Roger Dunham
Published December 20, 2023
Updated May 18, 2026
7 min
PDF to Office Document Conversion using Apryse and C# on .NET Core – With Sample
Roger Dunham

Summary
Learn how to set up a C# project from scratch that will efficiently convert a PDF into an Office document without disrupting structured data. The options shown work for both born-digital and scanned PDFs.
Introduction
In the digital age, working with documents often involves dealing with various formats. While Portable Document Format (PDF) is excellent for presentation and archiving, there are times when these documents need to be edited.
While PDF documents can often be directly edited, non-trivial changes that result in more text than will fit in the available space, or changes in the items within a numbered list, can be extremely difficult and laborious to do, and can be very time-consuming to get to look correct.
Fortunately, the Apryse SDK offers a mechanism for converting PDFs into Office documents. This SDK is available for multiple programming languages including C#, C++, Java, Python, Go, Ruby and JavaScript.
In this article we will:
- See why converting a PDF into Office is useful
- Create a simple C# project, from scratch, that will convert a PDF into a Word document
- Look at the options available for creating other document types from PDF.
Learn more about Apryse's PDF and DOCX editor functionality.
Why Apryse for PDF to Office Conversion?
Apryse has earned its reputation as a leading provider of PDF manipulation and document generation tools, and its C# library extends its capabilities to the realm of .NET development.
Furthermore, with Apryse advanced document processing features, you can not only convert Office documents to PDF but also reconstruct those documents back from PDF, maintaining their formatting and structure.
With the acquisition of Solid Documents in 2021, Apryse gained access to the world’s best document reconstruction library, which is now an optional module available within the Apryse SDK.
Sample Project for Reconstructing a Document from a PDF
The Apryse C# SDK is available for Windows, Linux and macOS. In addition to the actual SDK, there are a wealth of examples that illustrate the functionality of the SDK, not just for converting PDFs into Office documents, but also for viewing, editing and manipulating documents, and viewing CAD drawings, among many other features.
In this article we will look at the sample for reconstructing an Office document from a PDF. If you are interested in going the other way, then have a look at converting an Office document into a PDF.
In order to simplify the set-up, the sample code uses a hard-coded file, and places the output into a hard-coded location. In a real-life scenario you would want to specify which PDF is to be converted, and what to do with the generated Office document, and of course that is possible. As such, the sample code should be seen as an example of how to convert a file and see the result, rather than as a template of how to write an entire document processing solution.
Getting Started
If you don't already have an Apryse account, go to https://dev.apryse.com and register a new account. This allows Apryse to grant you a demo license key which will be used with the Apryse SDK to enable demo functionality.
There is a great guide to getting started available from https://docs.apryse.com/try-now/ which will lead you through the steps to creating an application on Windows, macOS or Linux, but in this article, I will create a simple app from scratch on Windows.
You can, if you wish, use the pre-built sample PdfToOfficeTest which is shipped as one of the many SDK sample, and we will touch on how to do that, but will not go into great detail.
For this article I will use VSCode for development and NuGet to install the Apryse SDK.
Prerequisites
You will need VSCode with the C# extension (or another IDE) installed. You will also need a version of the .NET framework installed (in my case I used .net 8.0).
Setting Up Your Project
- Create a new folder with the name myNetCorePDFToOffice.
- Open that folder within VSCode.
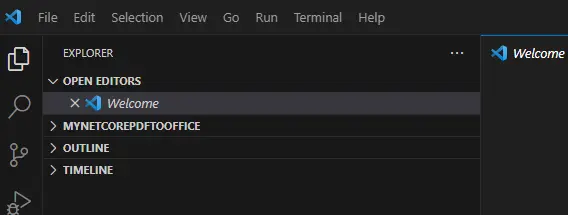
Figure 1 - a view of the folder in VSCode before creating the stub project.
Within a terminal enter dotnet new console --framework net8.0. This will create a stub project.
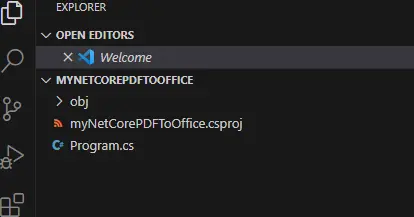
Figure 2 - a view of the folder in VSCode after the stub project has been created.
