.
When you’re ready to add IDP and intelligent data extraction to your existing Apryse Server SDK license, contact our sales team.


