Document Generation Tools | An In Depth Guide
By Roger Dunham | 2023 Nov 02

9 min
Tags
generation
document generation
fluent
Summary
This blog delves into automated document generation methods, particularly Apryse's tools and Fluent. Developers can utilize these methods to simplify document generation for end users, enabling them to effortlessly create professional documents. The blog also spotlights Apryse SDK DocGen for report generation and introduces Fluent for crafting intricate documents. The blog concludes with insights on the methods' suitability for various use cases, shedding light on the world of automated document generation with Apryse.
Introduction
There are dozens of tools available for the automated generation of documents and reports. These range from "high-code" direct generation of documents, through simple text substitution or using templates, to complex systems such as the "low-code" Fluent (which brings together the best parts of the process from both the Windward Studios and iText DITO solutions).
Fluent is a leader in the field of high-quality automated document generation, and there are many in depth comparisons of why Fluent is superior to its competitors.
In this document, though, we will look at the various ways of generating documents, either as PDF or DOCX, using only tools from the Apryse family. We will also see how each option has its place, and its own benefits.
We will look at
- Direct Generation of PDFs
- HTML to PDF – Option 1. The Apryse SDK
- HTML to PDF – Option 2. iText Core and pdfHTML
- Why HTML is Not an Ideal Option - Same HTML – Different PDFs
- Simple Text Substitution
- Replacing text in AcroForms using iText
- Apryse SDK DocGen
- Fluent
Direct Generation of PDFs
At its simplest PDF is a document that contains content and layout information.
It is technically possible to manually create a PDF using a simple text and hex editor if you really want to, but that will get very tricky, very quickly, once you need compression, or anything beyond the trivial.
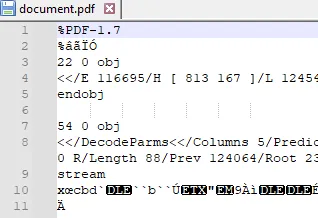
Figure 1 - Part of a PDF showing the complex inner structure.
Thankfully the Apryse SDK, which is available for many languages on Windows, macOS and Linux, offers a way to do the hard parts for you.
You can either look at the documentation here, or you can try this out for yourself using the DocumentCreationTest sample code which is one of the many samples that ship with the SDK.DocumentCreationTest takes you through the steps of creating a PDF entirely within code, and allows you to tightly specify exactly how things are laid out.
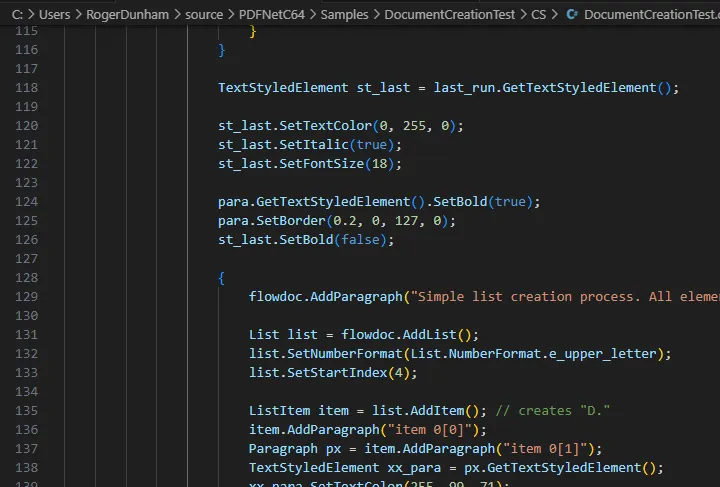
Figure 2 - A small part of the code needed to create a PDF.
