Roger Dunham
Published February 02, 2024
Updated March 04, 2026
12 min
PDF to Office Document Conversion Using Apryse and Python
Roger Dunham

Summary: Learn how to get started with converting PDFs into editable Office documents using the Apryse SDK and Structured Output module.
Introduction
When you need to transfer information between people, the Portable Document Format (PDF) excels for both presentation and archival purposes. It offers an accurate view of your intended document that (usually) looks the same to the reader, no matter what operating system or hardware they are using.
However, situations may arise where you need to transform PDFs into editable and well-structured Office documents. Maybe a change is needed but the original Word document no longer exists or cannot be found, or the PDF was created from a hard-coded report generator and a minor change like an updated logo is required.
While PDF documents can often be directly edited, non-trivial changes that result in more text than will fit in the available space, or changes in the items within a numbered list, can be extremely difficult and laborious to do and get to look correct. For more advanced and accurate PDF editing features, visit our documentation page on PDF editing.
Learn more about Apryse's PDF and DOCX editor functionality.
Fortunately, the Apryse SDK offers a simple mechanism for converting PDFs into Office documents. This SDK is available for multiple programming languages. Here, we’ll look at how it can be used within a Python application. While this could be used in a standalone application, the same technology can also be used as a way of performing PDF to Office conversions within a web application that is using, for example, PHP.
In this article, you will:
- Learn how to get started with the Python Apryse SDK library.
- See how the SDK samples can be used to convert PDFs into DOCX, PPTX and XLSX Office documents.
- Discover how you can easily build on that knowledge to convert your own documents.
Why Use Apryse to Convert PDF to Office?
With the advanced document processing features Apryse offers, you can not only convert Office documents to PDF, but also reconstruct those documents back from PDF while maintaining their formatting and structure.
With the acquisition of Solid Documents in 2021, Apryse gained access to one of the world’s best document reconstruction library, which is now an optional module available within the Apryse SDK.
Sample Project for Reconstructing a Document from a PDF
The Apryse SDK is available for Python 3, as well as Windows, macOS, and Linux. This library contains a wealth of examples that illustrate the functionality of the SDK, like converting PDFs into Office documents, viewing, editing, and manipulating documents, and viewing CAD drawings, among many other features.
In this article, we will look at the sample for reconstructing an Office document from a PDF. The sample code uses a hard-coded file and places the output into a hard-coded location to simplify setup. In a real-life scenario you would, of course, want to specify which PDF to convert, and what to do with the Office document once the conversion is complete. As such, the code is an example of how to convert a file and see the result, rather than a template of how to write an entire document processing solution.
Prerequisites
The prerequisites depend on the version of Python and the platform.
For Python 3 and Windows you will need Python 3.5 or later and pip installed. For other options, please see the Python documentation at the links above. In this example, I use VSCode, but you can use whatever IDE or CLI you prefer.
If you don't already have one, you will also need a trial license key. You can get this by registering a new account on the Apryse website.
Log into https://dev.apryse.com with your registered account. The SDK is available for Windows, Linux, and macOS, so select the platform that you are using. Next, click on the Reveal button to get your personalized trial key, which may differ between platforms.
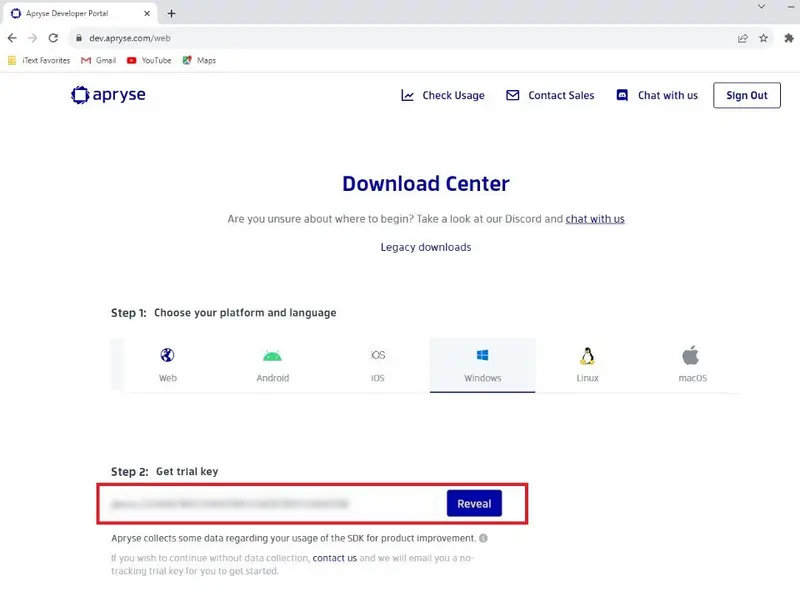
Figure 1 – Download Center platform and trial key
Downloading the Files to Allow PDF to Office Conversion with Python
Having selected the platform and found the trial key, if you scroll a little further, you will see the multitude of languages that are available for download.
