INDUSTRY LEADERS RELY ON APRYSE




Pharma & Life Science Document Processing Use Cases
Document processing SDKs to enhance clinical development, ensure compliance, and optimize quality management workflows


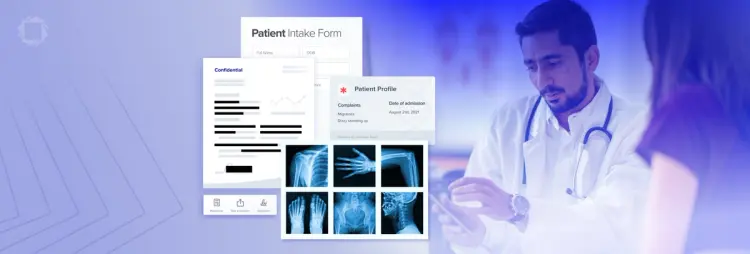
Clinical Trial Complexity
Inconsistent file formats in clinical trial workflows complicate data accuracy and reporting. Standardize clinical trial documentation by transforming unstructured data into the proper format with OCR and AI technology, simplifying patient data-sharing across Electronic Health Record (EHR) systems and Clinical Trial Management Systems (CTMS) while also tracking every file interaction and submission for real-world data (RWD) analysis.




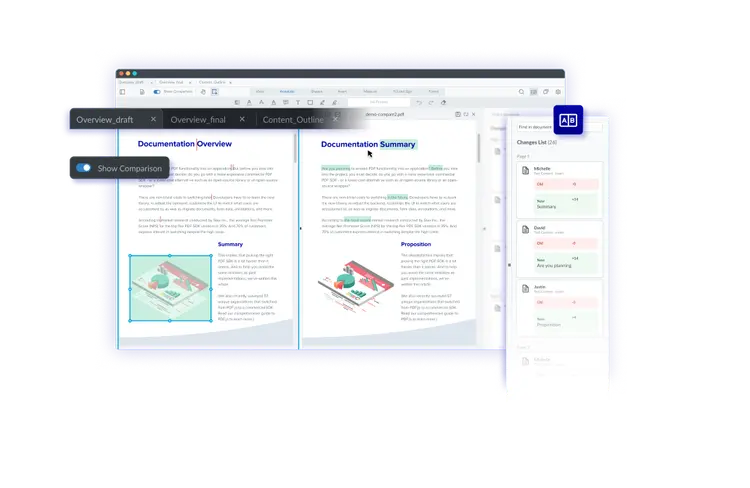
Document Manipulation Features


SOC2