In the terminal, download the Apryse library using dotnet add package PDFTron.NET.x64. This will install the latest version using NuGet.
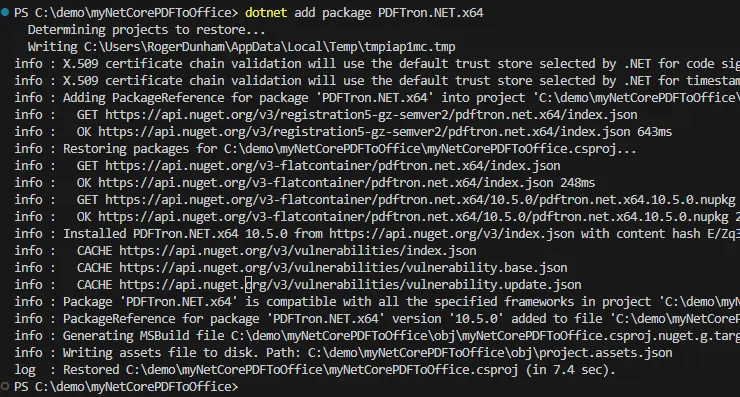
Figure 3 - Installing the Apryse (PDFTron) SDK.
Get the Structured Output module. PDF to Office conversion is performed within the Structured Output module, which is not accessible via NuGet, and must be downloaded manually from the Apryse website. You can find it in the Modules section of the page for your platform (e.g. https://dev.apryse.com/windows).
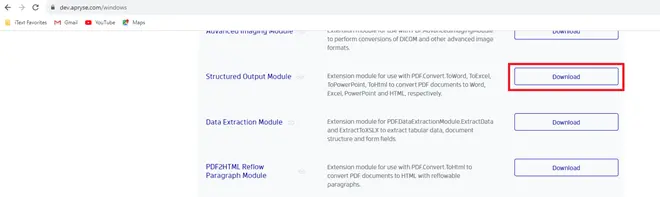
Figure 4 - The Apryse website indicating where to download the Structured Output module.
Once the module has downloaded, unzip the archive. You will need to know where the files are located. In my case I placed them as a sibling to my project folder.
Figure 5 - Folder structure indicating the location for the Structured Output executable files.
Copy the following code into program.cs. This code is an extremely basic example, and doesn’t show any of the myriad of options that are supported. It is intended solely to show Office document creation from a PDF at its simplest.
Update the license code that you downloaded earlier (or if skipped that part you can get one here).
Note: this sample code has a hardcoded location for the file that is to be converted, which should be located in a folder called TestFiles. The converted file will be placed into the same folder.
Figure 6 - The folder that contains the file that will be converted.
Run the program using dotnet run. (Note: If you use F5 then you will be informed that VSCode wants to add some extra files to support debugging, which is OK.)
Figure 7 - Typical output when running the code.
After a few moments a new DOCX file will appear. The Structured Output module is self-contained and there is no requirement for Office (or any other Word processing package) to be installed on the machine.
Figure 8 - The same folder as in Figure 6, but after the conversion has occurred. A new DOCX file has been created.
Let’s open that file – if Office is not installed then you can copy it to another machine to do so.
In versions of Apryse prior to 10.6.0, the generated document would contain jumbled up words if a trial license key was used for the conversion. If you see this, then please update to the latest version of the SDK and Structured Output module.