You will need the Python samples, the Python SDK, and the Structured Output module, but each of these is downloaded from a different part of the page.
The SDK has installation links and instructions accessed from the section Step 4: Get Started, Python.
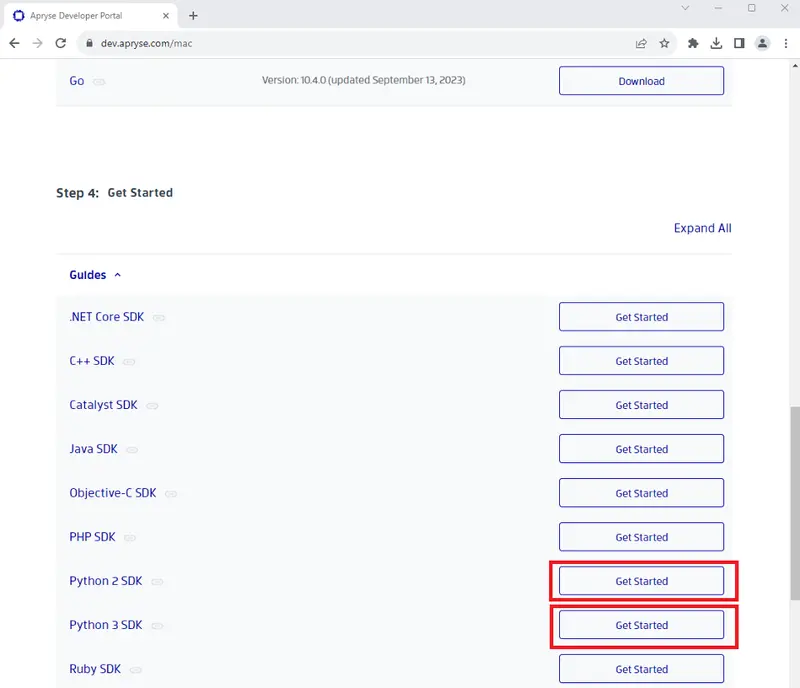
Figure 2 – The installation instruction links for the Python SDK
The SDK for Python 2 is downloadable as a zip or a tarball depending on your platform.
The SDK for Python 3, on the other hand, is installed using pip. We will demonstrate this later in the article.
You can also download a set of samples to help you understand the huge range of functionality that is available. For this article, we will use the samples for Python 3.5+ SDK, which work on both 32- and 64-bit machines. Click on the Download button which you will find in the Step 3: Download section.
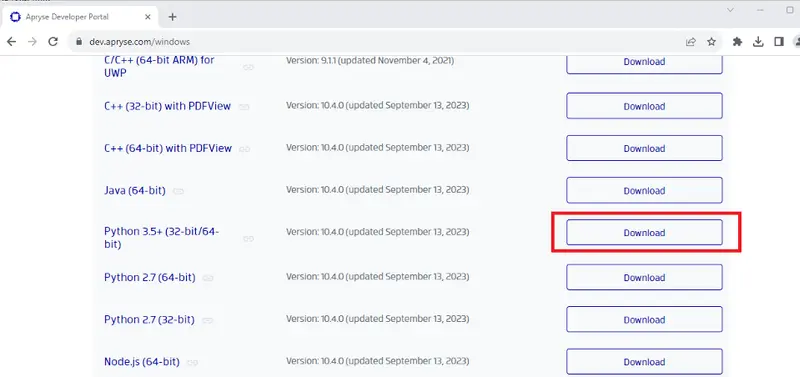
Figure 3 – The button that downloads the samples for the Apryse Python SDK
The samples are in a zip file called PDFNetPython3.zip. (On Linux, the name is slightly different.)