Apryse prioritizes security compliance as critical requirement and necessary investment to support the rigorous data requirements of our pharmaceutical customers. Our information security practices, policies, procedures, and operations meet the SOC 2 standards for security. Additionally, we also have products which have obtained ISO 27001:2017 certification of its Information Security Management Systems (ISMS).
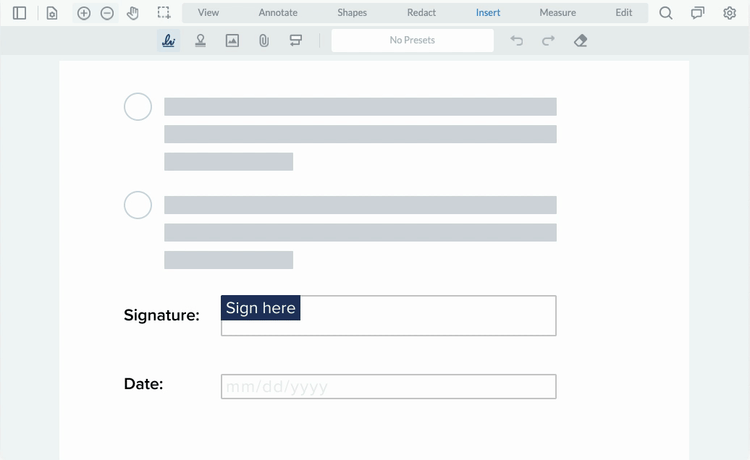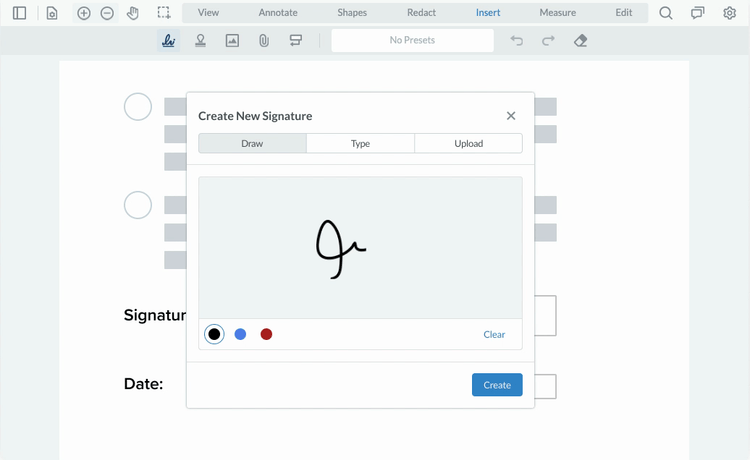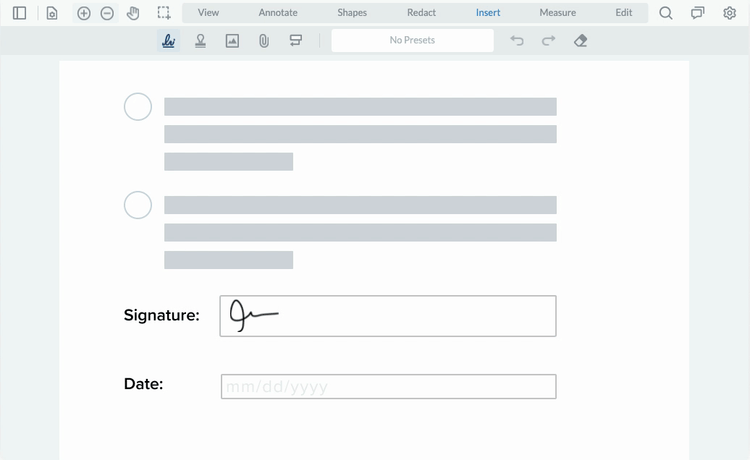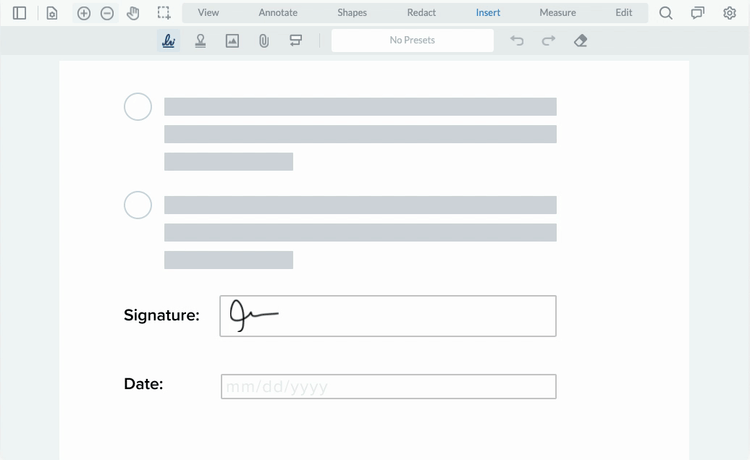
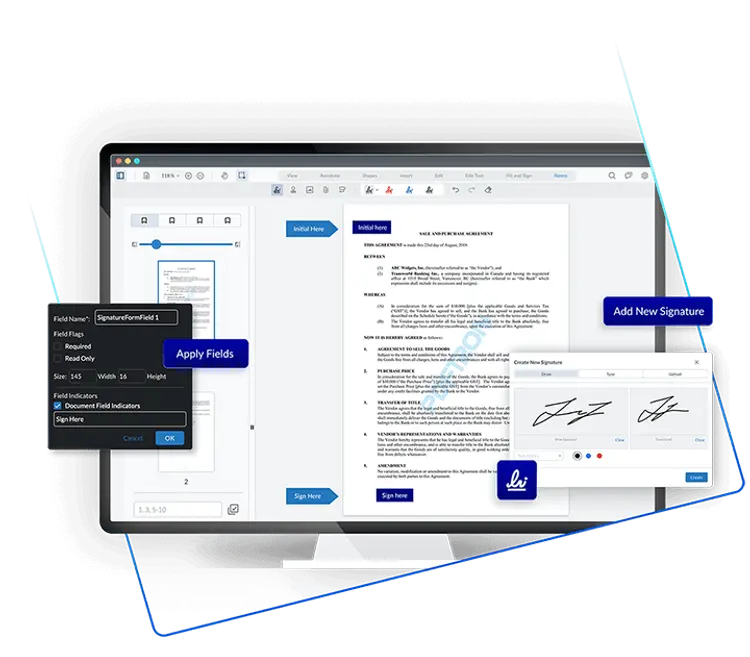
Document Security Features
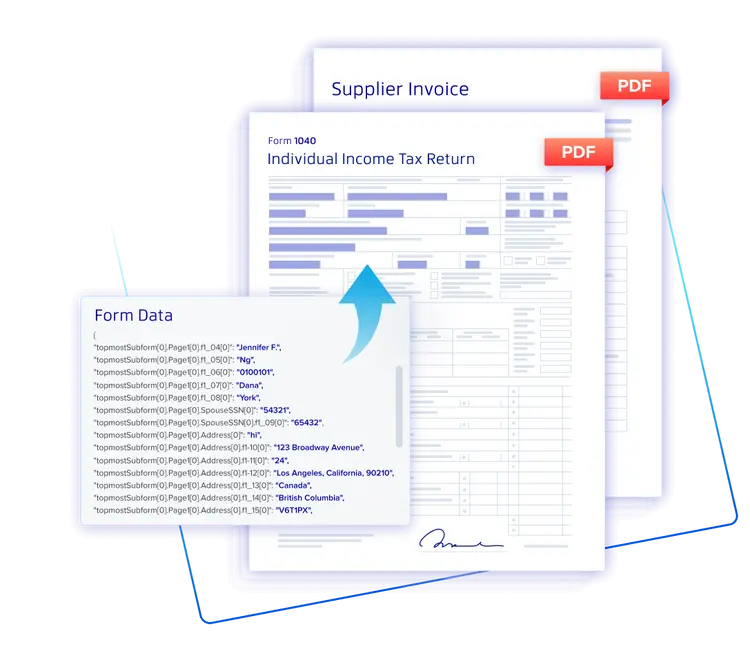
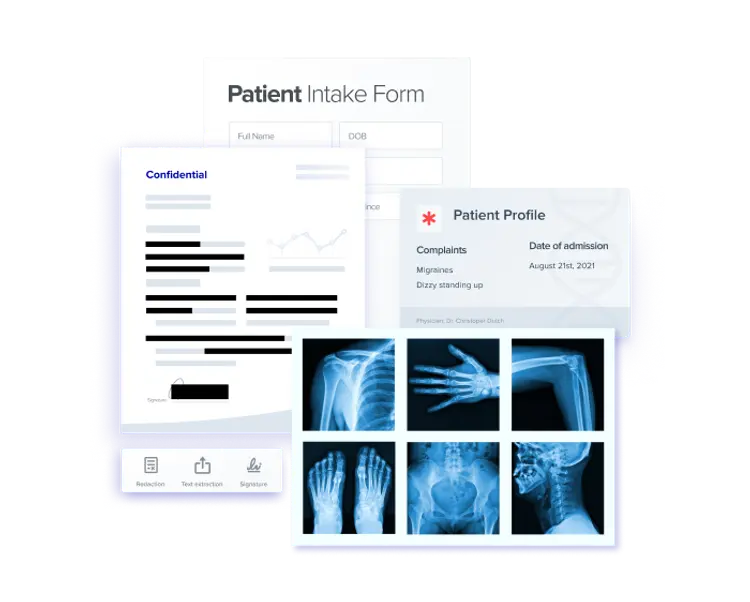

The Most Complete Suite of Document Processing SDKs on the Market
Our SDKs, pre-built components and end-user SaaS applications enable the world’s leading pharma and life science companies to easily generate, convert, view, edit, and sign documents within their applications and workflows.
Loved by Developers
Apryse offers easy-to-deploy developer tools for server, mobile, and client-side document processing. These tools enable developers to push forward strategic initiatives, such as process automation and digital self-service, while also adhering to regulatory standards.

Accelerate projects with our team of experienced SDK developers. We offer support through your unlimited trial to the finish line, and beyond.

Eliminate potential vulnerabilities. No outside dependencies mean you can deploy on your infrastructure without data ever leaving your platform.

Be ready for what comes next. Adapt your product at the speed of user needs with Apryse’s full-featured developer suite that scales with you.