Isaac Maw
Technical Content Creator
Published April 01, 2026
Updated May 18, 2026
7 min
PDF to JSON: How to Extract Structured Data from Unstructured PDFs with AI
Isaac Maw
Technical Content Creator
Summary: This article explains how Apryse Smart Data Extraction converts unstructured PDFs into accurate structured JSON that developers can use in automation and AI workflows. It outlines the advantages of AI based extraction compared to OCR and template driven methods and highlights how Apryse improves data quality and security by running fully on premise.
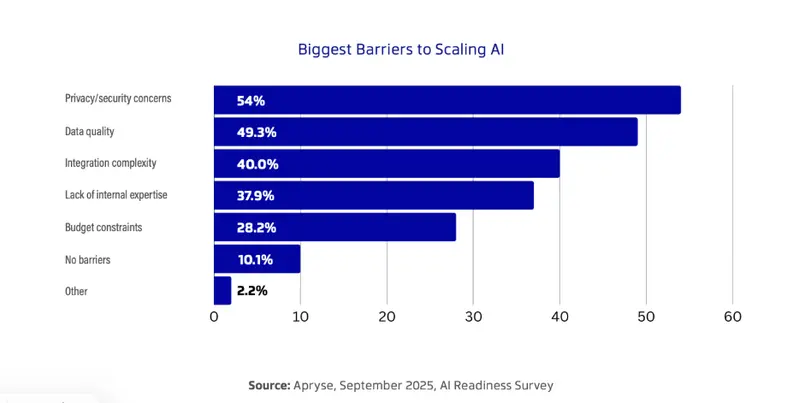
According to our 2025 AI Readiness Report, two of the largest barriers to scaling AI in enterprise operations are privacy/security concerns and data quality. With AI-powered tools such as retrieval-augmented generation (RAG) providing value for enterprises, solving these challenges is a key target for developers when it comes to document processing.
80% of enterprise data is unstructured, trapped in PDF documents, office files, emails, and even paper documents. The bottleneck is getting data out of PDFs into usable JSON, not the AI model itself.
Apryse Smart Data Extraction effectively addresses data quality and privacy/security concerns:
- Data Quality: Smart Data Extraction produces higher quality results than OCR, with Document Classification, Key-value pair detection, and document structure recognition.
- Privacy/Security: The Apryse Server SDK and Smart Data Extraction keep data in your environment, with no external dependencies or API services.
Let’s overview types of data extraction, important considerations for developers, and what makes Apryse Smart Data Extraction stand out.
The Three Types of PDF Data Extraction
PDF documents are designed to be readable by human users, not machines. Under the hood, content does not appear as simple text. This is why selecting text in PDFs isn’t always possible or reliable. The three types include:
- Rule-based: relies on fixed coordinates on the page, such as the known location of a form field. Because all the coordinates are hard-coded, this method breaks if the layout changes, such as a new version of a form or a misaligned scan.
- Template-based: matches documents with a predefined template defining structured form fields. Not useful for unstructured documents.
- AI/ML-based: uses AI and machine learning to categorize document types and recognize document structure such as headings and tables. Extracts data accurately from unstructured documents.
This article focuses on AI-based extraction.
What Does "PDF to JSON" Actually Mean for Developers?
A document is more than just a string of text. Headings, paragraphs, tables, and other document structure communicate information beyond the text itself, and some text content is less valuable than others, such as letterhead and boilerplate, for example.
With basic OCR on a PDF document, all the content in a PDF is converted to text, but all the formatting is lost. This means additional processing is required to extract data such as dates and names, for example.
AI-powered Smart Data Extraction goes beyond OCR with tools to identify data based on its context within the document. Click the links to visit our Showcase and demo these extraction tools for yourself:
- Key-Value pairs extraction | Automatically extracts linked key‑value data from PDFs.
- Form Field Detection | Automatically detects and classifies form fields in PDFs.
- Document Structure Recognition | Identifies structural elements within PDFs for downstream processing.
- CAD Title Block Extraction | Extracts structured information from CAD file title blocks.