Extract that file to a location of your choice. I chose to extract it to a folder called demo/PDFNetPython3.
Figure 4 – The contents of the downloaded Samples archive after extraction
If you open the Samples folder, you can see the range of samples that are available.
Figure 5 – Some of the many samples that are shipped with the Python SDK
Here, we’re just going to look at the PDF2OfficeTest example.
While many of the samples can be run with nothing other than the SDK, back-converting PDF to Office requires not just the SDK, but also the add-on module “Structured Output”. This is one of several optional modules that provide additional functionality – others include support for computer-aided design (CAD), data extraction, and optical character recognition (OCR).
Figure 6 – How to get the Structured Output module
The Structured Output module is a prebuilt executable which can be used from any of the languages that the Apryse SDK supports, and is compressed for download.
Download the file (which is called StructuredOutputWindows.zip on Windows).
Next, create a folder within the PDFNetPython3 folder called PDFNetC and extract the archive into that folder. If this is done correctly, then a new folder, “lib”, will be present which contains the StructuredOutput.exe file. If this is not present, then something has gone wrong. You can reach out to support and they will be able to help.
Figure 7 – The contents of the lib folder after the Structured Output file has been successfully extracted
Setting Up the PDF to Office Test Project
The sample code takes a PDF and converts it into various Office file formats, either using default or user-specified options.
However, as previously mentioned, unlike the samples for many of the other languages that Apryse supports (C#, C++, and Java), the Python 3 samples do not include the SDK in the download. It is therefore necessary to install it.
You can find full instructions for how to do this on Windows here.
But if, like me, you can’t wait to get started and you haven’t previously installed the SDK, in a CLI enter:
pip install apryse-sdk --extra-index-url=https://pypi.apryse.com
After a few seconds you should see the following:

Figure 8 – Typical output when installing the Python SDK
If you have previously installed the Python SDK, you will need to uninstall the old version and then install the latest version. Note that until 10.6, the files generated by the sample contained “mangled” text unless a commercial license was used.
Before running the samples, you will also need to enter the trial license key that you have already acquired. To do that, copy your actual key into the file LicenseKey.py.
Figure 9 – Entering a license key value into the project
Finally, if you saved the Structured Output module to a location other than the one described above, update the file PDF2OfficeTest.py so that PDFNet.AddResourceSearchPath points to the folder where the StructuredOutput.exe file is located.
Now run the project by navigating to the folder and calling ./RunTest.bat.
After a few seconds, a set of conversions will occur.
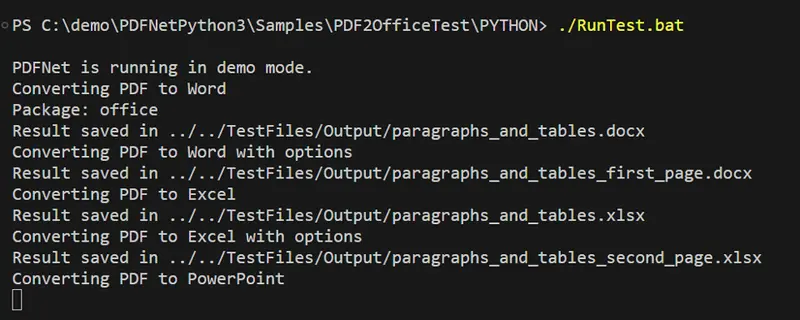
Figure 10 – The output when running the program
Reviewing the Output of the Conversions
Before we look at how the conversions work, let’s look at the results.
Figure 11 – The output folder after the conversion completes
The sample has been set up so that it converts the source PDF into Word, Excel, and PowerPoint.
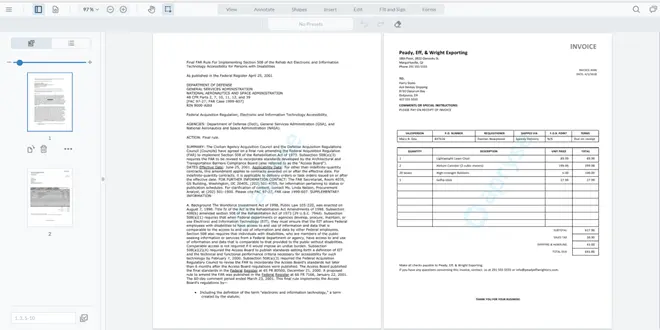
Figure 12 – The original PDF containing a page of text and a page with an invoice and a table
If you look at the Word document that has been created, you can see that it is very similar to the PDF, with line breaks and fonts being the same wherever possible. But now it is editable – exactly the way that you want it.