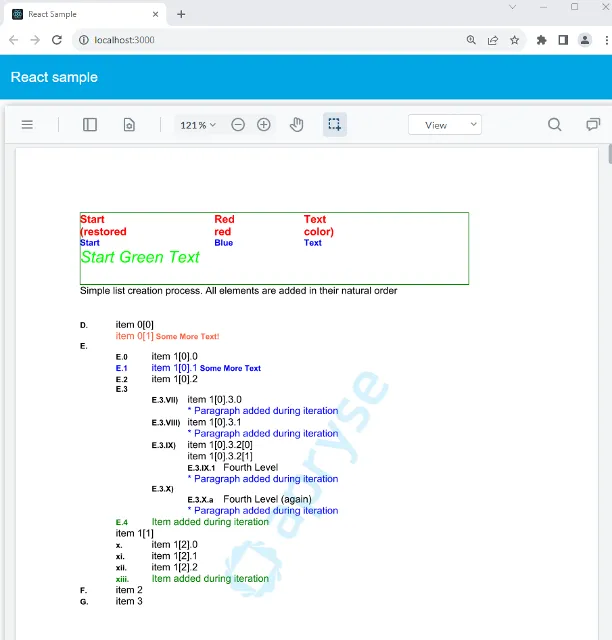
Figure 3 - The generated document.
For most users, the amount of work needed to develop, and maintain, the code for directly creating documents in this way would not be viable. If, however, you require very simple documents, and you have the skills to implement it, then this might be an option.
Converting HTML to PDF
Many software products offer the ability to create reports in HTML format, straight out of the box. These reports can look great and potentially may be responsive, allowing them to be used on mobile devices as well as on a computer monitor.
HTML is a well understood format and skilled web designers can use CSS and other techniques to create complex yet intuitive reports. Furthermore, extending existing code to add a new reporting mechanism that generates HTML is a hugely simpler prospect, supported by many libraries to speed the process, than implementing the same reports directly in PDF.
Figure 4 - A simple HTML based report.
In fact, HTML based reports are limited only by your imagination.
What is more, if your interest is primarily text, then you can even just use an XSLT transform to take XML based data and convert it into HTML.
However, while an HTML based report may be aesthetically pleasing, if the intention is that it should look the same to everyone then it is not ideal. The great strength of HTML - that it can reflow and be responsive - is also a weakness. What looks good on one device, may not look good on a device with a different screen size.
Thankfully, converting from the plasticity of HTML to the consistency of PDF is easy, and is covered by two alternatives from the Apryse stable. Furthermore, the generated document can, if required, be PDF/A compliant meaning that it will still be readable in years to come, and also PDF/UA compliant with accessibility regulations across the globe such as ADA, EAA, AODA and so on.
HTML to PDF – Option 1. The Apryse SDK
As mentioned earlier, the Apryse SDK ships with samples. One of these demonstrates the conversion of HTML into PDF. This sample requires an additional module - HTML2PDF -to be downloaded. There are versions available for Linux, macOS and Windows.
Within the sample test files is once called simple-webpage.html. We will look at how to convert that into a PDF using C#.
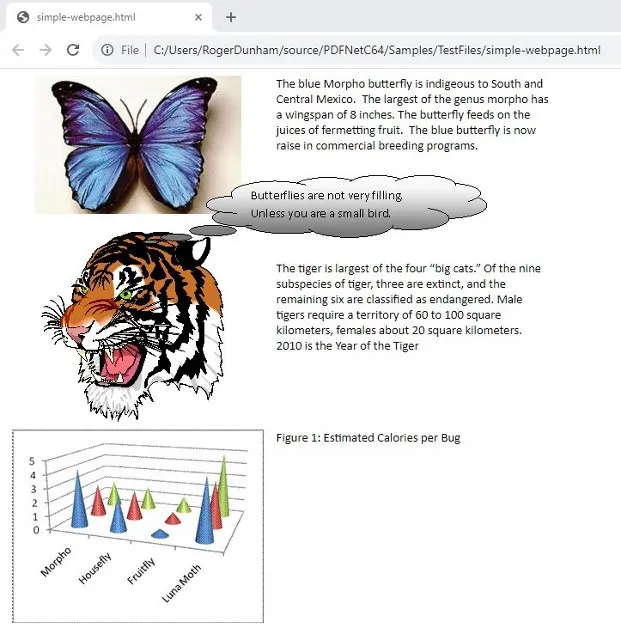
Figure 5- A simple web page containing images and text.
