Roger Dunham
Published January 02, 2025
Updated May 18, 2026
6 min
What A Save! An introduction to PDF File structure – Part 1
Roger Dunham

Summary: The PDF file format is undoubtedly one of the most widely used, with billions of PDFs created every year. But have you ever stopped to wonder what happens “behind the scenes”?
In this two-part series, we’ll provide a concise (and simplified) overview of the PDF file format in Part 1, followed by an exploration in Part 2 of how the Apryse PDF SDK can be used to generate PDFs with different underlying structures.
Introduction
The PDF file format is certainly an exceptionally useful format with billions of PDFs being created annually. But have you ever wondered what is going on “under the hood”?
In this two-part series we will see a brief (and rather simplified) explanation of the file format, and then in Part 2 look at how the Apryse SDK can be used to create PDFs with various types of underlying structure.
A Very Simple Overview of PDF File Structure
A quick search of the internet reveals lots of examples of the basic PDF structure. A couple that deserve mention are Ironmoon.net and the PDF Association Cheat Sheet.
Many of these samples that you find online show a simple layout with a header, a body (containing a collection of ‘COS’ objects), a cross-reference table (known as the “xref table”) and a trailer that provides information about where the first object and xref table are located within the file, and the number of objects within the body.
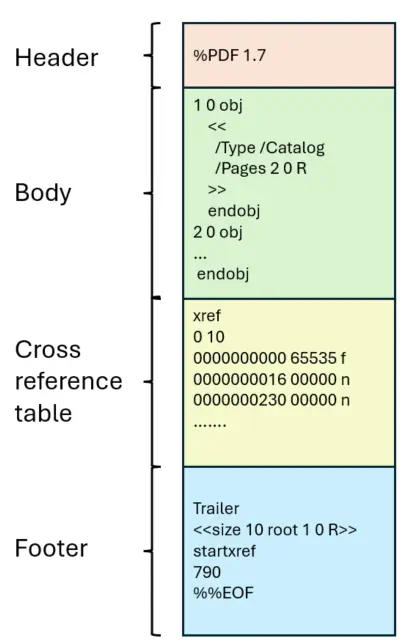
Figure 1 - An example of a simple PDF file structure.
Based on that description of PDF structure, you can create a valid PDF using a text editor (such as NotePad++) that will open in many viewers. In fact, the most difficult part of the process is calculating the start location of the various objects and the xref table – not helped by having to allow for newlines that may be 1 or 2 bytes in length.
We won’t go through all the steps here though – but by all means check out the online samples. For now, let’s look at how you would specify some text that you want to write into the PDF. This is done using a stream – which includes (at the very least) the text that is to be written, the font to be used and an Operator (in this case Tj).
For example, the following code will write the text “Hello World!”
6 0 obj
<</Length 44>>
stream
BT
/F1 24 Tf
175 720 Td
(Hello World!)Tj
ET
endstream
endobj This code has a little more included than the bare minimum – the Td operator specifies the location where the text should be written – although there are other ways to do that.

Figure 2 - A hand crafted PDF, shown within Edge.
Another important part of the PDF specification is the ability for one object to refer to other objects (via an “Indirect Reference”) which you can usually spot by the letter R.
For example, in the following image the Font F1, which is mentioned in object 4, refers to object 5 as <</F1 5 0 R>>.

