Roger Dunham
Published November 23, 2023
Updated May 18, 2026
8 min
Generating Documents and Reports from DOCX Templates and JSON using Apryse and Java
Roger Dunham

Summary
In this article though, we will look at the “high-code” option, SDK DocGen, which is based directly on the Apryse SDK. It can be used entirely within the browser; however, we will look at how it can be used within a Java application running on a local machine.
Introduction
This article provides everything that you need know to get started with Automated Documentation using Java and the Apryse SDK.
There are however other options, such as table generation and conditional text, that are not covered in this article. For further information about those, see the “Deep dive” version of this guide written for Python.
Apryse has two distinct systems for creating documents and reports from templates. In both cases the templates are Office documents, but in neither case is there a need for Office to be installed to generate the final document from the template.
The first mechanism is a “low-code” solution – “Fluent”, and there have been several recent articles on using this versatile and powerful system. It can be used to create not just PDFs, but also other document formats, for example DOCX or PPTX or HTML. Furthermore, the template designer means that this system is suitable for anyone with moderate knowledge of Word allowing you to eliminate lengthy development work for your templates.
A significant difference between DocGen and Fluent, is that DocGen can only use data that is in JSON format, whereas Fluent can access data from a huge range of data sources, including JSON, XML, SQLServer and OData.
In this article, we will
- See why it is better to use Office documents than PDFs as templates
- Download sample code and see an example in action
- Set up data that will used to populate the document
- See how easy it is to generate the document within Java
Why It Is Better to Use Office Documents than PDFs as Templates
A quick search of the internet reveals that some document generation systems use a PDF as a template, then substitute content within the PDF. There is nothing wrong with generating documents in that way if it does everything that you need. However, when used with real data it is likely that you will soon find limitations.
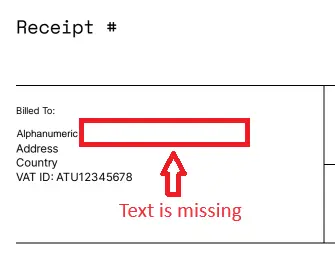
Figure 1 - A PDF created by substitution of text from a PDF template. There was not enough space, so some text is missing.
You can read more about why using a PDF as a template is problematic here.
Using DOCX files as a template offers a more versatile format. The Apryse SDK provides a mechanism for viewing and editing Word documents without the need for Office to be installed. In fact, it is the library that provides the functionality to Xodo Docx Editor.
With its ability to reflow text in just the same way that Word does, as well as its support for complex text and paragraph formatting, the Apryse SDK is an ideal tool for substituting text-markers (which are known at tags) in a template, in order to automatically generate high-quality, accurate documents that contain up-to-date data.
Seeing Document Generation in Action
Before we go any further, let’s look at a live example of document generation from a DOCX template. You can choose any template, and the program will query it for tags, and use them to generate a data-entry form, which in turn is used to populate the template.
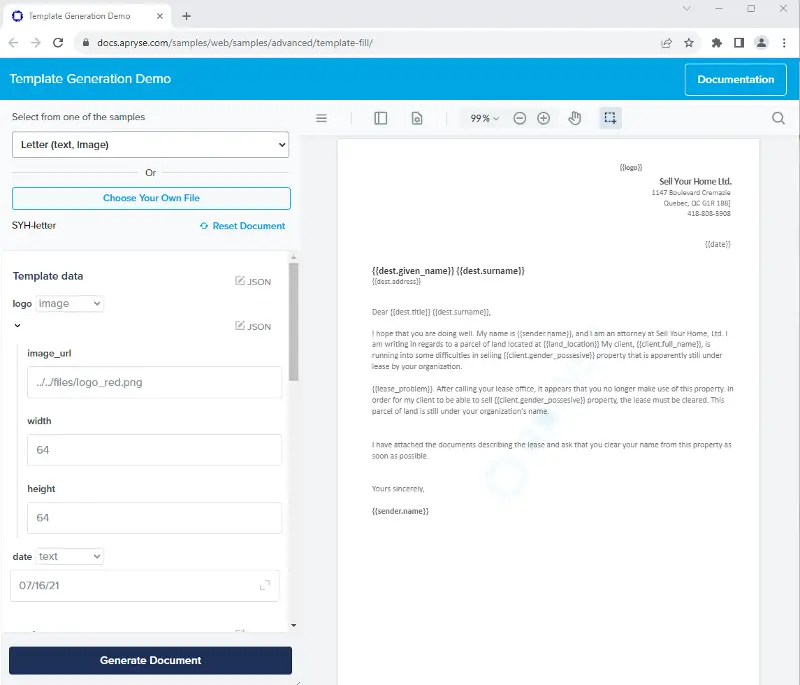
Figure 2 - The online sample showing a dynamically generated data entry area.