Once the HTML2PDF module is available, the generation of a PDF from the HTML is trivial:
using (PDFDoc doc = new PDFDoc())
{
// now convert a web page, sending generated PDF pages to doc
HTML2PDF.Convert(doc, path_to_html);
doc.Save(output_path, SDFDoc.SaveOptions.e_linearized);
} After a few seconds the PDF will be generated, which can then be shared and will look the same to everyone, irrespective of the device that they are using (provided that the user has the required fonts installed). Even if they don’t have the required fonts, the Apryse WebViewer can be used to automatically use the required fonts.
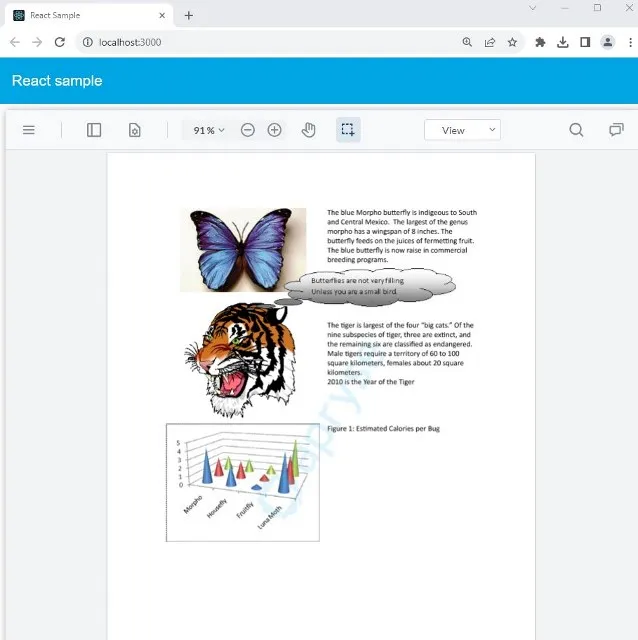
Figure 6 - A PDF created from HTML.
HTML to PDF – Option 2. iText Core and pdfHTML
An alternative to using the Apryse SDK for creating PDFs from HTML, is to use the iText library. This is exactly the mechanism that has been used for dynamic statement generation by Green Dot Bank.
The iText library is available for Java or .NET, and can be downloaded from the iText website or various locations including Maven and NuGet. You’ll also need the pdfHTML add-on module, though once downloaded the actual generation of the PDF is straightforward:
using (FileStream htmlSource = File.Open("simple-webpage.html", FileMode.Open))
using (FileStream pdfDest = File.Open("output.pdf", FileMod.Create))
{
ConverterProperties converterProperties = new ConverterProperties();
HtmlConverter.ConvertToPdf(htmlSource, pdfDest, converterProperties);
} Again, after a few seconds a PDF will have been generated.