Figure 3 - Part of the code, illustrating a reference to object 5, which defines the font that is to be used.
A major benefit of using references is that they allow the same object (for example a font) to be used from many different places, rather than having to be redefined each time.
Much of the PDF file structure is ASCII based, so you could edit the code and change the name of the font from Helvetica to Courier.
4 0 obj<</Font <</F1 5 0 R>>>>
endobj
5 0 obj<</Type /Font /Subtype /Type1 /BaseFont /Courier>>
Endobj Note: I’ve added a couple of extra spaces before the “/Courier” so that the object length doesn’t change, and therefore the start location of other objects isn’t affected. (That way we don’t need to update the xref table.)
The modified file can be saved and now when it is opened the text is the same, but the font has changed.
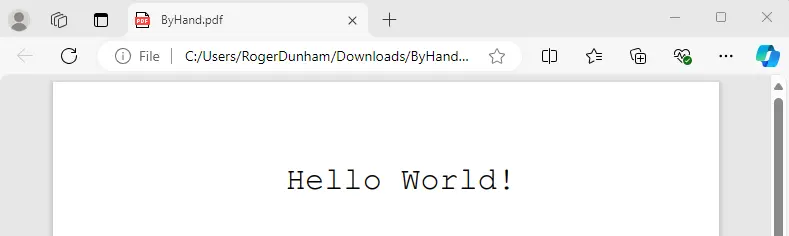
Figure 4 - If you modify the font in the hand-crafted file then the output changes.
Don’t get too carried away with changing fonts in this way – this only works for a limited number of fonts known as the Base 14 fonts. That’s a set of fonts which all PDF viewers are expected to support. If you tried swapping the font name to something else, say “Caveat” then the result is likely to be very variable, particularly if you don’t use a Windows machine.
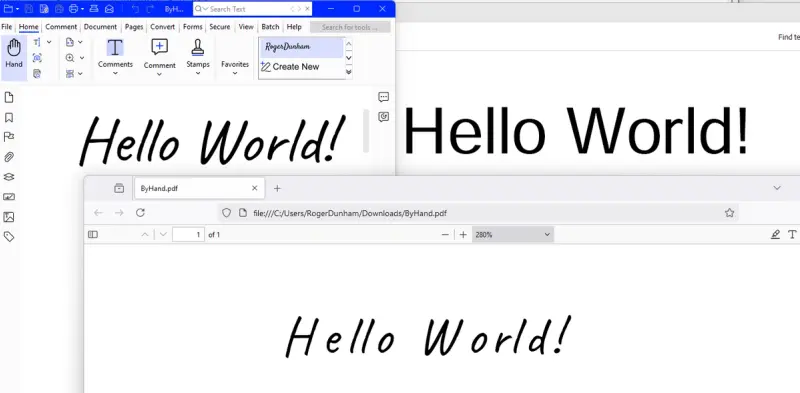
Figure 5 - The same PDF with a badly referenced font (in this case Caveat), shown in three different viewers.
To avoid that, if you are using a font other than the base 14 ones then it will need to have the actual font characters embedded – but that is a whole different story.
Read more about how Apryse handles missing fonts.
By now, though, you are probably thinking that you understand the way that PDFs work.

Figure 6 - ChatGPT agrees that we understand PDFs. As with many things, ChatGPT is not always right.
While everything that we have seen is true, it is not the full story.
This simple file structure has two main problems:
- Any change to the PDF - adding an annotation or deleting a page for example - requires the entire file to be rewritten.
- The PDF viewer app needs to read the entire file right to the very end before it can display anything. It needs the contents of the trailer and the xref-table in order to know what should be shown.
This has led to the development of two further file structures.
Incremental Updates
Incremental updates avoid the problem of having to save the entire file if only a small change has occurred.
Instead, only the changes that have been made (adding an annotation, rotating a page, etc.) are written onto the end of the existing file.
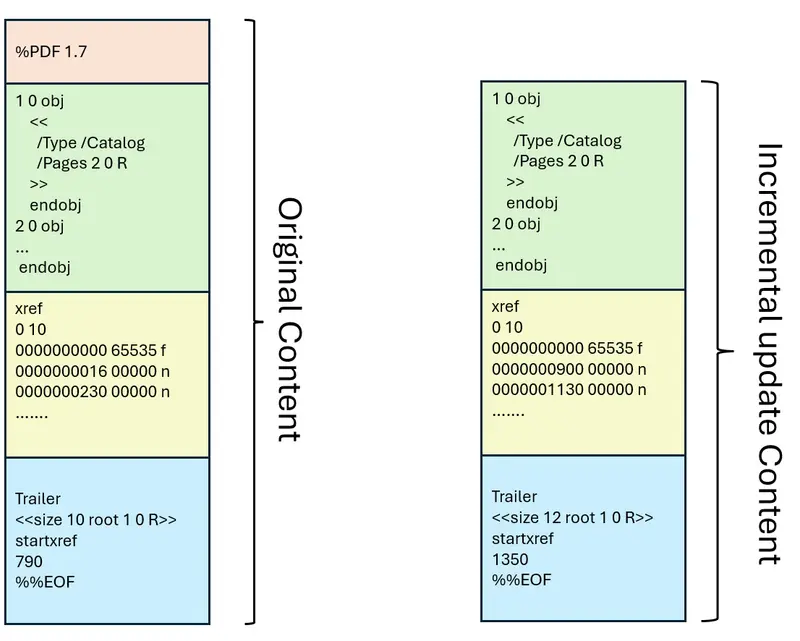
Figure 7 - Any changes made to the original file are appended to the original file as an update block.
When a PDF Viewer loads that file, it reads the original file structure then applies all the changes to get the current version of the PDF, which it then displays.
That’s great if there is just one update. However, there is no limit to the number of updates that can be applied – meaning that the file gets longer and longer, and more and more complicated. As an example, consider a simple PDF, then an extra page is added, which is then rotated, then text is added to the page, and finally the page is deleted. If the PDF is saved after each change, then there are four updates – all of which need to be stored and processed before the PDF can be shown.
In practice though, there could be hundreds of incremental saves.

