Home
All Blogs
Intelligent Document Processing vs Traditional OCR: What Solution Is Right for Your Use Case
Apryse
Published June 24, 2026
Updated June 25, 2026
5 min
Intelligent Document Processing vs Traditional OCR: What Solution Is Right for Your Use Case
Apryse
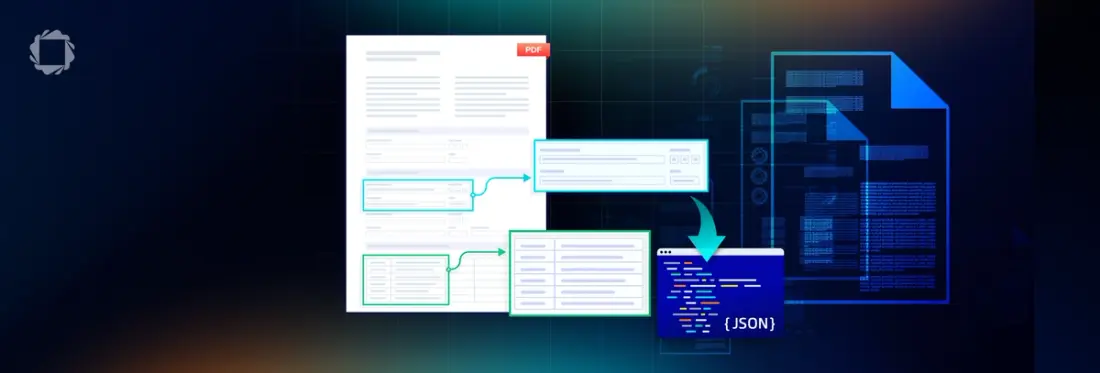
Most business information is locked away in unstructured documents like PDFs, scans, and Office files. For enterprises and software teams turning that content into usable data is a recurring challenge. The first step is often to digitize this content, but the method you choose can mean the difference between generating high-quality intelligence and creating a “garbage in, garbage out” data pipeline. This guide explains the critical leap from basic Optical Character Recognition (OCR) to full-fledged Intelligent Document Processing (IDP) and clarifies which approach is right for which use case—whether you are powering AI applications, automating back-office processes, or modernizing a document-heavy product.
What is Traditional OCR? The Foundational First Step
Optical Character Recognition (OCR) is a foundational technology that converts images of typed or printed text into a machine-readable string of text characters. Think of it as a digital transcriber that reads the words on a scanned page and outputs a simple text file. This technology was a breakthrough for digitizing archives and enabling basic search on previously unsearchable documents.
For many years, OCR was the primary tool for document digitization. It is effective for:
- Basic digitization of paper archives.
- Enabling full-text search on scanned documents and images.
However, for the nuanced demands of modern AI, traditional OCR has severe limitations. Its output is essentially a “wall of text,” a flat file of characters with no deeper understanding of the document’s meaning or structure. The risks of relying solely on OCR for an AI workflow are significant.
- Output is unstructured: OCR produces raw text without recognizing critical layout elements like tables, columns, key-value pairs, or form fields.
- Context is lost: It cannot differentiate between an invoice number and a date, or a header and a footer. The semantic relationships between data points are completely lost, making the data unreliable for automated decision-making.
- Fragile and template-dependent: Many traditional OCR systems rely on rigid templates. They break as soon as a document’s layout changes, forcing developers into a costly cycle of re-engineering and maintenance.
For an AI model, the raw, context-free text from traditional OCR is little more than noise. It lacks the structure and meaning required for high-level analysis, leading to inaccurate results and failed automation.
What is Intelligent Document Processing (IDP)? The AI-Powered Evolution
Intelligent Document Processing (IDP) is the modern evolution of OCR. It is not a single technology but a comprehensive data extraction pipeline that uses OCR as just one component, augmenting it with advanced AI like machine learning (ML), computer vision, and natural language processing (NLP). IDP moves beyond simple character recognition to achieve true document understanding.
While traditional OCR simply reads, IDP comprehends. It analyzes a document holistically to extract not just the text, but also its context, structure, and meaning.
The core capabilities of an IDP system include:
- Document Classification: Automatically identifying the document type, such as an invoice, contract, or purchase order.