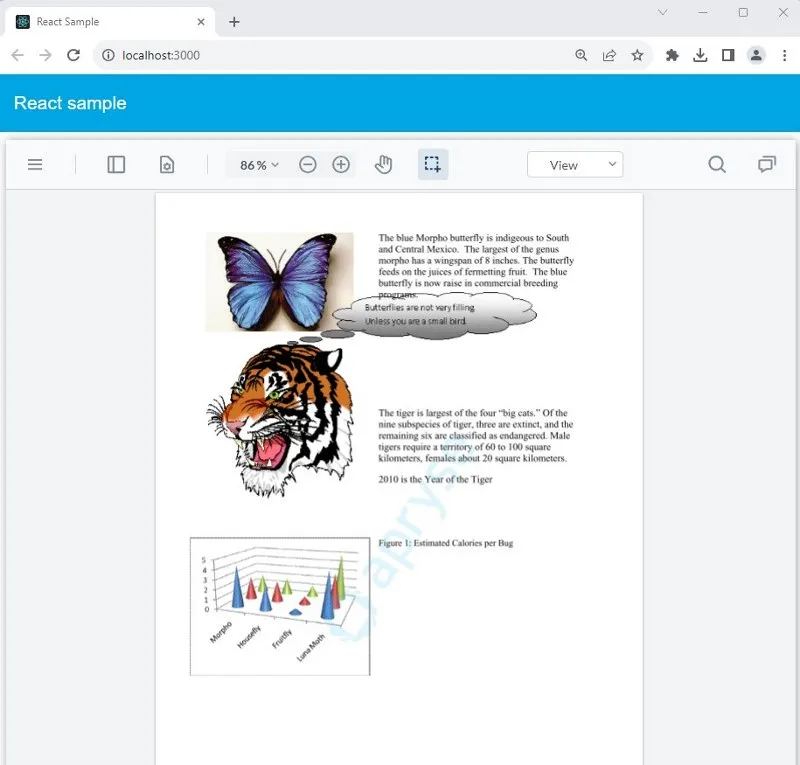
Figure 7 - The PDF created from HTML using iText.
Why HTML is Not an Ideal Option - Same HTML – Different PDFs
If you look carefully, you will see that the fonts used in the original HTML, and the two generated PDFs are subtly different. This has led to minor layout changes.

Figure 8- The original HTML and the two generated PDFs, note how the iText font has serifs.
The original HTML used the font Calibri, and the PDF generated by Apryse SDK also uses this font. However, in the PDF created by iText, this font has been substituted with Times New Roman. Thankfully, this issue can be resolved using explicit font mappings.
More concerning is that the very strength of HTML - its ability to reflow if the browser is resized or the user zooms in - means that the HTML appearance is not fixed.

Figure 9 - Part of the HTML page at 200% zoom

Figure 10 - The same part of the document at 300% zoom. Now the speech bubble overlies some other text.
This raises the question – exactly how should a PDF generated from HTML look? This is not an insurmountable problem if you have control over the entire process, but it does add an extra layer of complexity.
An alternative to the direct creation of PDFs, or using HTML as an intermediary, is to use one of the template based systems. These take a document that contains some kind of place holder then generates a document that contains the real text.
Simple Text Substitution Within a PDF
One of the samples that ships with the Apryse SDK is called Content Replacer. This takes a PDF and replaces specific text that has been marked with square brackets to create a new PDF. For the rest of this article, we use the word Tag to refer to the text that is to be replaced.
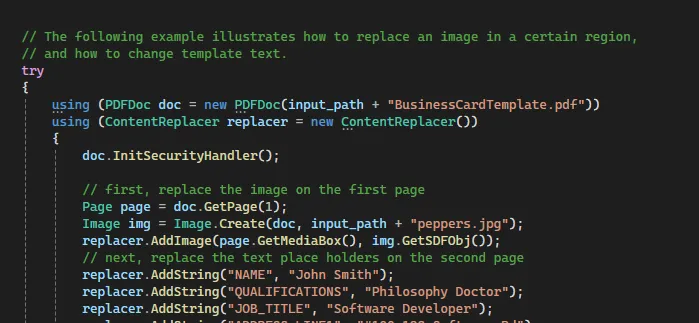
Figure 11 - Part of the code for replacing text within a PDF.