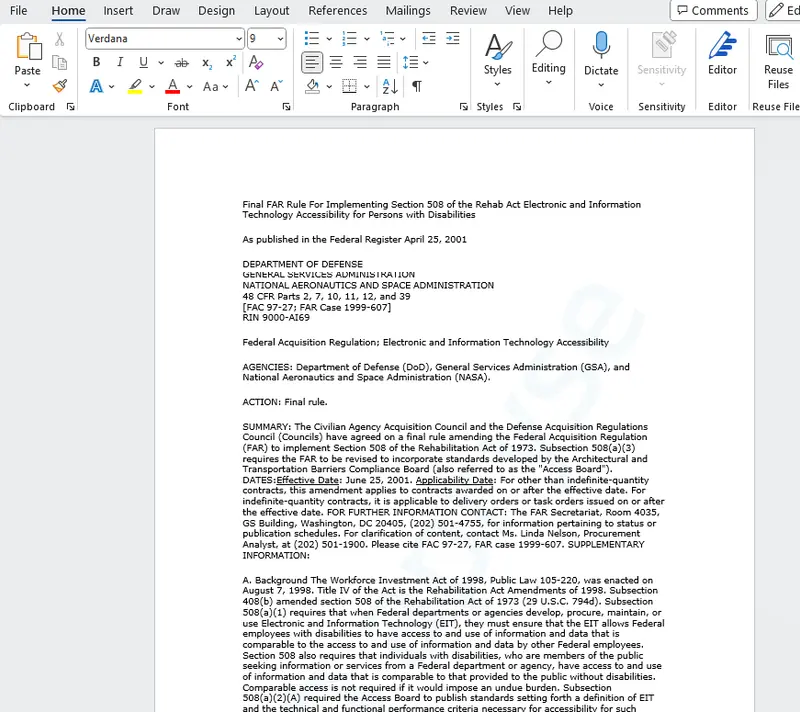
Figure 9 - A Word document reconstructed from the PDF.
Not only has the Word document been recreated, but the line, and paragraph breaks are the same in the new document as they were in the PDF.
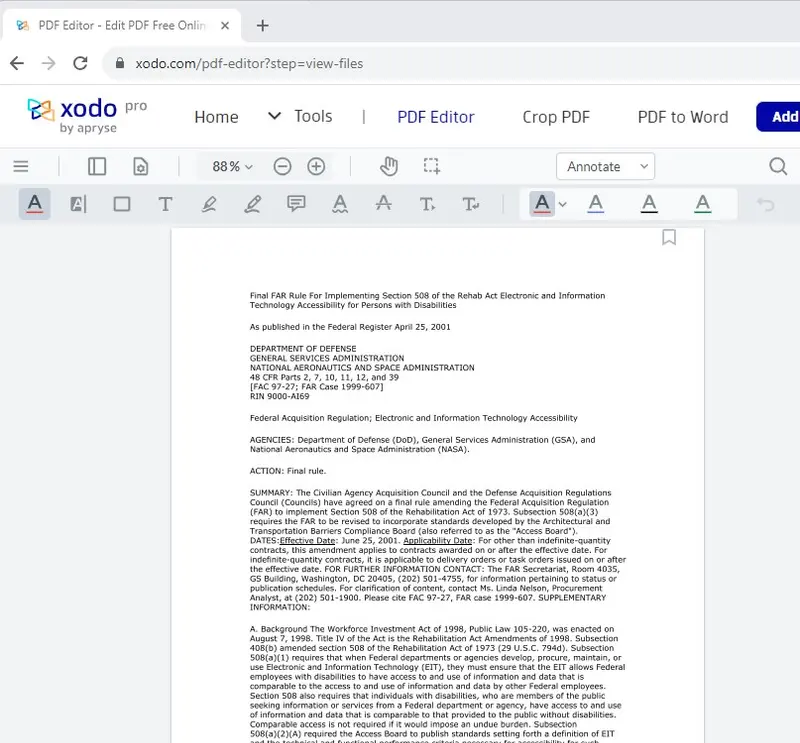
Figure 10 - The original PDF
This means that if the original author deliberately set up the document in a particular way, then the reconstructed one will look identical if it is possible to make it do so. (There are some cases where it is not possible to exactly reconstruct the layout, particularly where the document did not start as a Word document, or if the PDF was manually edited.).
So now you have an editable document that you can do whatever you want to, which looks just like the PDF. What a great result!
Is the Conversion of Scanned PDFs to Word Documents Possible?
Absolutely.
With no extra effort or coding, the Structured Output module can reconstruct a Word document from a scanned PDF using OCR (Optical Character Recognition), provided that the scan quality is good enough. This is not restricted to English language documents, and in many cases there is no need to even specify the document language since this can be automatically detected.
Better still. The technology is even clever enough to infer Word features from the scanned image.
For example, if there are rows with numbers in front of them, then these can be interpreted as a numbered list.

Figure 11 - part of a Word document reconstructed from a scanned PDF. The elements of a numbered list are shown.