So, let’s see how we would do this in practice.
Overview of the Document Generation Process – From DOCX to PDF
- Create a template in DOCX format. This can be done using markers (the ‘tags’ that were mentioned earlier) to indicate where text should be located. In addition to single word replacement, table creation is supported, as is the ability to have text shown, or not shown, depending on the actual data. The method for creating templates is well documented, and can be performed by anyone that is moderately skilled at Office.
- Generate a JSON object that contains the data that should be copied into the final document. The origin of that data is up to you - whether it is collected from a file, user input (which is the case in the example just mentioned), a database or even a RESTful API.
- Use the Apryse SDK to replace the tags in the template with the data in order to create the final document.
In this article, we will look at sample code written in Java which is included when you download the SDK.
Seeing the Java Sample in Action
The Apryse SDK is available in many different languages and for macOS, Linux and Windows. In this article we will look primarily at the Windows version. The other platforms have minor differences – if you have problems then please reach out to us on Discord.
Before using the samples, please see the prerequisites, and if you haven’t used Java before, there is helpful information in the FAQ.
Once your Java environment is set up, head over to https://dev.apryse.com/windows, scroll down a little and click on the button to download the Java 64-bit version.
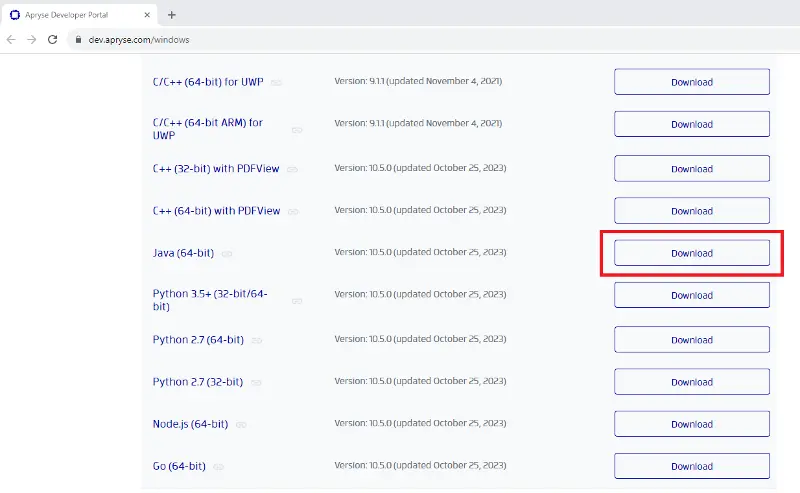
Figure 3 - How to get the Java 64-bit version of the Apryse SDK.
The downloaded SDK is a zip file. In any event extract the archive which, on Windows, will create a folder called PDFNetJava.
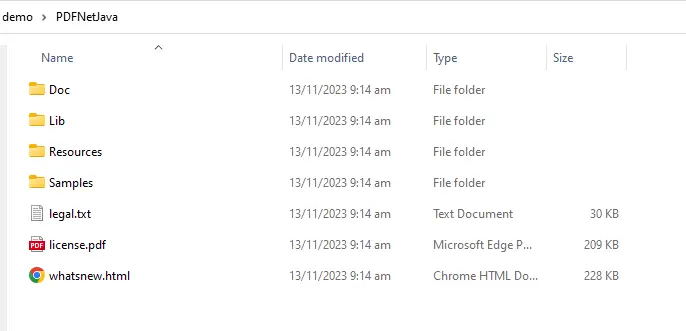
Figure 4 - The contents of the downloaded archive on Windows.
