Vimal Cherangattu
Published April 03, 2024
Updated July 03, 2025
3 min
Apryse Smart Data Extraction: Data Extraction Has Never Been This Precise or Powerful
Vimal Cherangattu

Summary: The latest version of Apryse Smart Data Extraction revolutionizes data extraction with advanced AI algorithms, offering precise analysis of complex documents without manual effort. Enhanced features include refined form processing and improved table recognition, benefiting various industries from healthcare to finance. Real-world applications demonstrate significant time savings and error reduction.
Introduction
Documents are the backbone of information management in any organization, but the process of extracting data from them has often been fraught with inefficiencies and inaccuracies. Today, we're excited to share a significant leap forward in how businesses can harness the power of document processing: the launch of Smart Data Extraction.
With this new version, we've expanded beyond the limitations of traditional document extraction to offer a solution that understands the complexities of documents just as a human would – but at scale and without the associated manual effort.
Key Enhancements in Our Latest Smart Data Extraction
- Advanced Data Extraction: Utilizing proprietary AI algorithms, Smart Data Extraction extends beyond mere text recognition to discern and extract tables, forms, and intricate document structures with unparalleled precision.
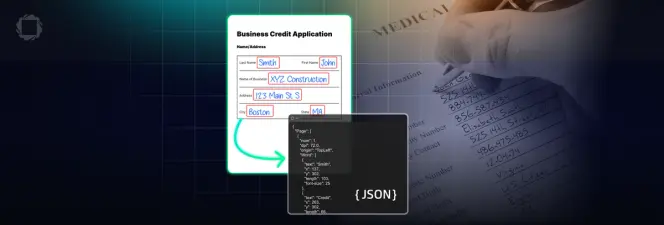
- Refined Form Processing: Smart Data Extraction advances form analysis by identifying labels and content in non-interactive PDFs, such as distinguishing "Name" from "John Doe," and auto-generating interactive elements in static forms. This breakthrough eliminates the need for manual setup, streamlining document workflows significantly.
- Table Recognition and Data Capture: Our enhanced algorithms now allow for a more accurate recognition and extraction of table-based data, offering a clearer insight into the information your documents hold.
Smart Data Extraction is built for innovators and problem-solvers across various roles and industries:
- AI and ML Developers seeking efficient ways to feed high-quality data into their models for smarter, more predictive outcomes.
- Developers and Engineers in need of a robust, low-maintenance solution for document processing across applications, simplifying the transition from paper-based to digital workflows.
- Data Scientists looking for streamlined data extraction to fuel their analysis and insights, turning complex documents into actionable data.
From healthcare to finance, legal to insurance, Smart Data Extraction is not just a tool but a catalyst for innovation and efficiency. Its ability to process complex documents accurately and at scale means that businesses can make faster, more informed decisions; ultimately enhancing their competitive edge.
Smart Data Extraction in Action
Healthcare Records Management
In the healthcare sector, a major provider leveraged Smart Data Extraction to automate patient records and insurance form processing. The precision of Smart Data Extraction in extracting complex data structures led to a drastic reduction in processing times and errors, enhancing patient care and operational efficiency.
Legal Document Analysis
A law firm facing the challenge of reviewing hundreds of legal documents found a solution in Smart Data Extraction. The technology's ability to accurately extract and analyze data from complex documents allowed the firm to significantly cut down on preparation time for cases, ensuring no critical detail was overlooked.
Financial Document Processing
For a financial institution bogged down by the manual extraction of data from diverse documents, Smart Data Extraction proved transformative. Automating the data extraction process resulted in quicker loan processing times and improved customer satisfaction, alongside a reduction in credit decision errors.
As part of the Smart Data Extraction add-on to the Apryse Server SDK, the new form field detector runs efficiently on premises, in your application, instead of consuming costly cloud resources or requiring a third-party app. You own the entire workflow and lock down documents and data in the viewer, which improves security.