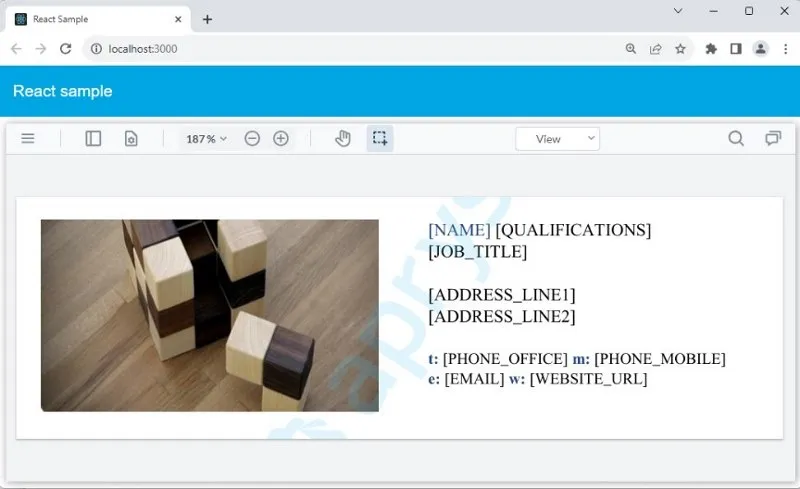
Figure 12 - The PDF template before substitution.
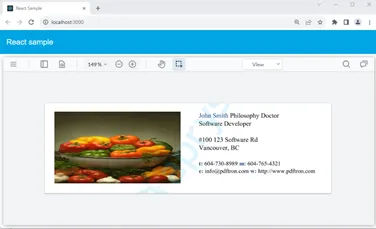
Figure 13- The same PDF after substitution.
Why would you want to use this functionality?
Many companies have bespoke legacy software that creates reports and documents for a specific purpose, often in a very rigid format. This software has often been working perfectly well for many years, but the vendor no longer supports it.
When a minor change is needed in the generated document, perhaps the company address has changed, then this can represent a major headache. Updating the software directly to change the address is often prohibitive in terms of cost, time or risk.
An alternative is to keep the software as it is, but to modify the address in the document after it is generated. As such the legacy software continues to be used to create a report that is then post-processed to include the new information. For example, the old address can be detected and replaced with the new address.
Content substitution allows either the content at a specific location, or which contains specific text – effectively a tag - to be replaced.
There are however significant issues with this approach. If the new text is larger than was previously the case, then it may not fit within the space available in the PDF, resulting in a poorly laid out document with text that potentially overlaps or extends beyond the document boundary.
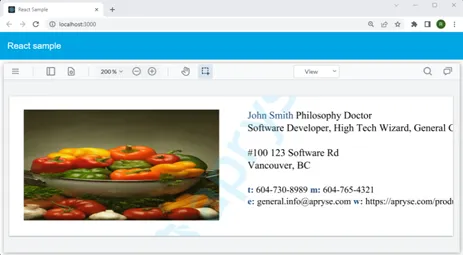
Figure 14 - A generated PDF with text that no longer fits within its bounds.
Furthermore, this mechanism cannot be used to add new list items, or reflow text from one page onto the next.
Replacing Text in AcroForms Using iText
A popular method of creating PDF documents using iText Core is by using AcroForms. These are PDFs containing text fields into which data can be entered, combo boxes or list fields, check boxes, signature fields etc.
You can create a template directly using iText’s high-level API methods, or you might prefer to design an attractive template using Acrobat or similar tools first. Whichever route you choose though, filling out the form fields and then flattening them (so data in fields cannot be modified later) is easily done with iText Core.
This method of document generation is highly performant, and ideal for generating documents like boarding passes, vouchers, and entry tickets where rather than regenerating the document from scratch every time, you simply take your template and fill it out with the appropriate data. You can find Java and C# examples for doing this in Chapter 4 of the iText Jump-Start Tutorial.
One especially nice change in iText Core version 8 is that rather than you having to specify the exact position of form elements, you can instead add or remove elements and rely on iText’s layout mechanism to place them in a logical manner. To demonstrate this we have a code example showing how to create a text form field and add layout properties to it.
Automate document generation with Apryse WebViewer. Convert JSON data into reports effortlessly, saving time and ensuring accuracy.
Apryse SDK DocGen
Apryse DocGen is a high-code solution that can run either directly within WebViewer, or server-side. It is ideally suited for generating reports, invoices, letters, and contracts based on DOCX, XLSX or PPTX templates with JSON data.