This folder contains not just the SDK itself, but documentation and a folder full of samples that demonstrate the huge range of functionality supported by Apryse. For now, we will look at the OfficeTemplateTest sample.
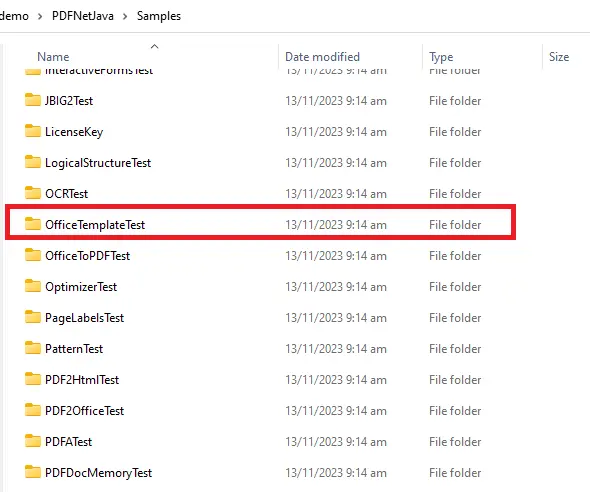
Figure 5 - Just a few of the samples that are included with the SDK. In this article we are looking at OfficeTemplateTest.
Before running any of the samples, you will need an Apryse Trial key which you can get here. This then needs to be pasted into the file PDFTronLicense.java. If you forget to do so, then an error will occur, and you will see a message to remind you of what to do.

Figure 6 - The error message that you will see if you forget to enter your license key.
There are several options for running samples. The first method is to run each sample project sequentially directly from the console window using the batch file runall_java.bat (or runall_java.sh on Linux or macOS) located in the root of the Samples folder.
Alternatively, you can navigate to the JAVA folder of the OfficeTemplateTest sample and either run the RunTest.bat (or .sh) file for that specific sample, or else open the folder for the sample in VSCode and run the code from within VSCode.
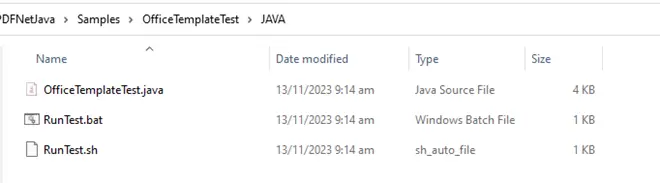
Figure 7 - The contents of the OfficeTempateTest folder showing the batch, shell and Java files.
You can now open a terminal window from VSCode and call RunTest.bat (or ./RunTest.bat in PowerShell). This will show some information and, after a few seconds, the document SYH_Letter.pdf will be saved.
Figure 8 - The console window indicating that the sample has completed successfully.
Let’s open that document.
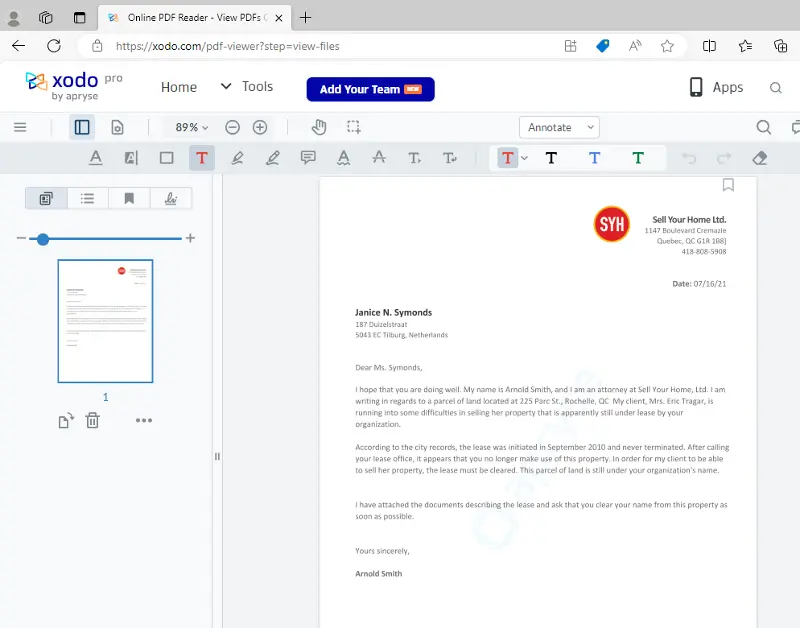
Figure 9 - The newly generated document, shown here in the online PDF viewer xodo.com.