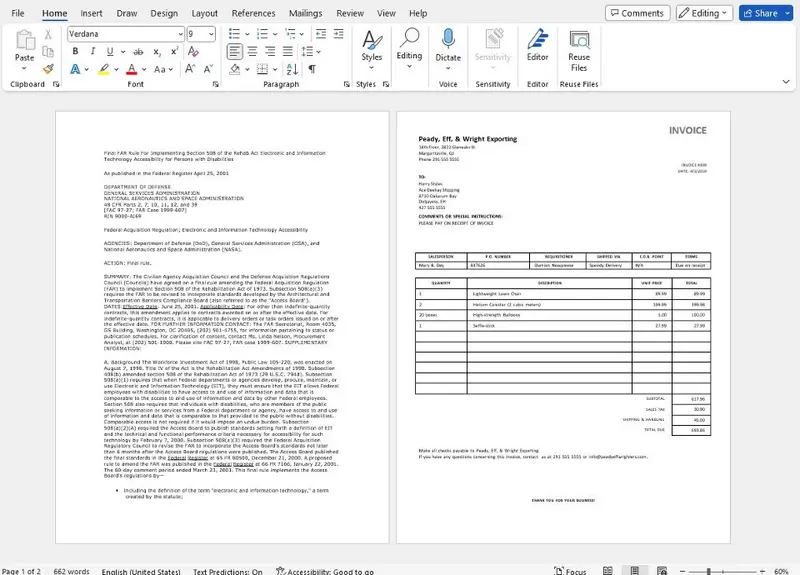
Figure 13 – The reconstructed Word document, shown within Word
Not only has the Word document been recreated, but the line and paragraph breaks are the same in the new document as they were in the PDF. The font face, style, size, and even document headers are preserved during PDF to Office conversion, wherever possible, to match the original layout.
In the same way, the PowerPoint presentation created from the PDF faithfully represents the original file, with each page in the PDF converted into a separate slide.
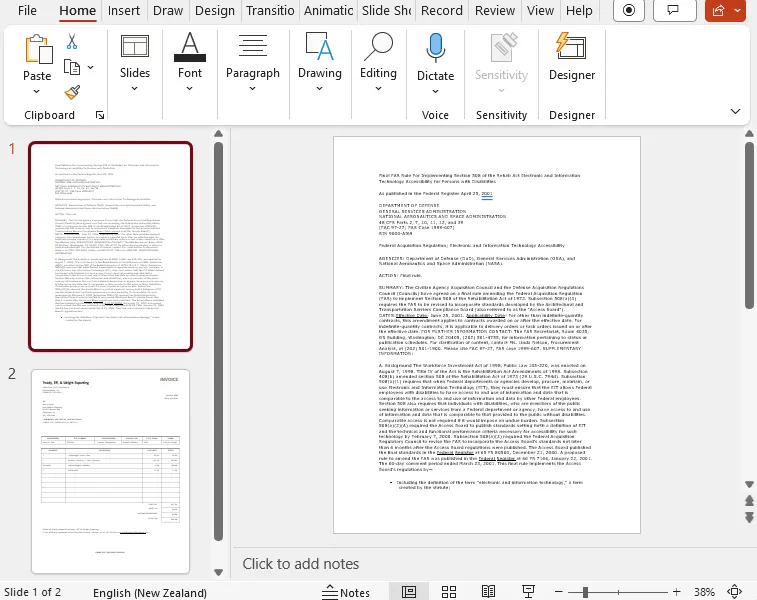
Figure 14 – The file reconstructed as a PowerPoint presentation
It is easy to imagine how a PDF that was created from a Word document should look when it is reconstructed back into a Word document.
It is even easy to imagine how it should look when converted into a PowerPoint presentation.
But how should it look when converted into a spreadsheet? That is a very different format from a Word document, because a spreadsheet is generally created for a different purpose.