This is fantastic from an editing point of view, since if a new item is added, or an existing one is deleted or moved from the list, then Word itself deals with the renumbering automatically.

Figure 12 - the same document after the removal of the original item 3.0. Note how the other list items have automatically updated.
Imagine just how much time that will save.
Converting PDFs into Excel, PowerPoint and other Types of Document
In addition to converting PDFs into Word documents, the SDK can also convert from PDF to Excel and to PowerPoint, and even supports legacy Office formats: .doc, .xls and .ppt.
To convert to these other formats, you use the appropriate “To” method, and pass in the name of the source PDF and the output file.
For example, the following code with the ToExcel method will convert a PDF into a spreadsheet.
pdftron.PDF.Convert.ToExcel("./TestFiles/Cashflow.pdf", "./TestFiles/CashflowConv.xlsx"); 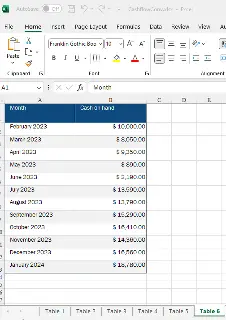
Figure 13 - An Excel Spreadsheet recovered from a PDF.
This is not the only way within Apryse to extract tabular data from PDFs. See the articles about extracting data with the Intelligent Document Processing (IDP) add-on for more information. The tools work in different ways, so it is possible that if one does not give you everything that you need then the other may.
PowerPoint presentations can also be reconstructed by using the ToPowerPoint method.
pdftron.PDF.Convert.ToPowerPoint("./TestFiles/WW1Cryptography.pdf", "./TestFiles/WW1CryptographyConv.pptx"
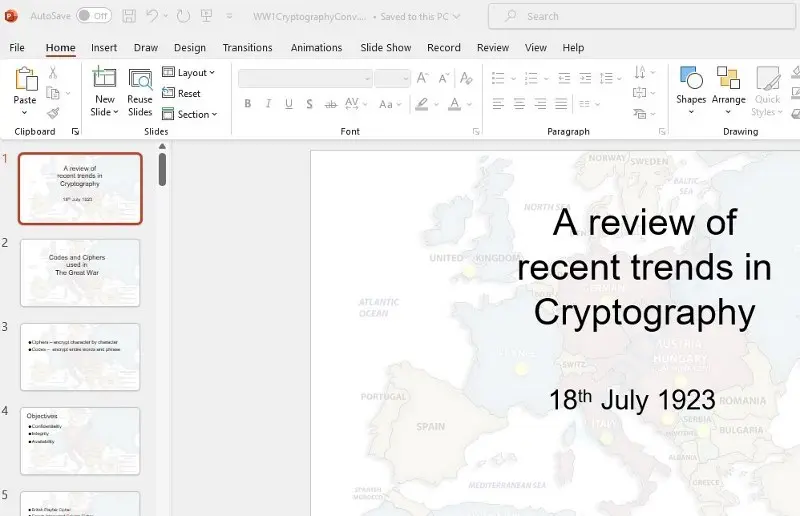
Figure 14: A PowerPoint presentation reconstructed from a PDF.
Using Conversion Options when Generating the Document
The method shown above is extremely simple. The conversion was performed using just a single line of code.
There are, however, many options available when converting a PDF to an Office document. The sample code at https://docs.apryse.com/documentation/samples/dotnetcore/cs/PDF2OfficeTest/ demonstrates how to tailor conversions, for example, just using a subset of pages from the original PDF.
Conclusion
Apryse’s C# library empowers developers to reconstruct Office documents from PDFs both efficiently and simply, leveraging the robust features of the Apryse SDK.
Whether you're building a document recovery tool, a content extraction application, or any other solution requiring the reverse conversion of documents, Apryse provides the necessary tools to accomplish the task effectively.
By harnessing the power of Apryse and the versatility of C#, you can bring flexibility and efficiency to your document processing workflows, enhancing your users' experience and productivity.
There is a wealth of documentation for in-depth insights into the capabilities of the Apryse Structured Output module and how to customize the reconstruction process according to your specific requirements.
Dive in, try things out, and don’t forget, you can reach out to us on Discord if you have any issues.