With an Office document based format, coupled with Apryse’s superb ability to directly handle Office documents without the need for external dependencies, DocGen helps to solve the issue of text not fitting within the space that the tag occupied.
During the process of tag-substitution the document will reflow as necessary, with the final output being either a PDF or Office document.
You can see this process at the Apryse Showcase
In DocGen the templatescan be created using any editor that understands the Office document format, and the textto be replaced, Tags, are marked using pairs of mustache brackets. For example:
{{COMPANY_NAME}}
Styling of the template is mostly done within the template, but some styling can be added using html or markdown within the data.
Furthermore, DocGen supports both tables and conditional content.
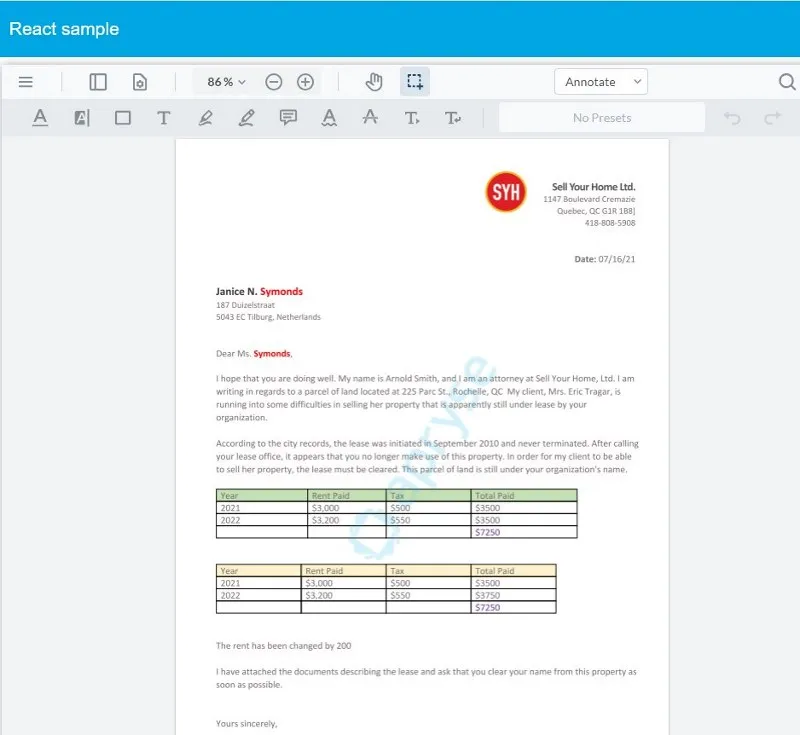
Figure 15 - A sample document created by DocGen. The tables, logo, much of the text, and some of the formatting have been applied from the data.
DocGen requires that the data that will be substituted into the document needs to be JSON. How that JSON is generated is entirely down to you – potentially if could come from a database, or RESTful API, or user input, and then converted into JSON.
DocGen is a great system, but wrangling data is, by its very nature, complex. Being high-code, any changes in the data source are likely to require a Software Developer.
Fluent
Fluent is a unique solution that is well suited for generating high-volume, complex, documents with graphs, charts, and built-in data calculations. Furthermore, it can easily connect to multiple data sources, allowing you to merge data from JSON, XML, SQL databases, including JSON, XML, SQL Server, MySQL, PostgreSQL, Oracle, MS Dynamics, OData, Salesforce, SharePoint, DB2. This means that you can create stories with your data using charts, graphs, and a variety of advanced formatting capabilities.