Figure 8 - Incremental update can result in large, complex files
There’s a second issue too, changes can only be added to the file – even if something is removed.
If, for example, a page is deleted, then an update is created that changes the number of pages, so the deleted page will no longer be shown – but the actual content is still present in the earlier version of the file. We will see an example of this, and how it is a data security risk, when we look at how you can create different file structures using Apryse in the next part of this series.
Linearized Files
As we saw earlier, a problem with the simple file structure is that the entire file needs to be read before anything can be displayed. That might be OK if the file is small and quick to open, but if it is being streamed over the internet then it might take many seconds to download which is an extremely poor user experience.
To avoid the user having nothing to see for a long time, the file is restructured so that the first page's contents are all near each other and at the start of the file. That allows the first page to be rendered before everything has been downloaded.
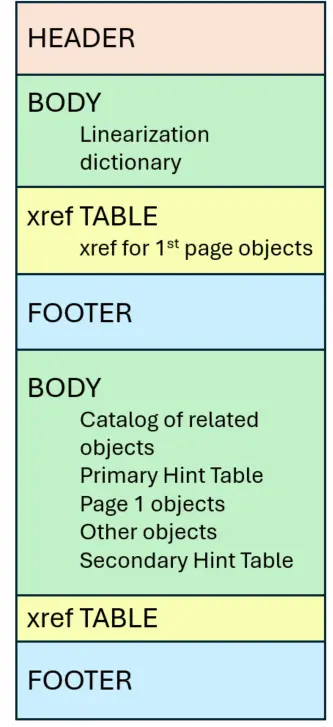
Figure 9 - Simplified structure of Linearized PDF files
The xref table is also located near the start of the file, allowing the user to navigate to a particular page (perhaps page 576). Depending on how the server is set up it may be able to just stream that page next, even though content of other, earlier pages is not yet available. That can save time, and potentially data transfer costs – since there may be some parts of the file that you never need to download.
Read more about PDF Linearization with Apryse.
Summary
There are lots of examples of the way that files are structured on the internet – there are even examples where you can create a PDF entirely by hand. However, unless you want something trivial, those samples don’t really help very much, since more complex file structures (and as we will see, file compression) make hand creation of files nothing more than an amusement.
Thankfully hand creation of files isn’t needed since the Apryse SDK will do the heavy lifting for you, allowing you to concentrate on what most to your business.
We’ll look at how to use the Apryse SDK in the next part of this short series and see how you can control the structure of the file that is created.
Better still, we will see how the Apryse SDK can do much more than just create a PDF (there are, after all, dozens of libraries that will do that), but also allows you to edit, annotate and redact parts of the PDF – functionality that is massively more complex than simple PDF creation.