That’s pretty cool – with very little effort we created a new document. What isn’t obvious is that we could create another one, and another one, and another, whenever the data changes. As such, the document will always be using the latest data. Let’s look at how we did that.
In the folder PDFNetJava\Samples\TestFiles you will find a file called SYH_Letter.docx.
Figure 10 - The contents of the TestFiles folder that ships with the SDK.
This is the template that was used to create the PDF. If you open it in Word (or any other editor that supports DOCX) then you can see that it is just an ordinary DOCX file.
What makes it special is the tags – the pieces of text, such as {{dest_surname}} - which indicate where content should be replaced when generating the final document.
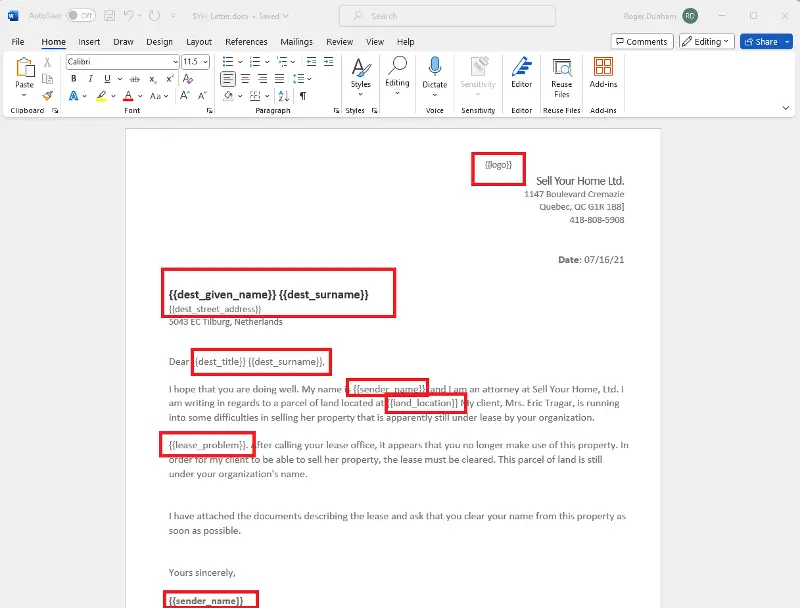
Figure 11 - Part of the report template DOCX file, showing the tags.
A tag, for example {{sender_name}}, typically starts, and end, with double curly braces (sometimes known as “mustache” braces). The tag markers are customizable, so you can use something else if you prefer.
Although this template does not include one, it is possible to include a table in the document. The generated table would automatically expand to contain whatever number of rows are specified in the data, so there is no need to know the number of rows at the time of template creation.
Since DocGen is supported across a range of platforms and languages, the skills that you develop working in one language are generally transferrable to another. As such you can read more about setting up a multi-row table in the article about document generation using React and use the information included there with Java.
It is also possible to specify conditional text, for example, to show one block of text if the data contains some feature (for example a field for “overdue”) and a different block of text, or nothing at all, if the data doesn’t contain that feature. You can find information here about how to do set up conditional text, but an example is shown below.

Figure 12 - An example of conditional text. The statement about rent arrears will only be shown if the expression 'overdue' is true.
OK, we will leave the template there, and next look at the data.
THE JSON Data Structure
The text substitution API needs to be supplied with a JSON dictionary, where each template tag within the template matches a key within the dictionary. The content of the JSON values can be text, images, structured input (html and markdown) or objects.
Please see here for a detailed description of the JSON file requirements.
While SDK DocGen does require the data to be in JSON format, the way that the JSON is generated is up to you. It could be hard-coded, acquired from user input, a local file, a database or even from a web call.