Let’s open up the converted XLSX file and see. It certainly doesn’t look like the DOCX document. While it does contain two sheets, neither sheet contains the text from the first page of the PDF.
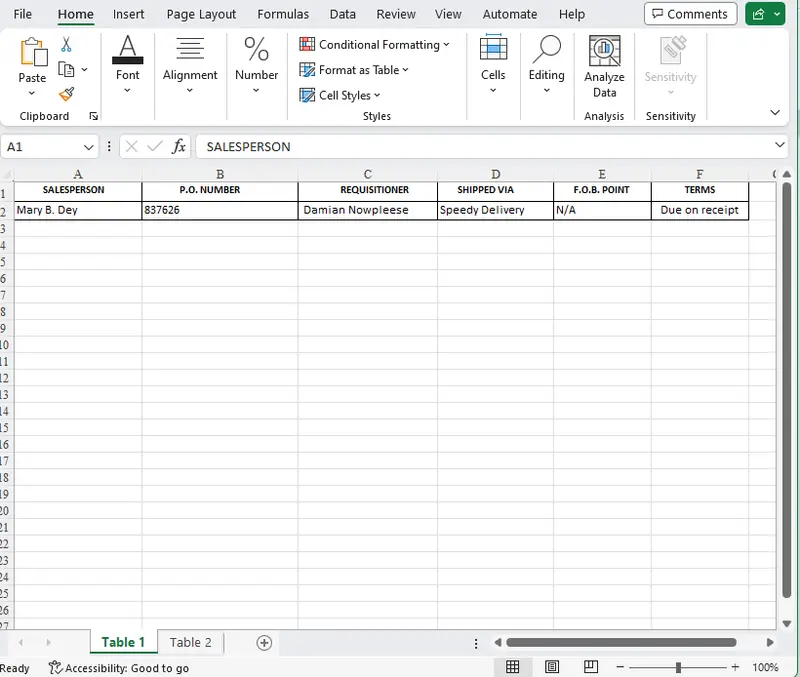
Figure 15 – The first sheet reconstructed from the PDF
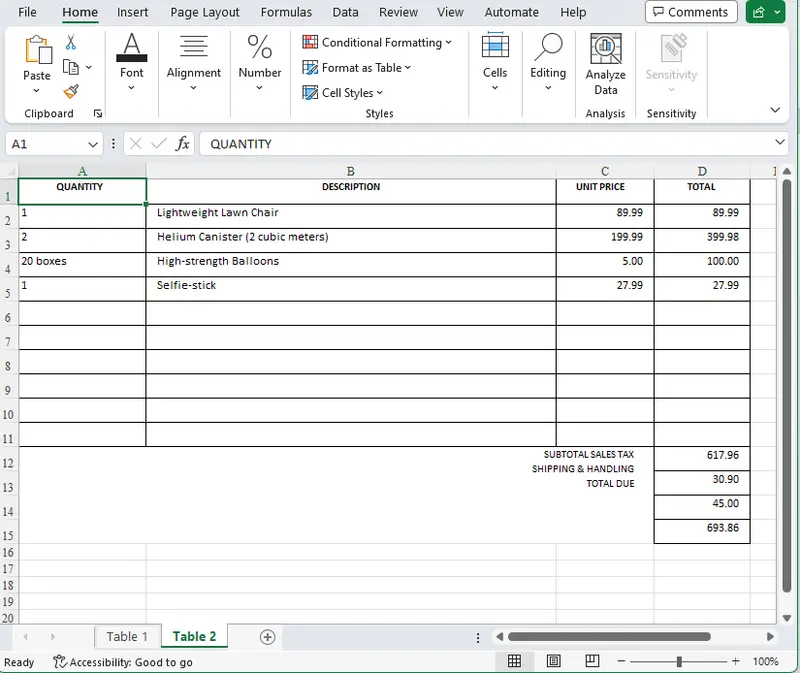
Figure 16 – The second sheet reconstructed from the PDF
What happened is the Structured Output module correctly identified no tabular data on the first page of the PDF. But on the second page, it identified two separate tables.