- Smart Data Extraction: Identifying and extracting specific data points like key-value pairs (e.g., “Invoice Number: INV-123”), complex table data, and checkboxes, often without needing pre-defined templates.
- Layout & Structure Analysis: Understanding the document’s visual and logical hierarchy, including headings, paragraphs, lists, and footers.
- Intelligent Character Recognition (ICR): An extension of OCR that leverages AI to accurately recognize and transcribe handwritten text from forms and documents.
The critical difference is the output. IDP delivers clean, structured, and labeled data—typically in a JSON format—that is perfectly suited for AI models and automated workflows. This is the key to making documents truly AI-ready.
Why Modern Workflows Demand Structured Intelligence, Not Just Text
Modern AI pipelines, particularly systems using Retrieval-Augmented Generation (RAG), depend on high-quality, contextual data to function effectively. A raw text dump from OCR lacks the metadata and structure needed for reliable information retrieval and logical reasoning. When an AI model receives unstructured text, it has no way to know if a number is part of a price, a quantity, or a ZIP code.
Structured JSON output from an IDP system preserves these critical relationships. An LLM can understand that a specific line item belongs to a table, which is located on an invoice from a particular vendor. This contextual understanding is impossible with a simple text file.
Relying on basic OCR forces developers into a costly trap: writing and maintaining an army of complex, brittle parsers to try to make sense of the unstructured text. This “data tax” is inefficient, scales poorly, and introduces a significant risk of error. A robust IDP solution eliminates this burden by delivering data that is immediately usable. At Apryse, we give developers the tools to convert unstructured PDFs into clean, labeled JSON, purpose-built for AI agent development and RAG workflows.
Building a Secure IDP Pipeline with the Apryse SDK
Apryse provides a complete document SDK solution that empowers developers to build custom, high-performance IDP capabilities directly into their applications. Instead of a rigid, black-box application, we provide the flexible building blocks to construct a secure pipeline that meets your exact needs, with all processing happening inside your own infrastructure.
Start with High-Fidelity Pre-processing
Reliable data extraction starts with high-quality input. The Apryse OCR engine applies internal image processing during recognition - correcting skew, rotation, and noise at the character and layout level so that the text extracted from scanned image PDFs and images is as accurate as possible before it ever reaches your downstream pipeline. This means you get cleaner output without any modification to your source documents.
Extract Structured Data with AI-Powered Intelligence
With a clean document, you can proceed to extraction. Apryse’s OCR and ICR capabilities are integrated into a powerful, AI-driven extraction engine. Using our SDK, developers can build a full IDP pipeline using Smart Data Extraction to capture:
- Document Classification for categorizing documents
- Key-value pairs without templates
- Complex and nested table data
- Document structure (headings, paragraphs, lists)
- Handwritten text via our ICR engine
Crucially, the Apryse Server SDK runs entirely on-premise or in your private cloud. No external API calls are needed for extraction. Your sensitive data never leaves your environment, ensuring maximum security and compliance for mission-critical workflows.
Validate and Review with Human-in-the-Loop (HITL) Workflows
No automated system is perfect. For workflows requiring 100% accuracy, building a human-in-the-loop (HITL) validation step is an essential risk mitigation strategy. The Apryse WebViewer is a powerful client-side component that allows you to embed a UI directly into your application for this purpose. Developers can use it to create intuitive interfaces where users can visually review, annotate, and correct extracted data, ensuring only verified information is passed to downstream systems or used for AI model training.
Your Toolkit for AI-Ready Document Workflows
The path to effective AI-powered automation starts with the right data. While traditional OCR digitizes text, it falls short of providing the structured intelligence that modern AI document processing requires. IDP bridges this gap by transforming unstructured documents into clean, labeled, and context-rich data.
The Apryse SDK provides a complete developer toolkit to build secure, high-performance IDP pipelines. By giving you control over every step—from pre-processing and extraction to human validation—we empower you to build smarter, easier, and faster document workflows that are truly AI-ready.
Explore the Apryse Document Intelligence Toolkit to see our capabilities in action and start your free trial to build your first AI-ready document pipeline today.



Ready to get started?
Sign up for a free trial to begin implementing the Apryse SDK in your application!