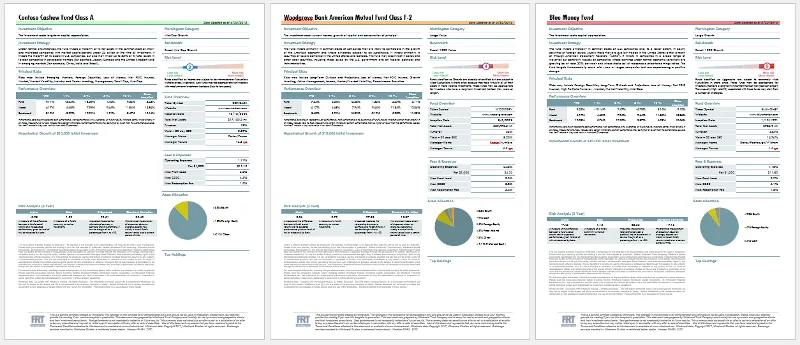
Figure 16 - An example 3 page document created by Fluent, using a single template and the latest data from the data source.
Templates are generated with an intuitive plugin for Word, Excel or PowerPoint. However, for the actual generation of documents, Office is not required. The documents generated can be PDF, DOCX, XLSX, PPTX, HTML, PDF/A-3b, RTF, Direct to Printer and Images.
The Fluent system consists of three parts –
- Fluent Designer
- Fluent Engine
- Fluent Manager
We will look at each in turn.
The Fluent Designer is immensely powerful and supports Fluent Designer templating mechanism is immensely powerful and supports loops, tables, charts, graphs, table of contents, page orientations, and conditional text.
Furthermore, it allows you to define complex conditional formatting of data. For example, negative numbers can be shown in a different way from positive numbers, or thousand separators can be specified even though the data itself does not contain such separators. This means that the format of data in the document can be controlled independently of what is held in the data source.
The actual process of tag substitution is performed within the Fluent Engine, which is available either as a standalone application for .NET or Java, or as a RESTful API that can either be hosted on-premises or within the cloud, and is available within a Docker container to simplify deployment.
Development of templates requires some knowledge, but with great documentation and online support, it can be achieved by anyone that is good with Office. The actual use of Fluent doesn’t require a software developer to make any changes to the code. In fact, there is no need to know anything about the ‘code’, since the Fluent Manager is easy to install and configure.
The Fluent Manager is the final part of the Fluent system, and acts as a central repository for your templates and data sources, as well as providing a system of roles and permissions to limit access to different aspects of functionality. As such, administrators can control which users have access to specific features and data within the application.
Furthermore, as templates tend to evolve over time, the Fluent Manager offers support for rolling back, or forward, to specific versions.
Combined together the Fluent system offers an excellent mechanism for the timely generation of complex up-to-date documents.
Summary
Method | High Code/Low Code | Tables Supported if Row Count Unknown Beforehand | Output Type | Example Use Case |
|---|---|---|---|---|
Direct Generation of PDFs | Extremely High code | Potentially, but a lot of work | Extremely niche – adding a report to a process that you have complete control over, such as an industrial process that needs to report items created. | |
HTML to PDF | High code for HTML generation. Low code for HTML to PDF | Potentially | Bank statements, boarding cards. | |
Content Replacement in PDFs | High Code | No | Well suited to minor changes to an existing PDF report. Issues exist with fitting large amounts of text into a limited space. | |
Populate AcroForm Templates with Text | High Code | No | Ideal if the report does not require tables and is not likely to change very often. | |
Apryse SDK DocGen | High Code | Yes | PDF/DOCX/PPTX/XLSX | Suitable for any situation where data can be collected as JSON, and formatting/conditional text requirements are limited. |
Fluent | Low Code | Yes | PDF/DOCX/PPTX/XLSX/CSV/HTML/Direct to Printer | Ideal for complex, professional documents that need to be created in large numbers. |
Where Next?
In this article we have looked at eight different ways of generating documents from data using Apryse. Each option has its advantages and disadvantages, but all have situations where they are the most effective solution.
When you are ready to begin, see the documentation for the SDK to get started quickly. Don’t forget, you can also reach out to us on Discord if you have any issues.
Tags
generation
document generation
fluent

Roger Dunham
Share this post