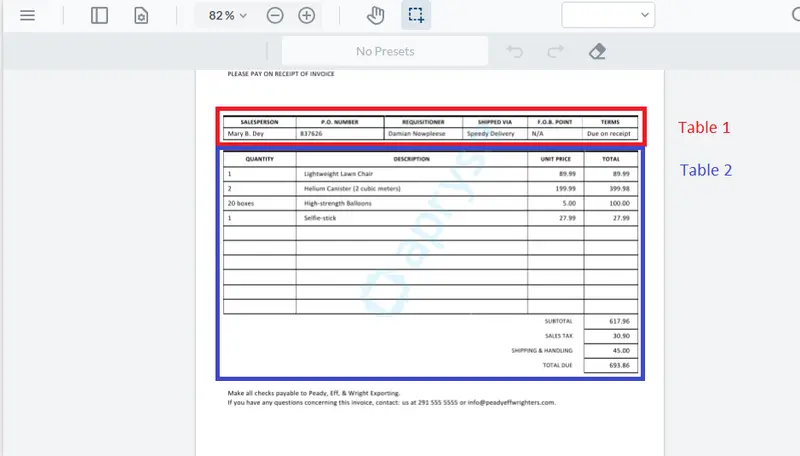
Figure 17 – A detailed view of the second page of the PDF, indicating the two tables that are present
The Structured Output module was developed to be useful, and in most cases, extracting the text from a page containing just text (such as the first page of the sample PDF) into a spreadsheet would have little value. As such, the default options for conversion to Excel from PDF are to discard non-table data (so the whole of the first page is discarded), and to place each identified table onto a separate sheet.
These options can easily be overridden if you need something different, but experience has shown that the default options give the best results for the largest number of users.
This is one way to extract tabular data from PDFs, but Apryse offers other ways too. See the blog posts about extracting data with the Intelligent Document Processing (IDP) add-on for more information about that alternative module.
Using Options for Structured Output
The effect of using options when converting files can be seen in the three remaining files produced by the sample code. These files contain the output of just a single page and were created by specifying a page range in the conversion options.
Figure 18 – The PPTX file created when specifying to use just the first page of the PDF
How the Code Works
The sample code was created to illustrate how easy it is to get started, while giving a hint of the other options available.
At its very simplest, conversion can (after library initialization) be as simple as:
Convert.ToWord(inputPath + "paragraphs_and_tables.pdf", outputFile)That’s right, you can convert a PDF to Word with just a single line of code!
This can be extended to include options by using a WordOutputOptions object. In the following example, the page range is specified, but many other options are supported to fine tune the conversion.
Conversion to Excel or PowerPoint is performed in a similar way, either with or without options, simply by using the ToExcel or ToPowerPoint methods.
Convert.ToExcel(inputPath + "paragraphs_and_tables.pdf", outputFile)It really is that easy.
Reconstructing Word Documents from Scanned PDFs
With no extra effort or coding, the Structured Output module can reconstruct a Word document from a scanned PDF using OCR, provided the scan quality is good enough. The technology is even clever enough to include Word features like lists and tables of contents.
For example, if there are rows with numbers in front of them, these can be interpreted as a numbered list.

Figure 19 – Part of a Word document reconstructed from a scanned PDF. The elements of a numbered list are shown.
This is fantastic from an editing point of view, because if a new item is added to the list or an existing one is deleted or moved, Word deals with the renumbering automatically.
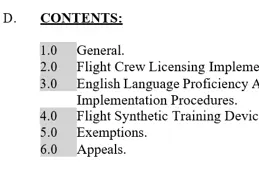
Figure 20 – The same document after the removal of the original item 3.0. Note how the other list items have automatically updated.
Imagine just how much time that will save.
Conclusion
With Apryse's SDK, developers have an efficient and straightforward method for reconstructing Office documents from PDFs.
Whether you’re creating a document recovery tool, an application for content extraction, or any solution that necessitates the reverse conversion of documents, Apryse gives you the essential tools to achieve this task, saving hours of error prone frustration.
This also adds flexibility and efficiency to your document processing workflows and enhances user experience and productivity.
Extensive documentation is available for comprehensive insights into the library’s capabilities, as well as guidance for customizing the reconstruction process to meet your own specific requirements.
If you encounter any issues, remember that you can also reach out to us on Discord for assistance and support. When you are ready to take the next step, contact our team to discuss a commercial license.