For our simple template though, the sample project uses the following hard-coded data:
Most of the layout is self-explanatory, but the handling of the logo image requires a mention:
Handling Images in the Document
The logo is specified as an image_url, including its path, width, and height. When the document is generated, the image will be loaded into the final document.

Figure 13 - Part of the final report - showing how the logo tag has been replaced.

Controlling Style from the Data – Structured Input
While most of the data is just text, which will ultimately be displayed using the formatting form the template, it is also possible to include styling information in the data - either as html or markdown.
Date: {html:"<span style='color: red'><b>Oct 5th, 2023</b></span>"}, In this example, the formatting of the date tag will be red and bold, rather than just text.

Figure 14 - Part of a different example template showing two tags - for Date and Expiry Date. In the final document the styling of the {{Date}} has been changed since it is specified within the data.
This is a powerful mechanism, andcan be used to add paragraphs, headings, and styling.
Generating the Final Document
Everything that we have seen so far – template generation and JSON format - is platform-independent. In fact, the results will be the same whether the actual conversion occurs within the browser, in the cloud or on a local machine.
With document generation supported on UWP, Android, Linux, macOS and Windows, as well as the Web, there are many opportunities for you to use this technology. The actual process of document generation does, however, have minor, platform specific, variations – so reach out to us if you need a hand getting started.
In the case of generating documents using Java, the actual document generation requires nothing more than calling fillTemplateJson with the JSON data.
fillTemplateJson causes the Apryse SDK-DocGen system to produce a PDF by substituting each of the tags in the template with data from the JSON object, including iterating through tables. This is done entirely within the Apryse code – there is no need for Word to be installed, since it isn’t Word that is performing the substitution.
It really is that simple. One line of code takes the template, merges it with the JSON data, and creates a document. All that is still needed, is to save the resulting PDF.
Beyond DOCX – Support for Other Template Types
The SDK DocGen mechanism creates a PDF (although this can be saved as a PNG, and the ability to save as Office documents is in development), and it is extremely good at doing that.
While the most commonly used template format is DOCX, the system also works with PowerPoint and Excel templates, including the old style DOC, XLS and PPT file types.
In each case, the tags that are to be substituted are marked in exactly the same way.
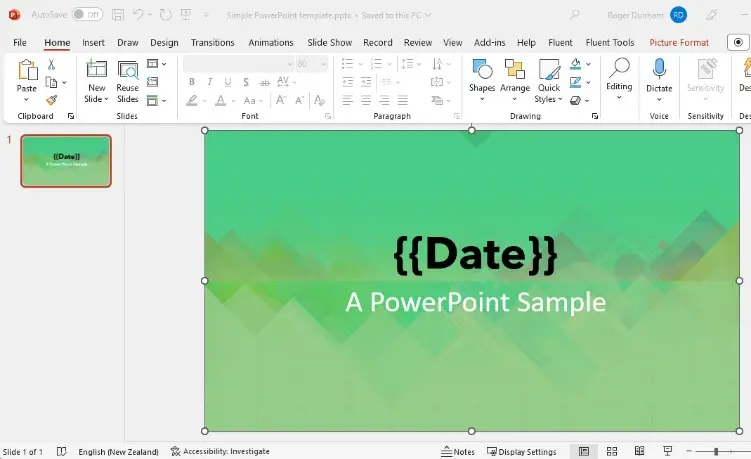
Figure 15- A PowerPoint template, and the resulting PDF.