- Document Classification | Categorizes documents based on extracted content and structure.
- Confidence Scores: within the output JSON for document classification, the SDK also provides a confidence score, as shown:
“documentClasses” : [
{
“type” : “resume”,
“confidence” : 0.927
}
]
Cloud vs. On-Premise: Where Should Your Documents Go?
Coming back to privacy and security concerns as an obstacle to AI in enterprise production, developers can choose between cloud-based and on-premise solutions for data processing.
In addition, within cloud-based processing, data extraction can take place within your own application’s cloud environment, or use a third-party API service such as AWS Textract or Google Document AI.
These cloud-based APIs come with privacy and security tradeoffs. While these cloud service providers such as Google, AWS and Azure do maintain their own security and privacy compliance certifications, transmitting data to a third party may still cause headaches for industry-specific compliance, such as For healthcare (HIPAA), finance (PCI-DSS), government (air-gapped).
By comparison, on-premise SDKs keep data in-house, ensuring data privacy, security and ownership.
Comparing PDF to JSON Extraction Tools
Solution | Deployment Model | Strengths | Limitations | Ideal Use Cases |
|---|---|---|---|---|
AWS Textract | Cloud‑only (AWS) |
|
| Automated parsing of PDFs at scale, table-heavy docs, serverless workflows, already invested in AWS infrastructure |
Google Document AI | Cloud-only (GCP) |
|
| Invoice/receipt automation, form parsing pipelines, GCP-native workflows |
Adobe PDF Extract API | Cloud API |
|
| Publishers, content repurposing, precise JSON layout extraction |
Apryse Smart Data Extraction | Fully on‑premise, air‑gapped capable (also cloud) |
|
| Enterprise on‑prem IDP, regulated environments, embedded PDF workflows, full document pipelines |
ABBYY FlexiCapture | Cloud or on‑prem |
|
| Enterprise automation, high‑volume capture, workflow‑driven IDP |
PDFix | SDK (on‑prem or packaged) |
| Primarily an accessibility and compliance tool, not general data extraction Smaller ecosystem with fewer pre-built extraction models | Development teams requiring PDF accessibility and compliance at scale (PDF/UA / WCAG) |
Mindee | Cloud API | Strong invoice/receipt extraction Developer‑friendly REST API Simple pricing structure | Cloud‑only Limited outside receipts/forms unless using custom models | Finance automation, SMB invoicing tools, lightweight cloud apps |
Tutorial: Extract Structured JSON from a PDF with Apryse SDK
It’s easy to get started with Smart Data Extraction with the Apryse Server SDK. You can get your trial key and start working with the SDK in your application today. Here’s how:
- Get started with Server SDK in your language/framework (find trial key details inside)
- Download the Data Extraction Module
- Add the sample code provided below:
Feeding PDF-Extracted Data into LLM/RAG Pipelines
Enterprises use retrieval-augmented generation (RAG) to boost LLM output with their own data from an internal database. This is valuable tool for legal teams, for example, who can input massive quantities of discovery documents and use an LLM or AI agent to quickly process the data and get specific, relevant answers.
PDF extraction serves as a critical data prep layer for RAG systems. Apryse converts unstructured PDFs into clean labeled JSON that LLMs can consume.
To learn more about Apryse Smart Data Extraction solutions for LLM and RAG systems, check out the WebViewer Guide: Building a Great User Experience for Production LLM Applications.
To get started or with any questions, please contact sales.
FAQ
Q: How do I convert a PDF to structured JSON using AI?
A: Apryse Smart Data Extraction uses AI to identify document structure, tables, and key value pairs and outputs clean JSON that stays fully inside your environment.
Q: Is there an on-premise PDF to JSON solution for strict compliance needs?
A: Yes. Apryse provides a fully on premise and air-gapped capable extraction engine that keeps all document processing and JSON generation in house for maximum security.
Q: What is the best way to prepare PDF data for LLM or RAG pipelines?
A: Apryse converts unstructured PDFs into structured JSON with layout, hierarchy, and confidence scores, producing high quality inputs that improve retrieval accuracy in AI workflows.