Apryse
Published February 12, 2019
Updated May 18, 2026
4 min
How to Build Fast PDF Web Viewing with Linearization and Flattening
Apryse

Related Products
People turn to PDF for its ability to bring a lot of information together onto a single page. A PDF document can store text, vector graphics and fonts, raster images, and much more, and users can reasonably expect that every detail will present the same on virtually any device.
But when it comes to viewing PDFs in a browser, the experience is not always pleasant. Slow display times, especially with large and complex PDFs, can frustrate the user and damage both their productivity and adoption of your app.
In this article, we go over the common factors behind slow PDF display and how you can improve web performance by optimizing files.
Sources of Slowness
There are two main (and obvious) sources of slow display—file complexity and file size.
A complex PDF document usually contains the following:
- Gradients
- Blendings
- Vector images with complex paths
These all require heavy math when rendering in <canvas>. For example, a radial gradient requires all pixels around the center to calculate their values, and an overlap (blending) between two of these gradients creates even more work. Thus, compared to painting raster images, which already have pixel values defined, the rendering process takes longer, especially on machines with a small CPU and RAM.
Other documents might not have any of the above complexities; instead, they may simply contain too much data due to the presence of high resolution images or multiple embedded fonts. PDFs with these objects take longer to download, especially for users without high-speed internet, and thus delay the initial rendering of pages.
Achieving Fast Web View
Two methods can help you compensate for slowness—linearization and flattening.
Linearization allows you to optimize a PDF so it can be “streamed” into a browser, similar to how Youtube videos are streamed in and display quickly after a short period of buffering.
Most PDFs generated today are not linearized. That means the information relating to a particular page is not organized sequentially but is stored in a giant dictionary. Linearizing a PDF file optimizes the document’s internal structure so that pages are arranged from beginning to end (hence the term linearization). The information about this linearized structure then becomes available at the beginning of the file, making it possible for the viewer to determine what chunks of information to fetch and render first, without needing to wait for a large, complex PDF to fully download.
How to Linearize PDFs
Here are the three steps that can enable your solution to use linearized PDFs.
- Linearize your PDFs.
- Set up your client application and document server to send/receive chunks of data through range requests.
- Ensure the PDF viewer in the client application knows how to handle the linearized PDFs.
You could perform linearization of PDFs server-side by leveraging the Apryse SDK, and view linearized PDFs client-side with the Apryse WebViewer. To build a prototype, first download a free trial. Then set up your backend to linearize and save documents. This is possible using C/C++, .NET, .NET Core, Java, Ruby, Python, PHP, Swift and Objective-C.
Next make sure your server supports range requests (verified with ‘Accept-Ranges: bytes’ in the network response header).
Lastly, you can build your client application to embed the Apryse WebViewer, which automatically makes range requests and knows how to handle linearized PDFs. See WebViewer’s Getting Started Guide for details.
How to Flatten PDFs
The second method, flattening, as its name implies, can dramatically decrease both the complexity and size of a document by streamlining the file. There are two different types of flattening: annotation flattening and content flattening. Flattening annotations will move them into the content stream, meaning the annotations will no longer be interactable. This usually has little impact on the UX because most annotations are simple vectors.
In contrast, content “flattening” rasterizes vector images into pixels, and mergers layers together into one (except for the text, which remains over top in a vector format). Content flattening in this manner could be performed as a pre-processing of the document before the file gets delivered to users. However, since content flattening involves trade-offs such as decreased image quality, you should understand and test your flattened documents before serving them to users.
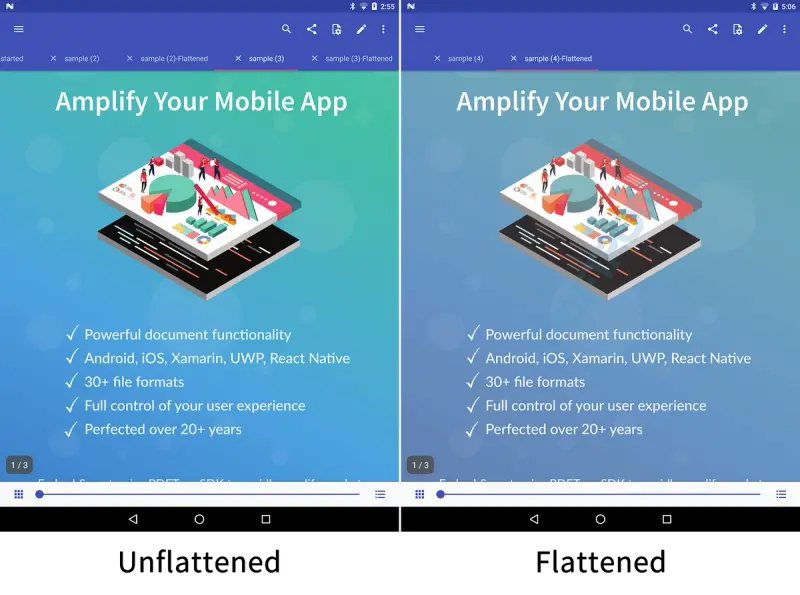
The following Java sample enables your backend to leverage the Apryse SDK to flatten both PDF annotations and content.
Conclusion
PDF is powerful. But it is important to acknowledge how its building blocks can impact web display times. Following the steps above, you can optimize PDFs for fast web view and make the user’s browser viewing experience that much more delightful.
If you’ve found either of the above methods helpful, or if you have feedback, drop us a line. We’d love to hear from you.