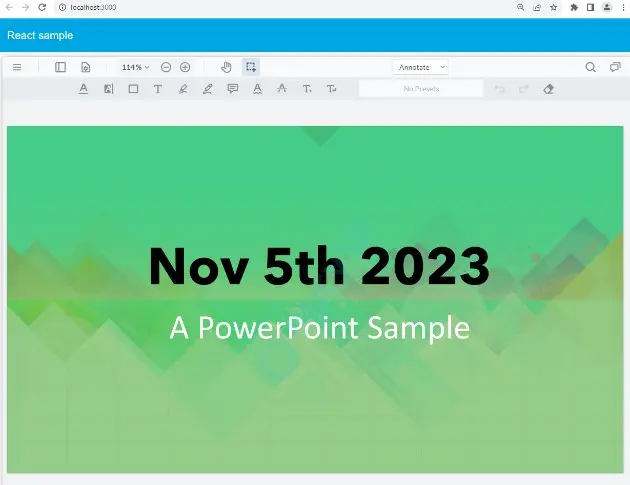
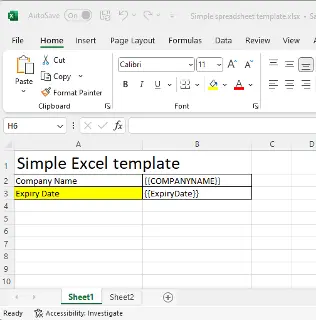
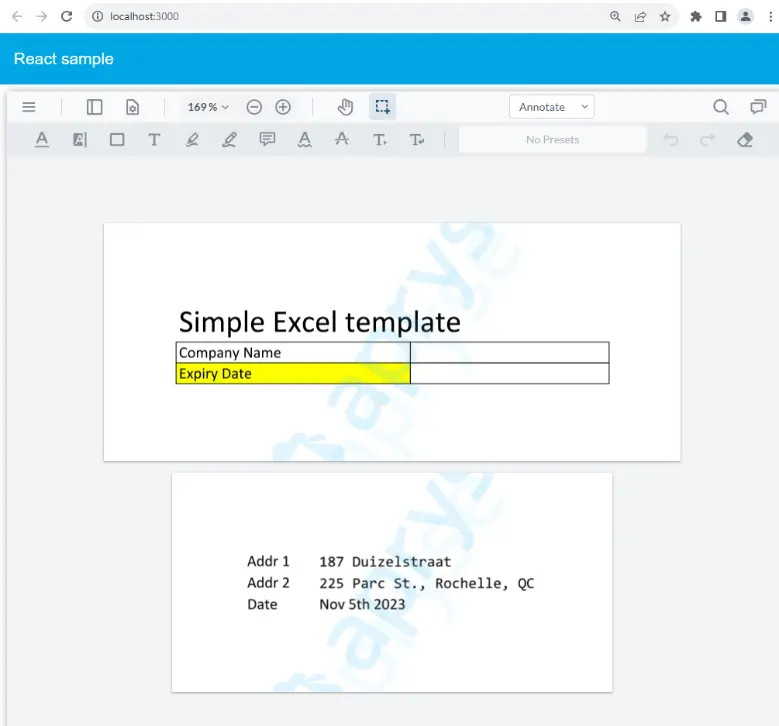
Figure 16 - A multi-sheet Excel template and the resulting PDF.
When Should Apryse SDK-DocGen be Used?
This system is great where the data source is JSON (or can easily be converted into JSON), the required document format is PDF (although as mentioned above, the ability to save as Office is in development), and the document structure is relatively straightforward. This mechanism is also a great solution for use with Appian or Salesforce – with no external libraries being required.
One of the disadvantages of this system, though, is that it is “high-code”. A change in the data source will probably require help from a developer. For example, the data source for a RESTful API might change, or the structure of data coming from a reporting system might need to be updated. In the case of Structured Input (formatting via html and markdown), a change to the formatting would likely need developer help. As such, if your data source (or Structured Input based formatting) is likely to change then Apryse Fluent may be a better fit.
Similarly, in any situation where your use-case isn’t supported (such as requiring complex conditional formatting or charts)then Apryse Fluent will be able to take you much further.
Conclusion
We have seen how we can create templates in a familiar environment, that can support text of initially unknown length by behaving like Word documents – adding new lines or overflowing onto the next page as dictated by the data. We have also seen how we can add logic to the template so that whether or not some parts of the document are only shown depends on some data condition.
We have also seen how this can all be done without the need for Office to be installed on the machine where document generation is occurring. Furthermore, if you want to extend the document generation in some way – perhaps developing a web app, where conversion occurs entirely within the browser, then the information that is included in this article is a great basis for taking those next steps.
When you are ready to get started, see the documentation for the SDK to help you to get up to speed quickly. Don’t forget, you can also reach out to us on Discord if you have any issues.